作者|Marcelo Rovai
编译|VK
来源|Towards Data Science
介绍
正如Zhe Cao在其2017年的论文中所述,实时多人二维姿势估计对于机器理解图像和视频中的人至关重要。

然而,什么是姿势估计
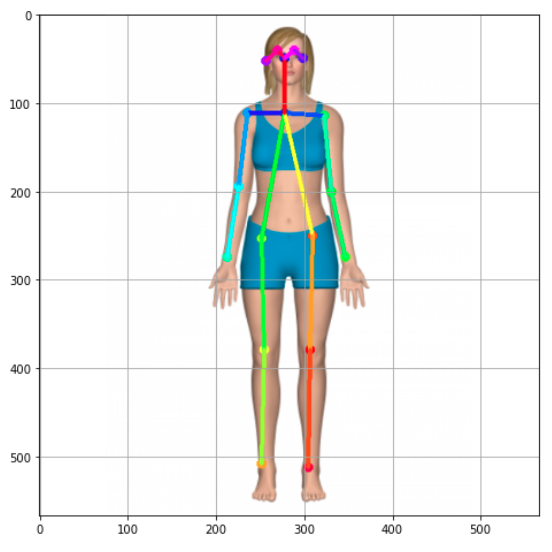
顾名思义,它是一种用来估计一个人身体位置的技术,比如站着、坐着或躺下。获得这一估计值的一种方法是找到18个“身体关节”或人工智能领域中命名的“关键点(Key Points)”。下面的图像显示了我们的目标,即在图像中找到这些点:
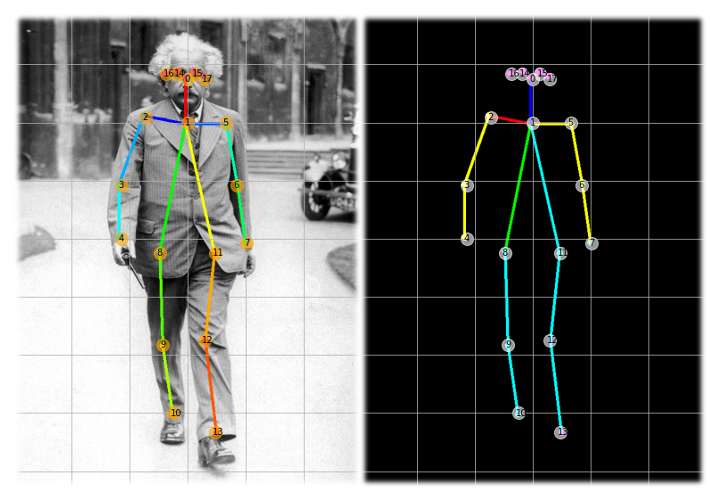
关键点从0点(上颈部)向下延伸到身体关节,然后回到头部,最后是第17点(右耳)。
使用人工智能方法出现的第一个有意义的工作是DeepPose,2014年由谷歌的Toshev和Zegedy撰写的论文。提出了一种基于深度神经网络(DNNs)的人体姿势估计方法,该方法将人体姿势估计归结为一个基于DNN的人体关节回归问题。
该模型由一个AlexNet后端(7层)和一个额外的目标层,输出2k个关节坐标。这种方法的一个重要问题是,首先,模型应用程序必须检测到一个人(经典的对象检测)。因此,在图像上发现的每个人体必须分开处理,这大大增加了处理图像的时间。
这种方法被称为“自上而下”,因为首先要找到身体,然后从中找到与其相关联的关节。
姿势估计的挑战
姿势估计有几个问题,如:
-
每个图像可能包含未知数量的人,这些人可以出现在任何位置或比例。
-
人与人之间的相互作用会导致复杂的空间干扰,这是由于接触或肢体关节连接,使得关节的关联变得困难。
-
运行时的复杂性往往随着图像中的人数而增加,这使得实时性能成为一个挑战。
为了解决这些问题,一种更令人兴奋的方法是OpenPose,这是2016年由卡内基梅隆大学机器人研究所的ZheCao和他的同事们引入的。
OpenPose
OpenPose提出的方法使用一个非参数表示,称为部分亲和力场(PAFs)来“连接”图像上的每个身体关节,将它们与个人联系起来。
换句话说,OpenPose与DeepPose相反,首先在图像上找到所有关节,然后“向上”搜索最有可能包含该关节的身体,而不使用检测人的检测器(“自下而上”方法)。OpenPose可以找到图像上的关键点,而不管图像上有多少人。下面的图片是从ILSVRC和COCO研讨会2016上的OpenPose演示中检索到的,它让我们了解了这个过程。

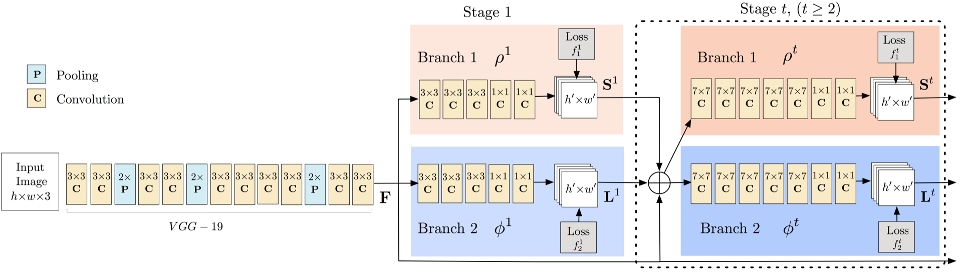
下图显示了用于训练的两个多阶段CNN模型的结构。首先,前馈网络同时预测一组人体部位位置的二维置信度映射(关键点标注来自(dataset/COCO/annotations/)和一组二维的部分亲和力场(L)。
在每一个阶段之后,两个分支的预测以及图像特征被连接到下一个阶段。最后,利用贪婪的推理对置信图和相似域进行解析,输出图像中所有人的二维关键点。
在项目执行过程中,我们将回到其中一些概念进行澄清。但是,强烈建议你遵循2016年的OpenPose ILSVRC和COCO研讨会演示(http://image-net.org/challenges/talks/2016/Multi-person pose estimation-CMU.pdf)和CVPR 2017的视频录制(https://www.youtube.com/watch?v=OgQLDEAjAZ8&list=PLvsYSxrlO0Cl4J_fgMhj2ElVmGR5UWKpB),以便更好地理解。
TensorFlow 2 OpenPose (tf-pose-estimation)
最初的OpenPose是使用基于模型的VGG预训练网络和Caffe框架开发的。但是,我们将遵循Ildoo Kim 的TensorFlow实现,详细介绍了他的tf-pose-estimation。
