Evernote Export
数据分析师 Level 1
数据分析概述
数据分析和数据挖掘的概念
-
数据分析(Data Analysis)
是以数据为分析对象,以探索数据内的有用信息为主要途径,以解决业务需求为最终目标,包含业务理解、数据采集、数据清洗、数据探索、数据可视化、数据建模、模型结果可视化、分析结果的业务应用等步骤在内的一整套分析流程
-
数据挖掘(Data Mining)
是一个跨学科的计算机科学分支,它是用人工智能、机器学习、统计学和数据源的交叉方法在相对较大型的数据集中发现模式的计算过程
-
数据分析的八个层次
- 数据分析的目的:发现有价值的信息、提出结论、为业务发展提供辅助决策。它描述了“过去发生了什么”、“现在正在发生什么”和“未来可能发生什么”。根据分析层次的级别不同,分为常规报表、即席查询、多维分析(又称钻取或OLAP)、警报、统计分析、预报(或者时间序列预测)、预测模型(Predictive Model)和优化
常用报表-->即席查询-->多维分析-->警报-->统计分析-->预报-->预测型模型-->优化
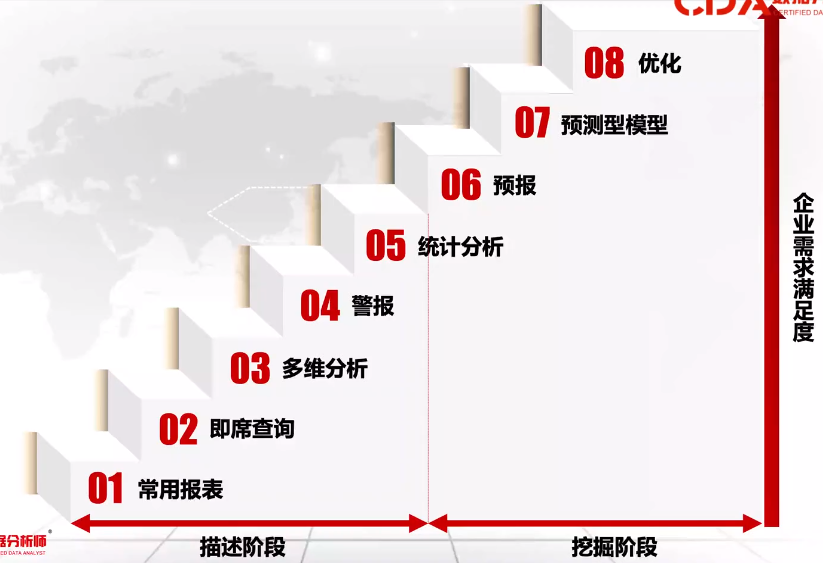
多维就是数据表中的每一列(数据的属性)
大数据对传统小数据的扩展及其区别和联系
- 数据上:**小数据重抽样,大数据重全体。**由于传统小数据分析的本质是基于样本推断总体,因此在分析过程中十分注重抽样的科学性。只有抽样是科学的,其推断结果才具有科学意义。而大数据虽然不一定是总体,但由于在建模方法上已经更偏向于机器学习,因此抽样已经不是必要的手段和方法论了。
- 方法上:**小数据重实证,大数据重优化。**传统的小数据在方法上更重视实证研究,强调在相关理论的前提下建立假设,收集数据,建立模型并验证假设。而大数据往往更重视方法论中的自我迭代和自我优化过程,可能运算的第一个结果与标注答案相差甚远,但是可以通过与正确答案的不断校准(往往建立损失函数),使得模型的精度不断提高
- 目标上:**小数据重解释,大数据重预测。**小数据的分析往往注重归因分析,探索变量之间的内部影响机理,例如究竟什么样的生活习惯会提高癌症的发病率。但是大数据往往关心的是对于未知对象的预测,例如判别某个人是否患有癌症,或者患有癌症的概率是多少。
数据分析目标的意义、过程及其本质
可以认为数据分析涉及到公司运营的方方面面,这包括对企业部门经营情况的评估、内部员工的管理、生产流程的监管、产品结构优化与新产品开发、财务成本优化、市场结构的分析和客户关系的管理。其中,关于客户和市场的数据分析是“重头戏”。下面是以客户全生命周期为例解释数据分析运用场景和挖掘主题,如下图所示
潜在客户-->响应客户-->既得客户-->流失客户

数据挖掘方法论
CRISP-DM 方法论
CRISP-DM方法论将数据挖掘项目生命周期分为6个阶段,它们分别是业务理解、数据理解、数据准备、建模、模型评估和模型发布,如下如所示

-
业务理解(Business Understanding)
- 该初始阶段集中在从商业角度理解项目的目标和要求,通过理论分子转化为数据挖掘可操作的问题,指定实现目标的初步计划
-
