前言:随着C#的版本升级,C#编译器的类型推断功能也在不断的升级以适应语言进化过程中的变化,并为这个过程做了相应的优化。
隐式类型的数组
在C#1和C#2中,作为变量声明和初始化的一部分,初始化数组的语句是相当整洁的。如果想在其他地方声明并初始化数组,就必须指定数组类型。例如,下面的语句编译起来没有任何问题:
string[] names = {"pangjainxin", "zhengyanan"};
但这种写法不适用于参数,假定要调用MyMethod方法,该方法被声明为void MyMethod(string[] names),那么以下代码是无法编译的:
MyMethod({"pangjianxin","zhengyanan"});//报错:未提供与方法需要的形参所对应的实参
相反,你必须要告诉编译器你想要初始化的数组是什么类型:
MyMethod(new string[]{"pangjianxin","zhengyanan"});
而C#3允许这两者之间的一种写法:
MyMethod(new[]{"pangjianxin","zhengyanan"});
显然,编译器必须自己判断要使用什么类型的数组。它首先构造一个集合,其中包括大括号内所有表达式的 编译时类型。在这个类型的集合中,如果其他所有类型都能隐式转换为其中一种类型,该类型即为数组的类型。否则(或者所有值都是无类型的表达式,比如不变的null值或者匿名方法,而且不存在强制类型转换), 代码就无法编译。
注意,只有表达式的类型才会成为一个候选的数组类型(也就是说编译器不会为你做类型转换)。这意味着你偶尔需要将一个值显式转型为一个不太具体的类型。例如,以下代码无法编译:
new[]{new MemoryStream(),new StringWriter()}
不存在从MemoryStream向StringWriter的转换,反之亦然。两者都能隐式转换为object和IDisposable,但编译器只能在表达式本身产生的原始集合中过滤(找到那个最适合的)。在这种情况下,如果修改其中的一个 表达式,把它的类型变成object或IDisposable,代码就可以编译了:
new[]{(IDisposable)new MemoryStream(),new StringWriter()}
最终,表达式的类型为IDisposable[]。当然,代码都写成这样了,还不如考虑一下显式声明数组的类型, 就 像在C# 1和C# 2中所做的那样,从而更清楚地表达你的意图。
从以上的过程中来看这个特性好像有一些垃圾,没有什么用,但是该特性用在匿名类型上面的话还是很不错的。由于这里主要描述C#的类型推断,所以关于匿名类型的东西不做太多深入,就给一个例子来表明类型推断在匿名类型中的使用:
var family = new[] { new {name = "pangjianxin", age = 30}, new {name = "zhengyanan", age = 29}, new {name = "pangxihe", age = 1} };
而匿名类型又服务于一个更大的目标:LINQ。
方法组转换
在C#1中,如果要创建一个委托实例,就必须同时指定委托类型和要执行的操作。例如,如果需要创建一个KeyPressEventHandler时,会使用如下表达式:
new KeyPressEventHandler(LogKeyEvent)//LogKeyEvent是一个方法名
作为一个独立的表达式使用时,它并不“难看”。即使在一个简单的事件订阅中使用,它也是能够接受的。但是,在作为某个较长表达式的一部分使用时,看起来就有点“难看”了。一个常见的例子是在启动一个新线程时:
Thread t=new Thread(new ThreadStart(MyMethod));
同往常一样,我们希望以尽量简单的方式启动一个新线程来执行MyMethod。为此,C#2支持从方法组到一个兼容委托类型的隐式转换。方法组(methodgroup)其实就是一个方法名,它可以选择添加一个目标——换言之,和在C#1中创建委托实例使用的表达式完全相同。(事实上,表达式当时就已经叫做“方法组”,只是那时还不支持转换。)如果方法是泛型的,方法组也可以指定类型实参,不过根据我的经验,很少会这么做。新的隐式转换允许我们将事件订阅转换成:
button.keyPress+=LogKeyEvent;//LogKeyEvent是一个方法名
类似的,线程创建代码可以简化成:
Thread t=new Thread(MyMethod);
如果只看一行代码,原始版本和改进的版本在可读性上的差异似乎并不大。但在代码量很大时,它们对可读性的提升就非常明显了。为了弄清楚到底发生了什么,我们简单看看这个转换具体都做了什么。首先研究一下例子中出现的表达式LogKeyEvent和MyMethod。它们之所以被划分为方法组,是因为由于重载,可能不止一个方法适用。隐式转换会将一个方法组转换为具有兼容签名的任意委托类型。所以,假定有以下两个方法签名:
void MyMehtod(); viod MyMethod(object sender,Eventargs e);
那么在向一个ThreadStart或者一个EventHandler赋值时,都可以将MyMethod作为方法组使用:
THreadStart x=MyMehtod;
EventHandler y=MyMethod;
然而,对于本身已重载成可以获取一个ThreadStart或者一个EventHandler的方法,就不能把它(MyMethod)作为方法的参数使用——编译器会报告该转换具有歧义。同样,不能利用隐式方法组转换来转换成普通的System.Delegate类型,因为编译器不知道具体创建哪个委托类型的实例。这确实有点不方便,但使用显式转换,仍然可以写得比在C#1中简短一些。例如:
Delegate invalid=SomeMethod;
Delegate valid=(ThreadStart)SomeMethod;
对于方法组的转换,大多数情况下我们要在自己的实验过程中得出真知,这没有什么困难的。
类型推断和重载决策的改变
类型推断和重载决策所涉及的步骤在C#3中发生了变化,以适应Lambda表达式,并使匿名方法变得更有 用。这些虽然不算是C#的新特性,但在理解编译器所做的事情方面,这些变化是相当重要的。规则之所以发生了变化,是为了使Lambda表达式能够以一种简洁的方式工作,让我们稍微深入地探讨一下假如C#团队坚守老的规则不变,将会遇到什么问题。
改变的起因:精简泛型方法调用
在几种情况下会进行类型推断。通过以前的讨论,我们知道隐式类型的数组以及将方法组转换为委托类型都需要类型推断,但将方法组作为其他方法的参数进行转换时,会显得极其混乱:要调用的方法有多个重载的方法,方法组内的方法也有多个重载方法,而且还可能涉及泛型泛型方法,一大堆可能的转换会使人晕头转向。到目前为止,最常见的类型推断调用方法时不指定任何类型实参。在LINQ里面,这类事情是时刻都在发生的——查询表达式的工作方式严重依赖于此。这个过程被处理得如此顺畅,以至于很容易忽视编译器帮你做的大量工作,而这一切都是为了使你的代码更清晰,更简洁。
随着Lambda表达式的引入,C#3中的情况变得更复杂——如果用一个Lambda表达式来调用一个泛型方法,同时传递一个隐式类型的参数列表,编译器就必须先推断出你想要的是什么类型,然后才能检查Lambda表达式的主体。用实际的代码更容易说明问题。下面的代码清单列出了我们想解决的一类问题:用Lambda表达式调用一个泛型方法。
static void PrintSomeValue<TInput, TOutput>(TInput input, Converter<TInput,TOutput> convert) { Console.WriteLine(convert(input)); }
....
PrintSomeValue("i am a string",x=>x.Length);
PrintSomeValue方法直接获取一个输入的值和委托,将该值转换成不同类型的委托。它未就类型参数TInput和TOutput作出任何假设(没有定义类型参数约束),因此完全是通用的。现在,让我们研究一下在本例中最后一行调用该方法时实参的类型到底是什么。第1个实参明显是字符串,但第2个呢?它是一个Lambda表达式,所以需要把它转换成一个Converter<TInput,TOutput>——而那意味着要知道TInput和TOutput的类型。
C#2的类型推断规则时单独针对每一个实参来进行的,从一个实参推断出的类型无法直接用于另一个实参。在当前这个例子中,这些规则会妨碍我们为第2个实参推断出TInput和TOutput的类型。所以,如果还是沿用C#2的规则,代码清单9-11的代码就会编译失败。本节的最终目标就是让你明白是什么使上述代码清单在C#3中成功通过编译,但让我们先从一些难度适中的内容入手。
推断匿名函数的返回类型
下面的代码清单展示了貌似能编译,但是不符合C#2类型推断规则的示例代码。
delegate T MyFunc<T>(); static void WriteResult<T>(MyFunc<T> function) { Console.WriteLine(function()); } ......... WriteResult(delegate{return 5});
这段代码在C#2中会报错:
error CS04011:The type argument for method ..... can not be inferred from the usage.try specifying the type arguments explicitly.