Github链接:https://github.com/ildoonet/tf-pose-estimation
什么是tf-pose-estimation?
tf-pose-estimation是一种“Openpose”算法,它是利用Tensorflow实现的。它还提供了几个变体,这些变体对网络结构进行了一些更改,以便在CPU或低功耗嵌入式设备上进行实时处理。
tf-pose-estimation的GitHub页面展示了几种不同模型的实验,如:
- cmu:原论文中描述的基于模型的VGG预训练网络的权值是Caffe格式,将其转换并用于TensorFlow。
- dsconv:除了mobilenet的深度可分离卷积之外,与cmu版本的架构相同。
- mobilenet:基于mobilenet V1论文,使用12个卷积层作为特征提取层。
- mobilenet v2:与mobilenet相似,但使用了它的改进版本。
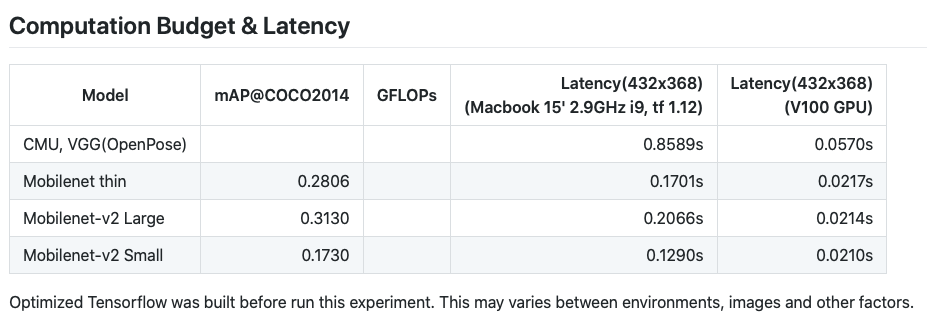
本文的研究是在mobilenet V1(“mobilenet_thin”)上进行的,它在计算预算和延迟方面具有中等性能:
第1部分-安装 tf-pose-estimation
我们参考了Gunjan Seth的文章Pose Estimation with TensorFlow 2.0(https://medium.com/@gsethi2409/pose-estimation-with-tensorflow-2-0-a51162c095ba)。
- 转到终端并创建一个工作目录(例如,“Pose_Estimation”),并移动到那里:
mkdir Pose_Estimation
cd Pose_Estimation
- 创建虚拟环境(例如,Tf2_Py37)
conda create --name Tf2_Py37 python=3.7.6 -y
conda activate Tf2_Py37
- 安装TF2
pip install --upgrade pip
pip install tensorflow
- 安装开发期间要使用的基本软件包:
conda install -c anaconda numpy
conda install -c conda-forge matplotlib
conda install -c conda-forge opencv
- 下载tf-pose-estimation:
git clone https://github.com/gsethi2409/tf-pose-estimation.git
- 转到tf-pose-estimation文件夹并安装requirements
cd tf-pose-estimation/
pip install -r requirements.txt
在下一步,安装SWIG,一个接口编译器,用C语言和C++编写的程序连接到Python等脚本语言。它通过在C/C++头文件中找到的声明来工作,并使用它们生成脚本语言需要访问底层C/C++代码的包装代码。
conda install swig
- 使用SWIG,构建C++库进行后处理。
cd tf_pose/pafprocess
swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace
- 现在,安装tf-slim库,一个用于定义、训练和评估TensorFlow中复杂模型的轻量级库。
pip install git+https://github.com/adrianc-a/tf-slim.git@remove_contrib
就这样!现在,有必要进行一次快速测试。返回tf-pose-estimation主目录。
如果你按照顺序,你必须在 tf_pose/pafprocess内。否则,请使用适当的命令更改目录。
cd ../..