数据理解(Data Understanding)
- 数据理解阶段开始于原始数据的收集,然后是熟悉数据、标明数据质量问题、探索对数据的初步理解、发掘有趣的子集以形成对探索关系的假设
-
数据准备(Data Preparation)
- 数据准备阶段包括所有从原始的、未加工的数据构造数据挖掘所需的信息活动。数据准备任务可能被实施多次,而且没有任何规定的顺序。这些任务的主要目的是从源系统根据维度分析的要求,获取所需要的信息,需要对数据进行转换和清洗。
-
建模(Modeling)
- 在此阶段,主要是选择和应用各种建模技术,同时对它们的参数进行校准,以达到最优值。通常对一个数据挖掘问题类型,会有多种建模技术。一些技术对数据格式有特殊的要求,因此,常常需要返回到数据准备阶段。
-
模型评估(Evaluation)
- 在模型最后发布前,根据商业目标评估模型和检查建立模型的各个步骤。此阶段关键目的是,判断是否存在一些重要的商业问题仍未得到充分考虑
-
模型发布(Deployment)
- 模型完成后,由模型使用者(客户)根据当时背景和目标完成情况,决定如何在现场使用模型,比如在网页的实时个人化中或营销数据的重复评分中。
SEMMA 方法论
SAS公司的数据挖掘项目实施方法论,对CRISP-DM方法中的数据准备和建模环节进行了扩展,被称为SEMMA方法论,如下图所示
SEMMA方法论对数据挖掘的过程进行了细化,细化为探索、修改、建模、评估、抽样


-
探索
- 单变量探索为修改提供指导
- 双变量探索发现关系
-
修改
- 异常点和缺失值补缺
- 分类型变量采用基于分布方法
- 区间型变量采用 Andre‘s Wave
- 关键变量进行范式化,考虑偏度峰度便于建模
-
建模
- 神经网络
- 逻辑回归
- CHAID式决策是
-
评估
- 通过验证集进行结果评估
- 发现神经网络进行流失预测最精准
-
抽样
- 数据分成训练集和测试集
- 由于目标变量取值过少,采取过采样(Over-sample)技术,使得流失率到5%
-
数据整理
- 涉及数据采集、数据合并与抽样的操作,目的是为了构造分析用到的数据。分析人员根据维度分析获得的结果作为整理数据的依据,将散落在公司内部与外部的数据进行整合
-
样本探索
- 这个步骤的主要任务是对数据质量的探索。变量质量方面涉及错误值(如年龄=-30)、恰当性(客户的某些业务指标为缺失值,实际上是没有这个业务,值应该为0)、缺失值(没有客户信息)、一致性(收入单位为人民币,而支出为美元)、平稳性(某些数据的均值变化过于剧烈)、重复值(相同的交易被记录两次)和及时性(银行客户的财务数据更新的滞后时长)等方面。这部分的探索主要解决变量是错误时是否可以修改,是否也可以使用的问题。
-
变量修改
- 根据变量探索的结论,需要对数据质量问题和变量分布情况分别做变量修改。数据质量问题的修改涉及改正错误编码、缺失值填补,单位统一等操作。变量分布情况的修改涉及函数转换和标准化方法,具体的修改方法需要与后续的统计建模方法相结合
-
建模
- 根据分析的目的选取合适的模型,这部分内容在“数据分析方法分类介绍”做详细阐述
-
模型检验