可以采取两种方式修正这个错误:要么显式指定类型实参(就像编译器推荐的那样),要么将匿名方法强制转换为一个具体的委托类型:
WriteResult<int>(delegate{return 5;}); WriteResult((MyFunc<int>)delegate {return 5;});
这两种方式都可行,但看起来都有点儿令人生厌。我们希望编译器能像对非委托类型所做的那样,执行相同的类型推断,也就是根据返回的表达式的类型来推断T的类型。那正是C#3为匿名方法和Lambda表达式所做的事情——但其中存在一个陷阱。虽然在许多情况下都只涉及一个return语句,但有时会有多个。
下面的代码清单是上面代码稍加修改的一个版本,其中匿名方法有时返回int,有时返回object:
.......... WriteResult(delegate { if (DateTime.Now.Hour < 10) return 5; else return new object(); });
在这种情况下,编译器采用和处理隐式类型的数组时相同的逻辑来确定返回类型,详情可参见上面。它构造一个集合,其中包含了来自匿名函数主体中的return语句的所有类型1(本例是int和object),并检查是否集合中的所有类型都能隐式转换成其中的一个类型。int到object存在一个隐式转换(通过装箱),但object到int就不存在了。所以,object被推断为返回类型。如果没有找到符合条件的类型,或者找到了多个,就无法推断出返回类型,编译器会报错。
我们现在知道了怎样确定匿名函数的返回类型,但是,参数类型可以隐式定义的lambda表达式又如何呢?
分两个阶段进行的类型推断
C#3中的类型推断的细节与C#2中相比,要复杂的多,你可以参考C#语言规范中要求的那样,一步一步的来,在这里,我们要采取一种较为简单明了的方式来思考类型推断--效果和你粗读一遍规范差不多。但这种方式更容易理解。而如果编译器不能完全按照你的意愿进行推断,最后也只是会生成一个错误的提示,而不会编译成错误的结果(程序),所以没什么大不了的。
第一个巨大的改变是所有方法实参在C#3中是一个“团队”整体。在C#2中,每个方法实参都被单独用于尝试确定一些类型参数。针对一个特定的类型参数,如果根据两个方法实参推断出不同的结果,编译器就会报错——即使推断结果是兼容的。但在C#3中,实参可提供一些信息——被强制隐式转换为具体类型参数的最终固定变量的类型。用于推断固定值(下面会提到的一个术语)所采用的逻辑与推断返回类型和隐式类型的数组是一样的。
下面展示一个例子:
static void PrintType<T>(T first, T second) { Console.WriteLine(typeof(T)); } ... PrintType(1,new object());
C#2中,上述代码虽然在语法上是有效的,但不能成功编译:类型推断会失败,因为从第一个实参判断出T应该是int,第二个判断出T肯定是object,两个就冲突了。但是在C#3中,编译器的推断过程已经更加全面,推断返回类型时所采用的规则就是其中一个具有代表性的例子。
第二个改变在于,类型推断现在是分两个阶段进行的。第一个阶段处理的是“普通”的实参,其类型是一开始便知道的。这包括那些参数列表是显式类型的匿名函数。
稍后进行的第二个阶段是推断隐式类型的Lambda表达式和方法组的类型。其思想是,根据我们迄今为止拼凑起来的信息,判断是否足够推断出Lambda表达式(或方法组)的参数类型。如果能,编译器就可以检查Lambda表达式的主体并推断返回类型——这个返回类型通常能帮助我们确定当前正在推断的另一个类型参数。如果第二个阶段提供了更多的信息,就重复执行上述过程,直到我们用光了所有线索,或者最终推断出涉及的所有类型参数。