在tf-pose-estimation目录中有一个python脚本 run.py,让我们运行它,参数如下:
-
model=mobilenet_thin
-
resize=432x368(预处理时图像的大小)
-
image=./images/ski.jpg(图像目录内的示例图像)
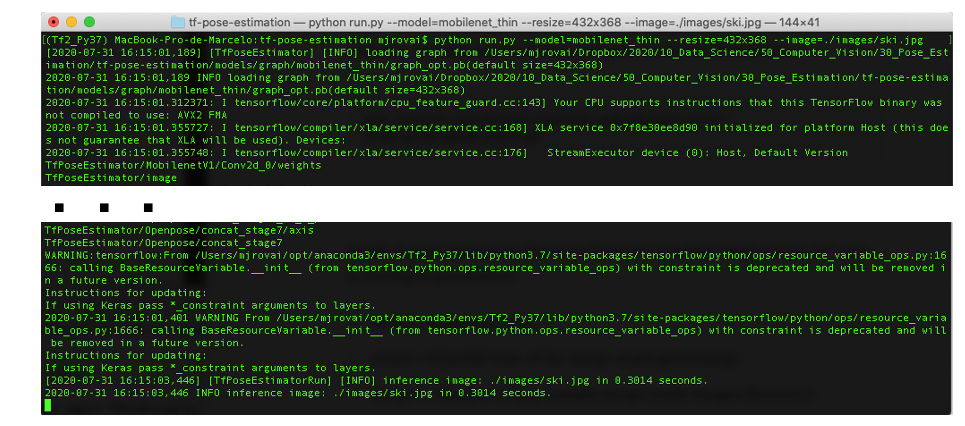
python run.py --model=mobilenet_thin --resize=432x368 --image=./images/ski.jpg
请注意,在几秒钟内,不会发生任何事情,但大约一分钟后,终端应显示与下图类似的内容:
但是,更重要的是,图像将出现在独立的OpenCV窗口上:
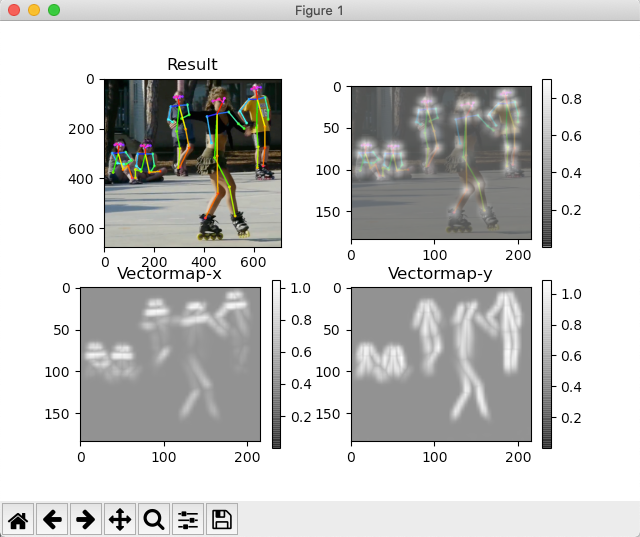
太好了!这些图片证明了一切都是正确安装和运作良好的!我们将在下一节中详细介绍。
然而,为了快速解释这四幅图像的含义,左上角(“Result”)是绘制有原始图像的姿势检测骨架(在本例中,ski.jpg)作为背景。右上角的图像是一个“热图”,其中显示了“检测到的组件”(S),两个底部图像都显示了组件的关联(L)。“Result”是把S和L连接起来。
下一个测试是现场视频:
如果计算机只安装了一个摄像头,请使用:camera=0
python run_webcam.py --model=mobilenet_thin --resize=432x368 --camera=1
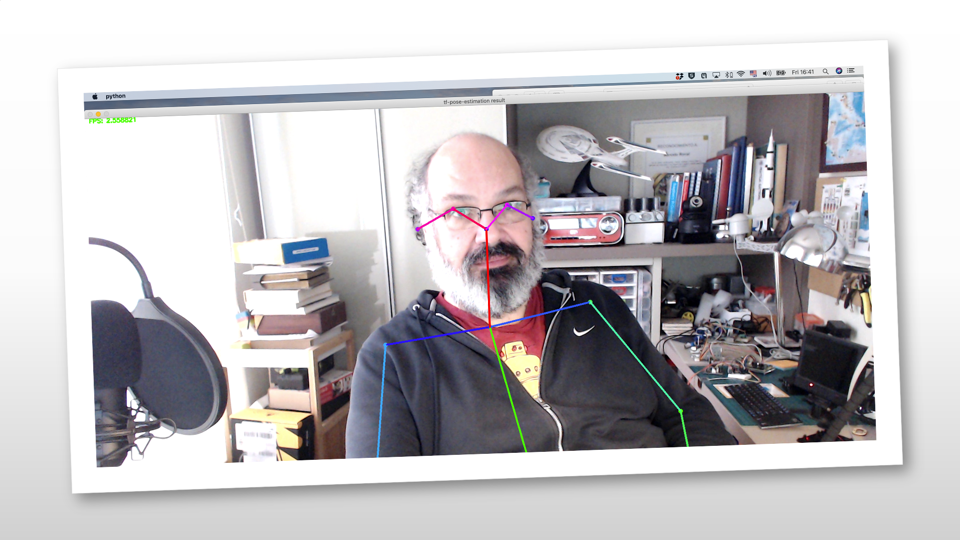
如果一切顺利,就会出现一个窗口,里面有一段真实的视频,就像下面的截图:
第2部分-深入研究图像中的姿势估计
在本节中,我们将更深入地介绍我们的TensorFlow姿势估计实现。建议你按照这篇文章,试着复制Jupyter Notebook:10_Pose_Estimation_Images,可以从GitHub项目下载:https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/10_Pose_Estimation_Images.ipynb
作为参考,这个项目是在MacPro(2.9Hhz Quad-Core i7 16GB 2133Mhz RAM)上开发的。
导入库
import sys
import time
import logging
import numpy as np
import matplotlib.pyplot as plt
import cv2
from tf_pose import common
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
模型定义和TfPose Estimator创建
可以使用位于model/graph子目录中的模型,如mobilenet_v2_large或cmu(VGG pretrained model)。
对于cmu,*.pb文件在安装期间没有下载,因为它们很大。要使用它,请运行位于/cmu子目录中的bash脚本download.sh。
这个项目使用mobilenet_thin(MobilenetV1),考虑到所有使用的图像都应该被调整为432x368。
