作者|ARAVIND PAI
编译|VK
来源|Analytics Vidhya
概述
-
标识化是处理文本数据的一个关键
-
我们将讨论标识化的各种细微差别,包括如何处理词汇表外单词(OOV)
介绍
从零开始掌握一门新的语言令人望而生畏。如果你曾经学过一种不是你母语的语言,你就会理解!有太多的层次需要考虑,例如语法需要考虑。这是一个相当大的挑战。
为了让我们的计算机理解任何文本,我们需要用机器能够理解的方式把这个词分解。这就是自然语言处理(NLP)中标识化的概念。
简单地说,标识化(Tokenization)对于处理文本数据十分重要。

下面是关于标识化的有趣的事情,它不仅仅是分解文本。标识化在处理文本数据中起着重要的作用。因此,在本文中,我们将探讨自然语言处理中的标识化,以及如何在Python中实现它。
目录
-
标识化
-
标识化背后的真正原因
-
我们应该使用哪种(单词、字符或子单词)?
-
在Python中实现Byte Pair编码
标识化
标识化(Tokenization)是自然语言处理(NLP)中的一项常见任务。这是传统NLP方法(如Count Vectorizer)和高级的基于深度学习的体系结构(如Transformers)的基本步骤。
单词是自然语言的组成部分。
标识化是一种将文本分割成称为标识的较小单元的方法。在这里,标识可以是单词、字符或子单词。因此,标识化可以大致分为三种类型:单词、字符和子单词(n-gram字符)标识化。
例如,想想这句话:“Never give up”。
最常见的词的形成方式是基于空间。假设空格作为分隔符,句子的标识化会产生3个词,Never-give-up。由于每个标识都是一个单词,因此它成为单词标识化的一个示例。
类似地,标识(token)可以是字符或子单词。例如,让我们考虑smarter”:
-
字符标识:s-m-a-r-t-e-r
-
子单词(subword)标识:smart-er
但这有必要吗?我们真的需要标识化来完成这一切吗?
标识化背后的真正原因
由于词语是自然语言的构建块,所以处理原始文本的最常见方式发生在单词级别。
例如,基于Transformer的模型(NLP中的最新(SOTA)深度学习架构)在单词级别处理原始文本。类似地,对于NLP最流行的深度学习架构,如RNN、GRU和LSTM,也在单词级别处理原始文本。
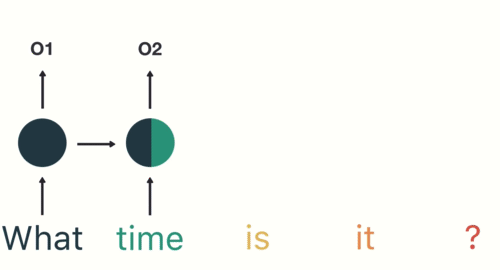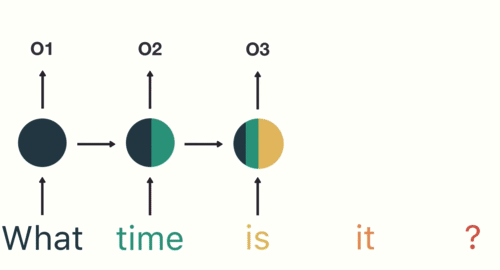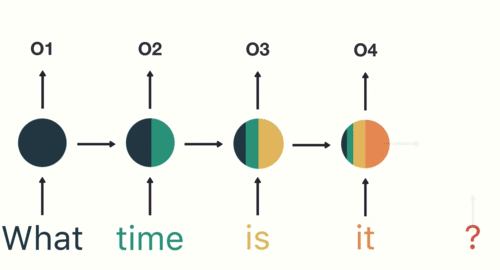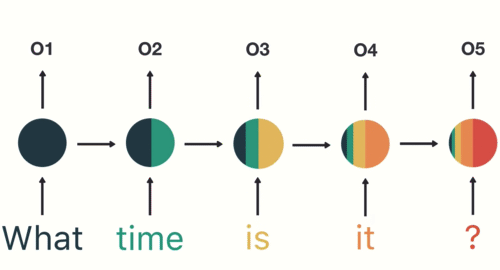
如图所示,RNN在特定的时间步接收和处理每个单词。
因此,标识化是文本数据建模的首要步骤。对语料库执行标识化以获取单词。然后使用以下单词准备词汇表。词汇是指语料库中出现过的单词。请记住,词汇表可以通过考虑语料库中每个唯一的单词或考虑前K个频繁出现的单词来构建。
创建词汇表是标识化的最终目标。
提高NLP模型性能的一个最简单的技巧是使用top K的单词创建一个词汇表。
现在,让我们了解一下词汇在传统的和高级的基于深度学习的NLP方法中的用法。
-
传统的NLP方法如单词频率计数和TF-IDF使用词汇作为特征。词汇表中的每个单词都被视为一个独特的特征:
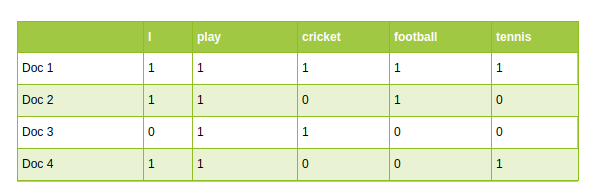
-
在基于深度学习的高级NLP体系结构中,词汇表用于创建输入语句。最后,这些单词作为输入传递给模型
我们应该使用哪种(单词、字符或子单词)?
如前所述,标识化可以在单词、字符或子单词级别执行。这是一个常见的问题-在解决NLP任务时应该使用哪种标识化?让我们在这里讨论这个问题。
单词级标识化
词标识化是最常用的标识化算法。它根据特定的分隔符将一段文本(英文)拆分为单个单词。根据分隔符的不同,将形成不同的字级标识。预训练的单词嵌入,如Word2Vec和GloVe属于单词标识化。
这种只有少量缺点。
单词级标识化的缺点
单词标识的主要问题之一是处理词汇表外(OOV)单词。OOV词是指在测试中遇到的新词。这些生词在词汇表中不存在。因此,这些方法无法处理OOV单词。
但是,等等,不要妄下结论!
-
一个小技巧可以将单词标识化器从OOV单词中解救出来。诀窍是用前K个频繁词组成词汇表,并用未知标识(UNK)替换训练数据中的稀有词。这有助于模型使用UNK学习OOV单词的表示
-
因此,在测试期间,词汇表中不存在的任何单词都将映射到UNK标识。这就是我们如何解决标识化器中的OOV问题。
-
这种方法的问题是,当我们将OOV映射到UNK单词时,单词的整个信息都会丢失。单词的结构可能有助于准确地表示单词。另一个问题是每个OOV单词都有相同的表示