下面的流程图展示了这一过程,不过这只是该算法简化后的版本。
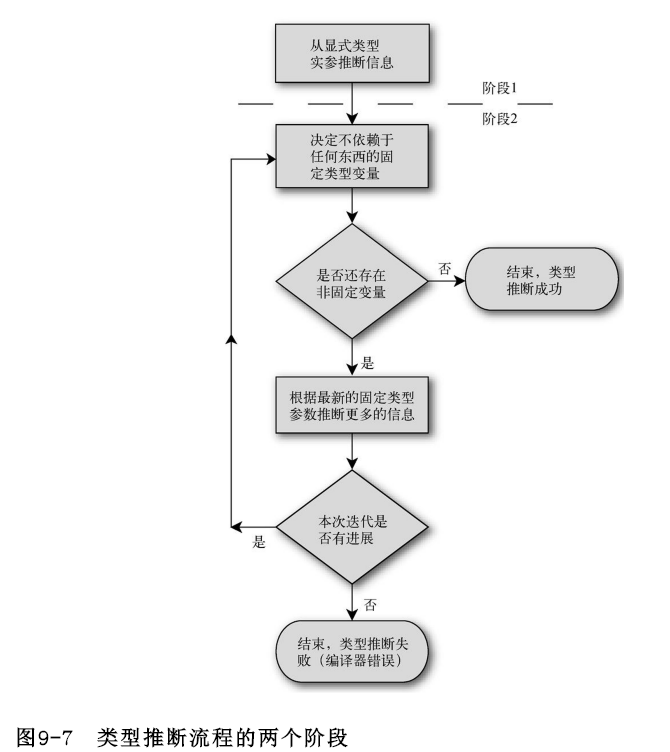
下面用两个例子来展示这个过程。下面使用了上面展示出来的一段代码:
static void PrintSomeValue<TInput, TOutput>(TInput input, Converter<TInput,TOutput> convert) { Console.WriteLine(convert(input)); } .... PrintSomeValue("i am a string",x=>x.Length);
上述代码清单需要推断的类型参数是TInput和TOutput。具体步骤如下。
1、阶段1开始。
2、第1个参数是TInput类型,第1个实参是string类型。我们推断出肯定存在从string到TInput的隐式转换。
3、第2个参数是Converter<TInput,TOutput>类型,第2个实参是一个隐式类型的Lambda表达式。此时不执行任何推断,因为我们没有掌握足够的信息。
4、阶段2开始。
5、TInput不依赖任何非固定的类型参数,所以它被确定为string。
6、第2个实参现在有一个固定的输入类型,但有一个非固定的输出类型。我们可把它视为(stringx)=>x.Length,并推断出其返回类型是int。因此,从int到TOutput必定会发生一个隐式转换。
7、重复“阶段2”。
8、TOutput不依赖任何非固定的类型参数,所以它被确定为int。
9、现在没有非固定的类型参数了,推断成功。
下一个例子更好的展示了重复阶段2的重要性。他执行了两个转换,第一个输出成为第二个的输入。在推断出第一个转换的输出类型之前,我们不知道第二个的输入类型,所以也不能推断出它的输出类型。
public static void ConvertTwice<TInput,TMiddle,TOutput>(TInput input , Converter<TInput,TMiddle> firstConverter, Converter<TMiddle,TOutput> secondConverter) { TMiddle middle = firstConverter(input); TOutput output = secondConverter(middle); Console.WriteLine(output); } ............. ConvertTwice("another string",text=>text.Length,length=>Math.Sqrt(length));
要注意的第一件事是方法签名看起来相当恐怖,但当你不再害怕,并仔细观察它时,发现它也没那么恐怖——当然示范用法使它看上去更直观。我们获取一个字符串,对它执行一次转换:这个转换和之前的转换是相同的,只是一次长度计算。然后,我们获取长度(int),并计算它的平方根(double)。类型推断的“阶段1”告诉编译器肯定存在从string到TInput的一个转换。第一次执行“阶段2”时,TInput固定为string,我们推断肯定存在从int到TMiddle的一个转换。第二次执行“阶段2”时,TMiddle固定为int,我们推断肯定存在从double到TOutput的一个转换。第三次执行“阶段2”时,TOutput固定为doluble,类型推断成功。当类型推断结束后,编译器就可以正确地理解Lambda表达式中的代码。
说明 检查lambda表达式的主体 Lambda表达式的主体只有在输入参数的类型已知之后才能进行检查。如果x是一个数组或者字符串,那么Lambada表达式x=>x.Length就是有效的,但在其他许多情况下它是无效的。当参数类型是显式声明的时候,这并不是一个问题,但对于一个隐式(类型)参数列表,编译器就必须等待,直到他执行了相应的类型推断之后,才能尝试去理解lambda表达式的含义。