参数:
model='mobilenet_thin'
resize='432x368'
w, h = model_wh(resize)
创建估计器:
e = TfPoseEstimator(get_graph_path(model), target_size=(w, h))
为了便于分析,让我们加载一个简单的人体图像。OpenCV用于读取图像。图像存储为RGB,但在内部,OpenCV与BGR一起工作。使用OpenCV显示图像没有问题,因为在特定窗口上显示图像之前,它将从BGR转换为RGB(如所示ski.jpg上一节)。
一旦图像被打印到Jupyter单元上,Matplotlib将被用来代替OpenCV。因此,在显示之前,需要对图像进行转换,如下所示:
image_path = ‘./images/human.png’
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image)
plt.grid();

请注意,此图像的形状为567x567。OpenCV读取图像时,自动将其转换为数组,其中每个值从0到255,其中0表示“白色”,255表示“黑色”。

一旦图像是一个数组,就很容易使用shape验证其大小:
image.shape
结果将是(567567,3),其中形状是(宽度、高度、颜色通道)。
尽管可以使用OpenCV读取图像,但我们将使用tf_pose.common库中的函数read_imgfile(image_path) 以防止颜色通道出现任何问题。
image = common.read_imgfile(image_path, None, None)
一旦我们将图像作为一个数组,我们就可以将方法推理应用到估计器(estimator, e)中,将图像数组作为输入
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=4.0)
运行上述命令后,让我们检查数组e.heatmap。该阵列的形状为(184,216,19),其中184为h/2,216为w/2,19与特定像素属于18个关节(0到17)+1(18:none)中的一个的概率有关。例如,检查左上角像素时,应出现“none”:
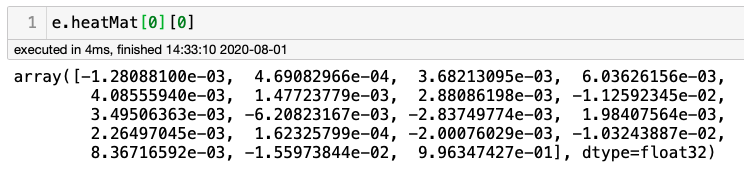
可以验证此数组的最后一个值
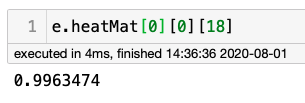
这是最大的值;可以理解的是,在99.6%的概率下,这个像素不属于18个关节中的任何一个。
让我们试着找出颈部的底部(肩膀之间的中点)。它位于原始图片的中间宽度(0.5*w=108)和高度的20%左右,从上/下(0.2*h=37)开始。所以,让我们检查一下这个特定的像素:
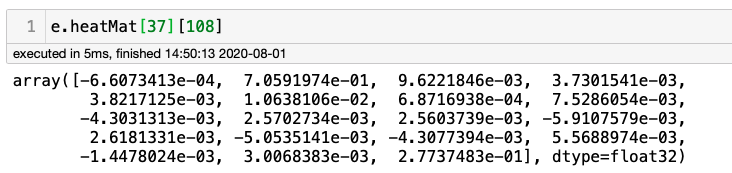
很容易意识到位置1的最大值为0.7059…(或通过计算e.heatMat[37][108].max()),这意味着特定像素有70%的概率成为“颈部”。下图显示了所有18个COCO关键点(或“身体关节”),显示“1”对应于“颈部底部”。
可以为每个像素绘制,一种代表其最大值的颜色。这样一来,一张显示关键点的热图就会神奇地出现:
max_prob = np.amax(e.heatMat[:, :, :-1], axis=2)
plt.imshow(max_prob)
plt.grid();

我们现在在调整后的原始图像上绘制关键点:
plt.figure(figsize=(15,8))
bgimg = cv2.cvtColor(image.astype(np.uint8), cv2.COLOR_BGR2RGB)
bgimg = cv2.resize(bgimg, (e.heatMat.shape[1], e.heatMat.shape[0]), interpolation=cv2.INTER_AREA)
plt.imshow(bgimg, alpha=0.5)
plt.imshow(max_prob, alpha=0.5)
plt.colorbar()
plt.grid();
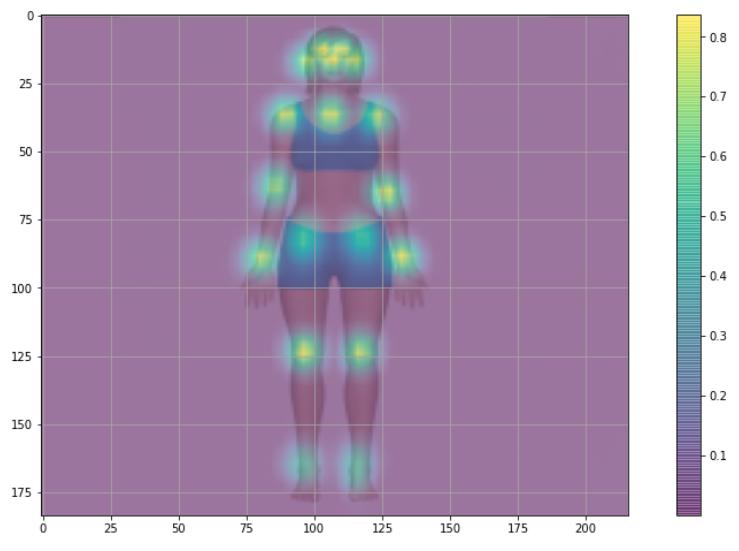
因此,可以在图像上看到关键点,因为color bar上显示的值意味着:如果黄色更深就有更高的概率。
为了得到L,即关键点(或“关节”)之间最可能的连接(或“骨骼”),我们可以使用e.pafMat的结果数组。其形状为(184,216,38),其中38(2x19)与该像素与18个特定关节+none中的一个作为水平(x)或垂直(y)连接的一部分的概率有关。
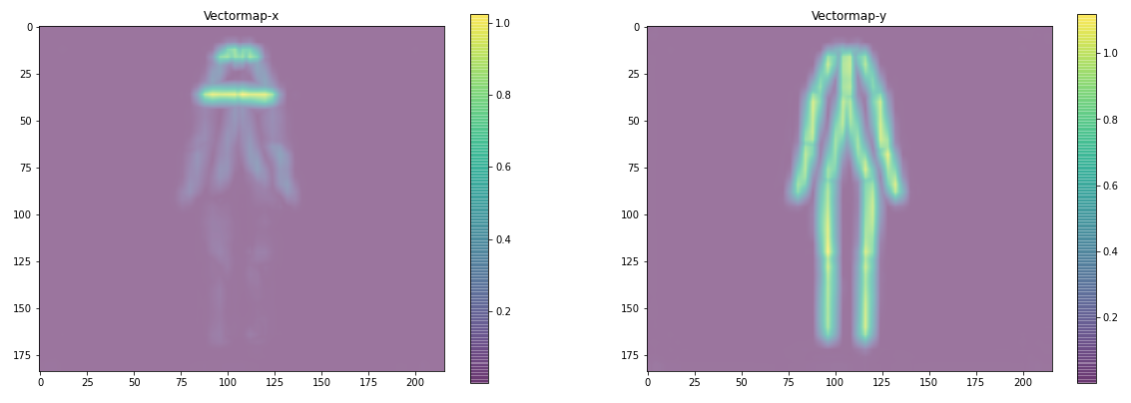
绘制上述图表的函数在Notebook中。
使用draw_human方法绘制骨骼
使用e.inference()方法的结果传递给列表human,可以使用draw_human方法绘制骨架:
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
结果如下图:
如果需要的话,可以只绘制骨架,如下所示(让我们重新运行所有代码进行回顾):
image = common.read_imgfile(image_path, None, None)
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=4.0)
black_background = np.zeros(image.shape)
skeleton = TfPoseEstimator.draw_humans(black_background, humans, imgcopy=False)
plt.figure(figsize=(15,8))
plt.imshow(skeleton);
plt.grid();
plt.axis(‘off’);

获取关键点(关节)坐标
姿势估计可用于机器人、游戏或医学等一系列应用。为此,从图像中获取物理关键点坐标以供其他应用程序使用可能很有趣。
查看e.inference()生成的human列表,可以验证它是一个包含单个元素、字符串的列表。在这个字符串中,每个关键点都以其相对坐标和相关概率出现。例如,对于目前使用的人像,我们有:

例如:
BodyPart:0-(0.49, 0.09) score=0.79
BodyPart:1-(0.49, 0.20) score=0.75
...
