作者|Renu Khandelwal
编译|VK
来源|Medium
在这篇文章中,我们将了解神经网络的基础知识。
这个博客的先决条件是对机器学习的基本理解,如果你尝试过一些机器学习算法,那就更好了。
首先简单介绍一下人工神经网络,也叫ANN。
很多机器学习算法的灵感来自大自然,而最大的灵感来自我们的大脑,我们如何思考、学习和做决定。
有趣的是,当我们触摸到热的东西时,我们身体里的神经元将信号传递给大脑的。然后,大脑产生冲动,从热的区域撤退。我们根据经验接受了训练。根据我们的经验,我们开始做出更好的决定。
使用同样的类比,当我们向神经网络发送一个输入(触摸热物质),然后根据学习(先前的经验),我们产生一个输出(从热区域退出)。在未来,当我们得到类似的信号(接触热表面),我们可以预测输出(从热区退出)。
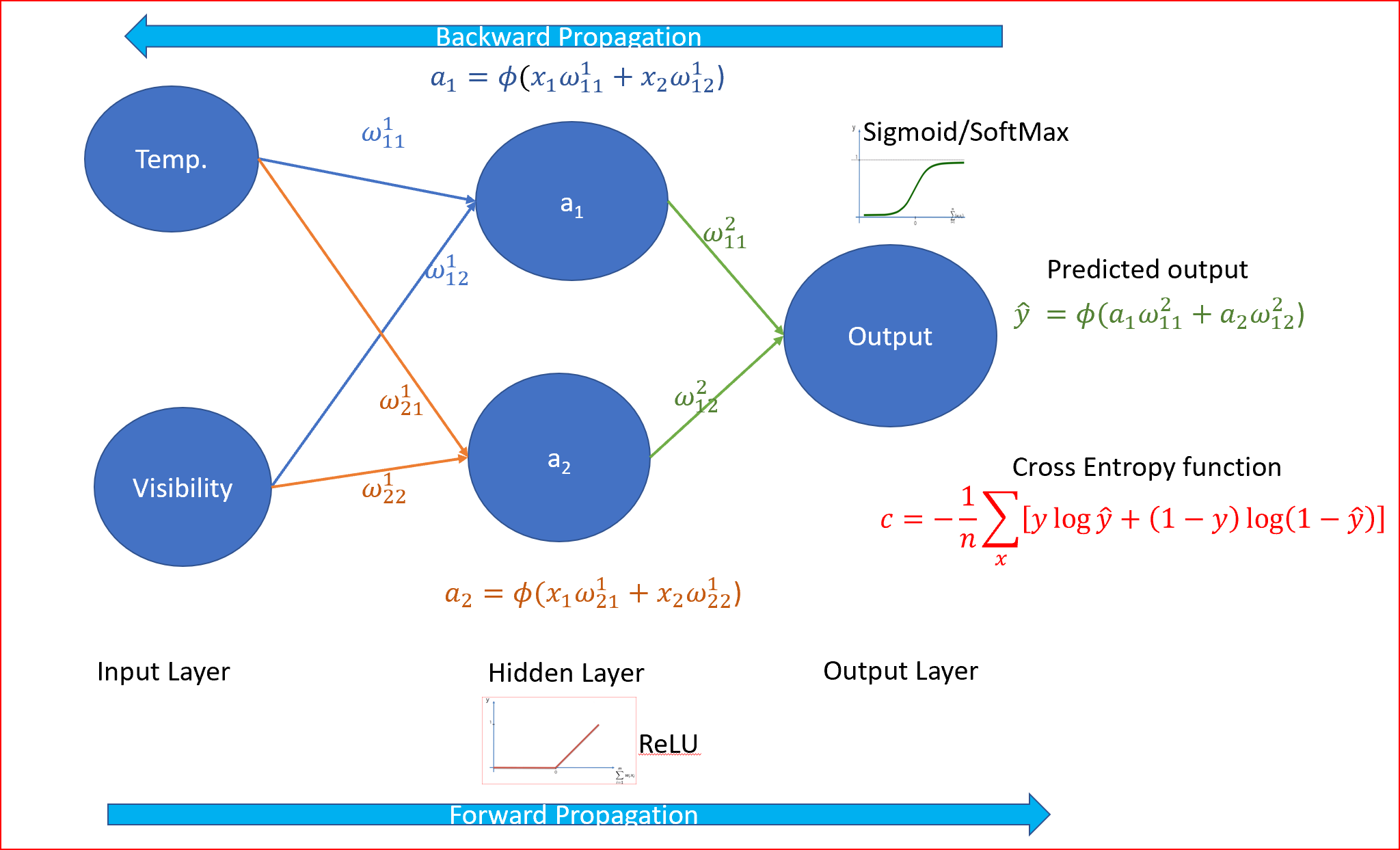