这些例子每次只展示了一个改变①——在实际应用中,围绕不同的类型变量可能产生多个方面的信息,这些信息可能是在不同的重复阶段发现的。为了避免你(和我)绞尽脑汁,我决定不再展示任何更复杂的例子了——你只需理解常规的机制就可以了,即使确切的细节可能仍然是模模糊糊的也不要紧。
①所说的“改变”是指本节所描述的C#3与C#2相比,在类型推断上的两个改变,一个改变是方法实参协同确定最后的类型实参,另一个改变是类型推断现在分两个阶段进行。但这些改变并不是孤立的,而是相互联系,共同发挥作用的。但是,作者前面的例子并没有反映出这一点,他的每个例子只是展示了其中的一个改变。
虽然这种情况表面上非常罕见,似乎不值得为其设立如此复杂的规则,但它在C#3中实际是非常普遍的,尤其是对LINQ而言。事实上,在C#3中,你可以在不用思考的情况下大量地使用类型推断——它会成为你的一种习惯。然而,如果推断失败,你就会奇怪为什么。届时,你可以重新参考这里的内容以及语言规范。
还有一个改变需要讨论,但听到下面的话,你会很高兴,这个改变比类型推断简单:方法重载。
选择正确的被重载的方法
如果多个方法的名字相同但签名不同,就会发生重载。有时,具体该用哪个方法是显而易见的,因为只有它的参数数量是正确的,或者只有用它,所有实参才能转换成对应的参数类型。但是,假如多个方法看起来都合适,就比较麻烦了。7.5.3节规范中的具体规则相当复杂--但关键在于每个实参类型转换成参数类型的方式。例如,假定有以下方法签名,似乎他们都是在同一个类中声明的:
void Write(int x); void Write(double y);
Write(1.5)的含义显而易见,因为不存在从double到int的隐式转换,但Write(1)对应的调用就麻烦一些。由于存在从int到double的隐式转换,所以以上两个方法似乎都合适。在这种情况下,编译器会考虑从int到int的转换,以及从int到double的转换。从任何类型“转换成它本身”被认为好于“转换成一个不同的类型”。这个规则称为“更好的转换”规则。所以对于这种特殊的调用,Write(intx)方法被认为好于Write(doubley)。
如果方法有多个参数,编译器需要确保存在最适合的方法。如果一个方法所涉及的所有实参转换都至少与其他方法中相应的转换“一样好”,并且至少有一个转换严格优于其他方法,我们就认为这个方法要比其他方法好。
现给出一个简单的例子,假定现在有以下两个方法签名:
void Write(int x,double y); void Write(double x,int y);
对Write(1,1)的调用会产生歧义,编译器会强迫你至少为其中的一个参数添加强制类型转换,以明确你想调用的是哪个方法。每个重载都有一个更好的实参转换,因此都不是最好的。
同样的逻辑在C#3中仍然适用,但额外添加了与匿名函数(lambda表达式和匿名方法的统称)有关的一个规则(匿名函数永远不会指定一个返回类型)。在这种情况下,推断的返回类型在“更好的转换”规则中使用。
下面来看一个需要新规则的例子。下列代码包含两个名为Execute的方法,另外还有一个使用了Lambda表达式的调用。
static void Execute(Func<int> action) { Console.WriteLine($"action result is an int {action()}"); } static void Execute(Func<double> action) { Console.WriteLine($"action result is a double {action()}"); }
......