BodyPart:17-(0.53, 0.09) score=0.73
我们可以从该列表中提取一个数组(大小为18),其中包含与原始图像形状相关的实际坐标:
keypoints = str(str(str(humans[0]).split('BodyPart:')[1:]).split('-')).split(' score=')
keypts_array = np.array(keypoints_list)
keypts_array = keypts_array*(image.shape[1],image.shape[0])
keypts_array = keypts_array.astype(int)
让我们在原始图像上绘制这个数组(数组的索引是 key point)。结果如下:
plt.figure(figsize=(10,10))
plt.axis([0, image.shape[1], 0, image.shape[0]])
plt.scatter(*zip(*keypts_array), s=200, color='orange', alpha=0.6)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(img)
ax=plt.gca()
ax.set_ylim(ax.get_ylim()[::-1])
ax.xaxis.tick_top()
plt.grid();
for i, txt in enumerate(keypts_array):
ax.annotate(i, (keypts_array[i][0]-5, keypts_array[i][1]+5)

创建函数以快速复制对通用图像的研究:
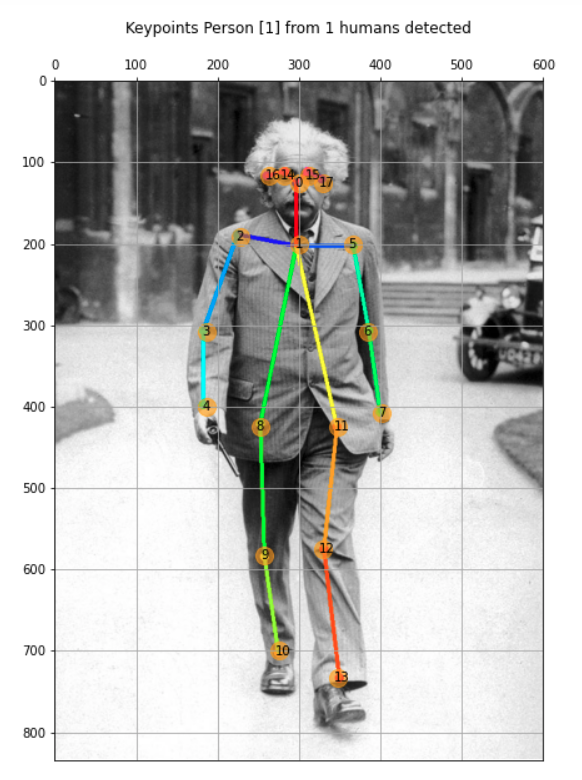
Notebook显示了迄今为止开发的所有代码,“encapsulated”为函数。例如,让我们看看另一幅图像:
image_path = '../images/einstein_oxford.jpg'
img, hum = get_human_pose(image_path)
keypoints = show_keypoints(img, hum, color='orange')
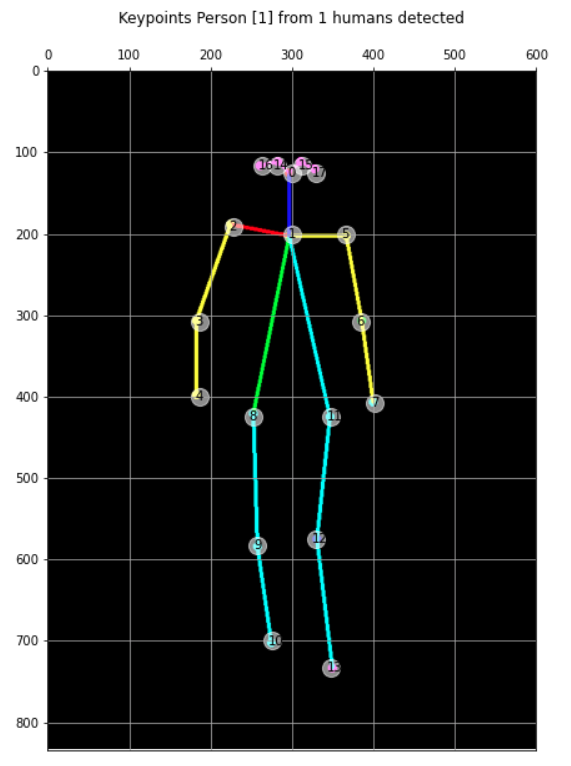
img, hum = get_human_pose(image_path, showBG=False)
keypoints = show_keypoints(img, hum, color='white', showBG=False)
多人图像
到目前为止,只研究了包含一个人的图像。一旦开发出从图像中同时捕捉所有关节(S)和PAF(L)的算法,为了简单起见我们找到最可能的连接。因此,获取结果的代码是相同的;例如,只有当我们得到结果(“human”)时,列表的大小将与图像中的人数相匹配。
例如,让我们使用一个有五个人的图像:
image_path = './images/ski.jpg'
img, hum = get_human_pose(image_path)
plot_img(img, axis=False)

算法发现所有的S和L都与这5个人联系在一起。结果很好!