- 这里指模型的样本验证,及时用历史数据对模型表现得优劣进行评估。比如,对有监督学习会使用ROC曲线和提升度等技术指标评估模型的预测能力。
数据分析中不同人员的角色与职责
业务问题是需求,最终需要转换成统计或数据挖掘等问题,用数据分析的思路来解决,因此数据分析师在业务与数据间起到协调作用,是业务问题能否成功转换成统计问题的关键。通常来说,业务问题需要一个或多个字段来表达,这些字段以什么形式出现(如测量级别),因为字段的形式会决定选择的方法,而每种方法又用于解决特定的需求,此外由于模型对业务人员或企业高管来说可能过于专业,因此需要将模型输出通俗的表达出来。所以协调者、数据分析师、报告人的角色,决定了数据分析师是一名(精通数理和软件的)综合型人才
例题精讲
1.公司营销部门每月例会报告的经营指标汇总,属于下列哪一类数据分析?
A.客户行为的数据挖掘报告
B.描述性数据分析报告
C.产品和行为倾向报告
D.以上都不对
答案:B
解析:按照惯例经营指标汇总,通常是报告业绩指标的数量、金额、百分比或排名等信息,这类分析多数归属于描述性数据分析,而且是单变量分析的内容。AC项涉及行为特点和商品特征的关系,属于多变量分析的内容。
2.以下哪些内容包含在数据分析层次级别中?
A.即席查询
B.多维分析(又称钻取或者OLAP)
C.统计分析与警报
D.与业务人员协商知识点
答案:ABC
解析:考察数据分析的八个层次,需要在理解的基础上记忆
3.统计模型主要用户解决哪几类问题?
A.预测分类问题
B.OLAP分析问题
C.相关分析
D.市场细分问题
答案:ACD
解析:OLAP分析问题是架构问题,不是统计模型
Queston:统计模型到底包含了哪些内容?统计模型的含义?
统计模型[stochasticmodel;statisticmodel;probabilitymodel]指以概率论为基础,采用数学统计方法建立的模型。有些过程无法用理论分析方法导出其模型,但可通过试验测定数据,经过数理统计法求得各变量之间的函数关系,称为统计模型。常用的数理统计分析方法有最大事后概率估算法、最大似然率辨识法等。常用的统计模型有一般线性模型、广义线性模型和混合模型。统计模型的意义在对大量随机事件的规律性做推断时仍然具有统计性,因而称为统计推断。
4.下列关于数据挖掘流程表达正确的一项是
A.方法论CRISP-DM与SEMMA是业内公认的权威流程,严格按照步骤做数据分析总不会出错的
B.CRISP-DM(译为“跨行业”数据挖掘)在任何数据分析行业中均适用
C.SEMMA方法论是对CRISP-DM方法中的数据准备和建模环节进行了扩展
D.由于数据比较整洁,所以可以不需要再做数据预处理,直接从建模开始
答案:C
解析:AB两项都犯同一类错误,就是过于迷信方法论的权威性,D项中数据分析的一般性描述是很重要的预分析过程,不仅如此,模型对于数据的要求也很高,样本探索、变量整理的那个预处理工作都不可省去
5.关于客户生命周期管理,下列哪一项不属于对既有高价值客户的分析内容?
A.行为信用评分
B.初始信用评分
C.产品精准营销
D.客户留存管理
答案:B
解析:高价值客户属于企业的既有客户,而初始信用评分属于对潜在响应客户的策略分析