单词标识的另一个问题与词汇表的大小有关。一般来说,预训练的模型是在大量的文本语料库上训练的。所以,想象一下在这么大的一个语料库中用所有单词构建词汇表。这会大大增加词汇量!
这打开了字符级标识化的大门。
字符级标识化
字符标识化将每个文本分割成一组字符。它克服了我们在上面看到的关于单词标识化的缺点。
-
字符标识化器通过保存单词的信息来连贯地处理OOV单词。它将OOV单词分解成字符,并用这些字符表示单词
-
它也限制了词汇量的大小。想猜猜词汇量吗?答案是26个。
字符标识化的缺点
字符标识解决了OOV问题,但是当我们将一个句子表示为一个字符序列时,输入和输出句子的长度会迅速增加。因此,学习单词之间的关系以形成有意义的词就变得很有挑战性。
这将我们带到另一个称为子单词标识化(Subword)的标识化,它介于字和字符标识化之间。
子单词标识化
子单词标识化将文本分割成子单词(或n个字符)。例如,lower这样的词可以被分割为low-er,smartest和smart-est,等等。
基于转换的模型(NLP中的SOTA)依赖于子单词标识化算法来准备词汇表。现在,我将讨论一种最流行的子单词标识化算法,称为Byte Pair Encoding 字节对编码(BPE)。
使用BPE
Byte Pair 编码,BPE是基于转换器的模型中广泛使用的一种标识化方法。BPE解决了单词和字符标识化器的问题:
-
BPE有效地解决了OOV问题。它将OOV分割为子单词,并用这些子单词表示单词
-
与字符标识化相比,BPE后输入和输出语句的长度更短
BPE是一种标识化算法,它迭代合并最频繁出现的字符或字符序列。下面是一个逐步学习BPE的教程。
学习BPE的步骤
-
附加结尾符号
-
用语料库中的唯一字符初始化词汇
-
计算语料库中pair或字符序列的频率
-
合并语料库中最频繁的pair
-
把最好的pair保留到词汇表中
-
对一定数量的迭代重复步骤3到5
我们将通过一个例子来理解这些步骤。
考虑语料库
1a)在语料库中的每个单词后面附加单词的结尾符号(比如说):
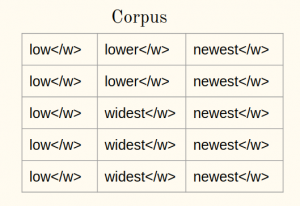
1b)将语料库中的单词分为字符:
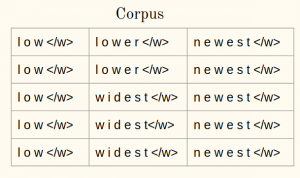
2.初始化词汇表:

迭代1:
3.计算频率:

4.合并最常见的pair:

5.保存最佳pair:

从现在开始对每个迭代重复步骤3-5。让我再演示一次迭代。
迭代2:
3.计算频率:

4.合并最常见的pair:
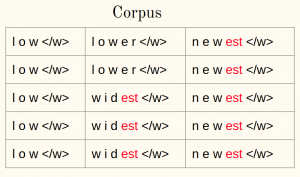
5.保存最佳pair:

经过10次迭代后,BPE合并操作如下所示:

很直截了当,对吧?
BPE在OOV词中的应用
但是,我们如何在测试时使用BPE来表示OOV单词呢?有什么想法吗?我们现在来回答这个问题。
在测试时,OOV单词被分割成字符序列。然后应用所学的操作将字符合并成更大的已知符号。
下面是表示OOV单词的表示过程:
-
追加后将OOV单词拆分为字符
-
计算一个单词中的pair或字符序列
-
选择学习过的存在的pair
-
合并最常见的pair
-
重复步骤2和3,直到可以合并
接下来让我们来看看这一切!
在Python中实现Byte Pair编码
我们现在知道BPE是如何学习和应用OOV词汇的。所以,是时候用Python实现了。
BPE的Python代码已经在原来的论文发布的代码中可用。
读取语料库
我们将考虑一个简单的语料库来说明BPE的思想。然而,同样的想法也适用于另一个语料库:
#导入库
import pandas as pd
#正在读取.txt文件
text = pd.read_csv("sample.txt",header=None)
#将数据帧转换为单个列表
corpus=[]
for row in text.values:
tokens = row[0].split(" ")
for token in tokens:
corpus.append(token)
文本预处理
将单词分割为语料库中的字符,并在每个单词的末尾附加:
#初始化词汇
vocab = list(set(" ".join(corpus)))
vocab.remove(' ')
#把这个词分成字符
corpus = [" ".join(token) for token in corpus]
#追加</w>
corpus=[token+' </w>' for token in corpus]
学习BPE
计算语料库中每个单词的频率:
import collections
#返回每个单词的频率
corpus = collections.Counter(corpus)
#将计数器对象转换为字典
corpus = dict(corpus)
print("Corpus:",corpus)
输出:

让我们定义一个函数来计算pair或字符序列的频率。它接受语料库并返回频率:
#pair或字符序列的频率
#参数是语料并且返回每个pair的频率
def get_stats(corpus):
pairs = collections.defaultdict(int)
for word, freq in corpus.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
现在,下一个任务是合并语料库中最频繁的pair。我们将定义一个函数来接受语料库、最佳pair,并返回修改后的语料库:
#合并语料库中最常见的pair
#接受语料库和最佳pair
import re
def merge_vocab(pair, corpus_in):
corpus_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!S)' + bigram + r'(?!S)')
for word in corpus_in:
w_out = p.sub(''.join(pair), word)
corpus_out[w_out] = corpus_in[word]
return corpus_out
接下来,是学习BPE操作的时候了。由于BPE是一个迭代过程,我们将执行并理解一次迭代的步骤。让我们计算bi-gram的频率:
#bi-gram的频率
pairs = get_stats(corpus)
print(pairs)
输出:

找到最常见的:
#计算最佳pair
best = max(pairs, key=pairs.get)
print("Most Frequent pair:",best)
输出:(‘e’, ‘s’)
最后,合并最佳pair并保存到词汇表中:
#语料库中频繁pair的合并
corpus = merge_vocab(best, corpus)
print("After Merging:", corpus)
#将元组转换为字符串
best = "".join(list(best))
#合并到merges和vocab
merges = []
merges.append(best)
vocab.append(best)
输出:
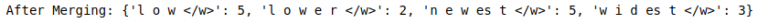
我们将遵循类似的步骤:
num_merges = 10
for i in range(num_merges):
#计算bi-gram的频率
pairs = get_stats(corpus)
#计算最佳pair
best = max(pairs, key=pairs.get)
#合并语料库中的频繁pair
corpus = merge_vocab(best, corpus)
#合并到merges和vocab
merges.append(best)
vocab.append(best)
#将元组转换为字符串
merges_in_string = ["".join(list(i)) for i in merges]
print("BPE Merge Operations:",merges_in_string)
输出:
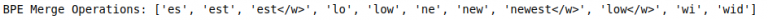
最有趣的部分还在后面呢!将BPE应用于OOV词汇。
BPE在OOV词汇中的应用
现在,我们将看到如何应用BPE在OOV单词上。例如OOV单词是“lowest”:
#BPE在OOV词汇中的应用
oov ='lowest'
#将OOV分割为字符
oov = " ".join(list(oov))
#添加 </w>
oov = oov + ' </w>'
#创建字典
oov = { oov : 1}
将BPE应用于OOV单词也是一个迭代过程。我们将执行本文前面讨论的步骤:
i=0
while(True):
#计算频率
pairs = get_stats(oov)
#提取keys
pairs = pairs.keys()
#找出之前学习中可用的pair
ind=[merges.index(i) for i in pairs if i in merges]
if(len(ind)==0):
print("
BPE Completed...")
break
#选择最常学习的操作
best = merges[min(ind)]
#合并最佳pair
oov = merge_vocab(best, oov)
print("Iteration ",i+1, list(oov.keys())[0])
i=i+1
输出:
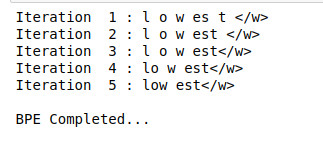
如你所见,OOV单词“low est”被分割为low-est。
结尾
标识化是处理文本数据的一种强大方法。我们在本文中看到了这一点,并使用Python实现了标识化。
继续在任何基于文本的数据集上尝试这个方法。练习得越多,就越能理解标识化是如何工作的(以及为什么它是一个如此关键的NLP概念)。
原文链接:https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/