从读取图像路径到绘制结果,所有过程都不到0.5秒,与图像中发现的人数无关。
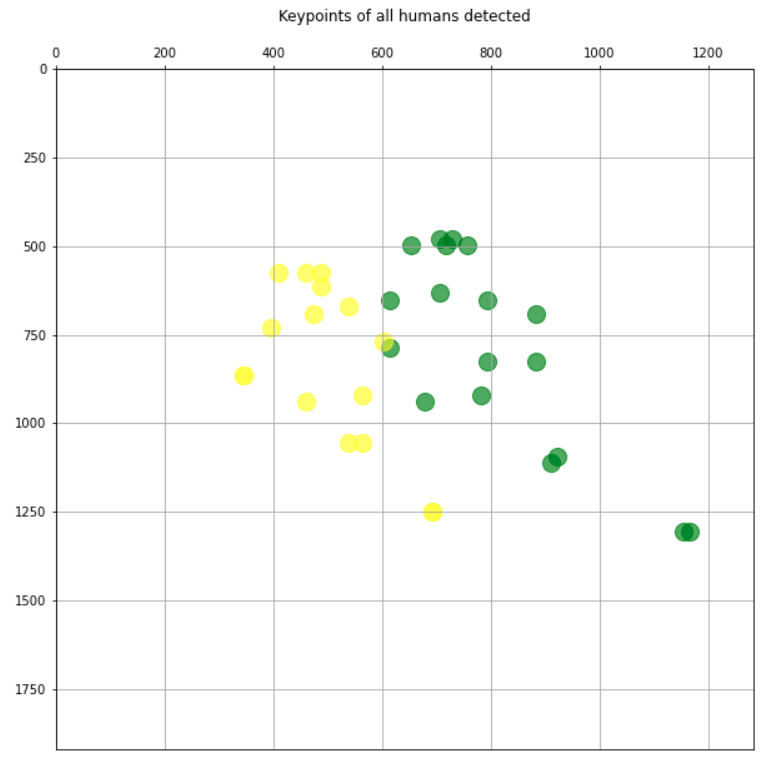
让我们把它复杂化,让我们看到一个画面,人们更“混合”地在一起跳舞:
image_path = '../images/figure-836178_1920.jpg
img, hum = get_human_pose(image_path)
plot_img(img, axis=False)

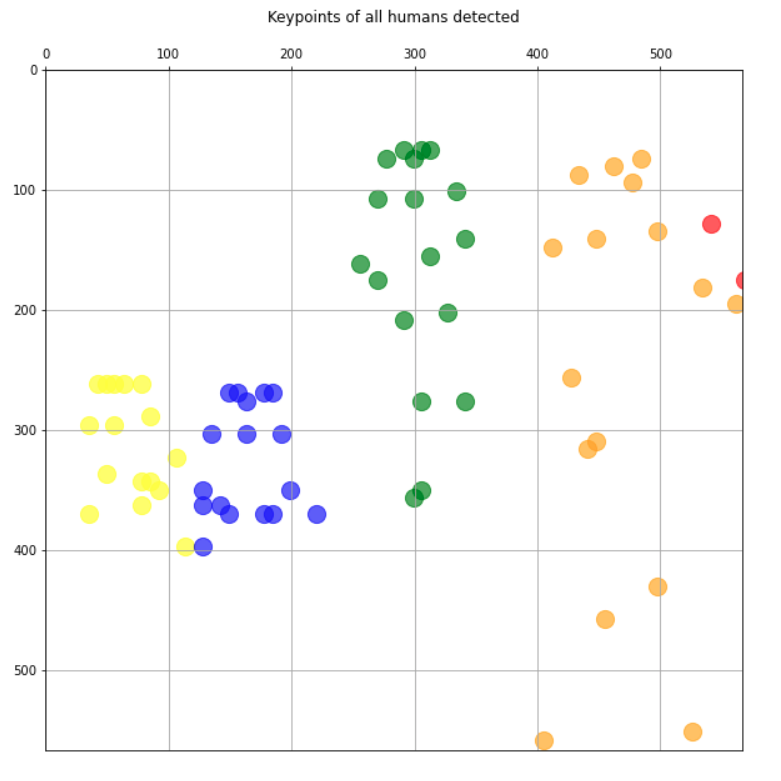
结果似乎也很好。我们只绘制关键点,每个人都有不同的颜色:
plt.figure(figsize=(10,10))
plt.axis([0, img.shape[1], 0, img.shape[0]])
plt.scatter(*zip(*keypoints_1), s=200, color='green', alpha=0.6)
plt.scatter(*zip(*keypoints_2), s=200, color='yellow', alpha=0.6)
ax=plt.gca()
ax.set_ylim(ax.get_ylim()[::-1])
ax.xaxis.tick_top()
plt.title('Keypoints of all humans detected
')
plt.grid();
第三部分:视频和实时摄像机中的姿势估计
在视频中获取姿势估计的过程与我们对图像的处理相同,因为视频可以被视为一系列图像(帧)。建议你按照本节内容,尝试复制Jupyter Notebook:20_Pose_Estimation_Video:https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/20_Pose_Estimation_Video.ipynb。
OpenCV在处理视频方面做得非常出色。
因此,让我们获取一个.mp4视频,并使用OpenCV捕获其帧:
video_path = '../videos/dance.mp4
cap = cv2.VideoCapture(video_path)
现在让我们创建一个循环来捕获每一帧。有了这个框架,我们将应用e.inference(),然后根据结果绘制骨架,就像我们对图像所做的那样。最后还包括了一个代码,当按下一个键(例如“q”)时停止视频播放。
以下是必要的代码:
fps_time = 0
while True:
ret_val, image = cap.read()
humans = e.inference(image,
resize_to_default=(w > 0 and h > 0),
upsample_size=4.0)
if not showBG:
image = np.zeros(image.shape)