Execute(()=>1);
对Execute方法的调用可以换用一个匿名方法来写,也可以换用一个方法组----不管以什么方式,凡是涉及转换,所应用的规则都是一样的。那么,最后会调用哪个Execute方法呢?重载规则指出,在执行了对实参的转换之后,如果发现两个方法都合适,就对那些实参转换进行检查,看哪个转换“更好”。这里的转换并不是从一个普通的.NET类型到参数类型,而是从一个Lambda表达式到两个不同的委托类型。那么,哪个转换“更好”?
令人吃惊的是,同样的情况如果在C#2中发生,那么会导致一个编译错误——因为没有针对这种情况的语言规则。但在C#3中,最后会选中参数为Func<int>的方法。额外添加的规则可以表述如下:如果一个匿名函数能转换成参数列表相同,但返回类型不同的两个委托类型,就根据从“推断的返回类型”到“委托的返回类型”的转换来判定哪个委托转换“更好”。
如果不拿一个例子来作为参考,这段话会绕得你头晕。让我们回头研究一下代码清单:现在是从一个无参数、推断返回类型为int的Lambda表达式转换成Func<int>或Func<double>。两个委托类型的参数列表是相同的(空),所以上述规则是适用的。然后,我们只需判断哪个转换“更好”就可以了:int到int,还是int到double。这样就回到了我们熟悉的问题上——如前所述,int到int的转换更好。因此,代码清单会在屏幕上显示:action result is an int:1。
类型推断和重载决策
这一节说了那么多但是我感觉还是没有很明白的讲清楚,因为这是一个很庞大的主体,它本身就是复杂的。总结一下这一小节的内容吧:
- 匿名函数(匿名方法和Lambda表达式)的返回类型是根据所有return语句的类型来推断的;
- Lambda表达式要想被编译器理解,所有参数的类型必须为已知;
- 类型推断不要求根据不同的(方法)实参推断出的类型参数的类型完全一致,只要推断出来的结果是兼容的就好;
- 类型推断现在分阶段进行,为一个匿名函数推断的返回类型可作为另一个匿名函数的参数类型使用;
- 涉及匿名函数时,为了找出“最好”的重载方法,要将推断的返回类型考虑在内。
asp.net core中的管道注册
上面说了这么多,不把他用于实践中也是不划算的。在asp.net core中的管道注册使用了RequestDelegate这个委托来表示asp.net core中的抽象,但是这个管道拼接的过程又是由一个Func<RequestDelegate,RequestDelegate>来表示的。让我们深究一下。我们先来看一段注册的例子:
代码1:
app.Use(async (context, next) => { if (context.Request.Path == "/foo") { await context.Response.WriteAsync("foo"); } else { await next(); } });
上面代码就是一个使用Use注册asp.net core管道的例子,他接受的参数为一个Func<HttpContext,Func<Task>,Task>的委托。在这个方法的内部它是调用另一个Use方法来实现的:
代码2:
public static IApplicationBuilder Use(this IApplicationBuilder app, Func<HttpContext, Func<Task>, Task> middleware) { return app.Use((Func<RequestDelegate, RequestDelegate>) (next => (RequestDelegate) (context => { Func<Task> func = (Func<Task>) (() => next(context)); return middleware(context, func); }))); }
代码1中Use方法实现如代码2所示,在调用代码1中的Use方法时,传入了一个代表Func<HttpContext,Func<Task>,Task>委托的middleware变量,而在代码2表示的Use方法内部,又调用了另一个Use方法,这个Use方法接收一个Func<RequestDelegate, RequestDelegate> 委托类型的参数,并最终将这个委托添加到IApplicationBuilder实现类的一个列表上去。代码2中的context是根据Use方法传入的Func<RequestDeleagte,RequestDelegate>类型的第二个类型参数推断出来的。