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()

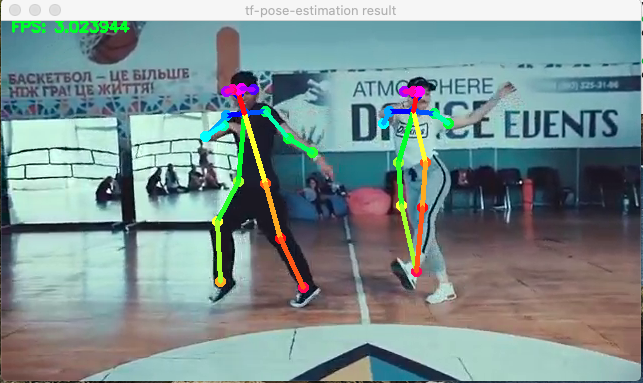
结果很好,但是有点慢。这部电影最初的帧数为每秒30帧,将在“慢摄影机”中运行,大约每秒3帧。
使用实时摄像机进行测试
建议你按照本节内容,尝试复制Jupyter Notebook:30_Pose_Estimation_Camera(https://github.com/Mjrovai/TF2_Pose_Estimation/blob/master/30_Pose_Estimation_Camera.ipynb)。
运行实时摄像机所需的代码与视频所用的代码几乎相同,只是OpenCV videoCapture()方法将接收一个整数作为输入参数,该整数表示实际使用的摄像机。例如,内部摄影机使用“0”和外部摄影机“1”。此外,相机也应设置为捕捉模型使用的“432x368”帧。
参数初始化:
camera = 1
resize = '432x368' # 处理图像之前调整图像大小
resize_out_ratio = 4.0 # 在热图进行后期处理之前调整其大小
model = 'mobilenet_thin'
show_process = False
tensorrt = False # for tensorrt process
cam = cv2.VideoCapture(camera)
cam.set(3, w)
cam.set(4, h)
代码的循环部分应与视频中使用的非常相似:
while True:
ret_val, image = cam.read()
humans = e.inference(image,
resize_to_default=(w > 0 and h > 0),
upsample_size=resize_out_ratio)
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
fps_time = time.time()
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cam.release()
cv2.destroyAllWindows()

同样,当使用该算法时,30 FPS的标准视频捕获降低约到10%。
这里有一个完整的视频,可以更好地观察到延迟。然而,结果是非常好的!
视频:https://youtu.be/Ha0fx1M3-B4
结论
一如既往,我希望这篇文章能启发其他人在这个神奇的人工智能世界里找到自己的路!
本文中使用的所有代码都可以在GitHub项目上下载:https://github.com/Mjrovai/TF2_Pose_Estimation
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/