假设我们输入了诸如温度、风速、能见度、湿度等信息,以预测未来的天气状况——下雨、多云还是晴天。
这可以表示为如下所示。
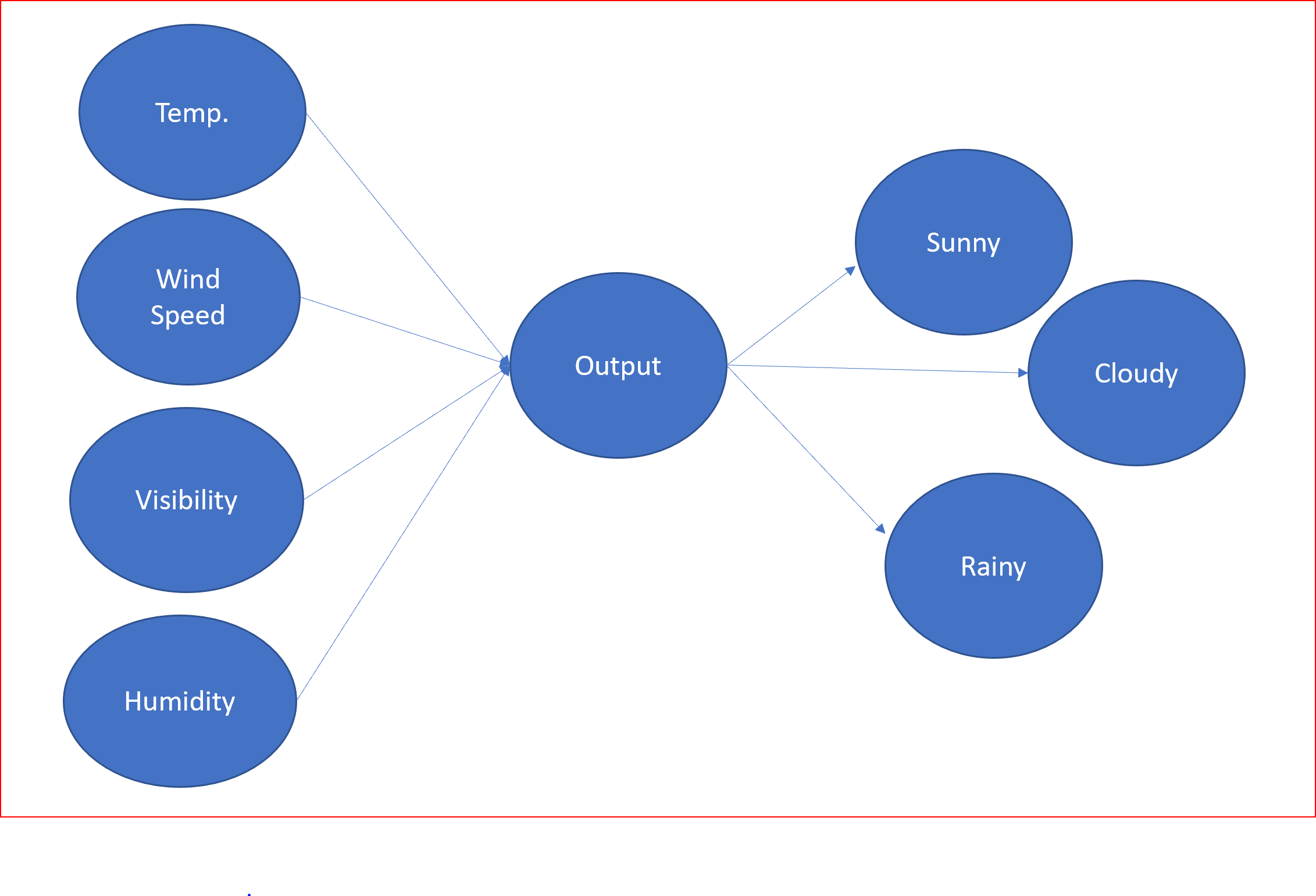
让我们用神经网络来表示它并理解神经网络的组成部分。
神经网络接收输入,通过使用激活函数改变状态来转换输入信号,从而产生输出。
输出将根据接收到的输入、强度(如果信号由权值表示)和应用于输入参数和权值的激活而改变。
神经网络与我们神经系统中的神经元非常相似。

x1、x2、…xn是神经元向树突的输入信号,在神经元的轴突末端会发生状态改变,产生输出y1、y2、…yn。
以天气预报为例,温度、风速、能见度和湿度是输入参数。然后,神经元通过使用激活函数对输入施加权重来处理这些输入,从而产生输出。这里预测的输出是晴天、雨天或阴天的类型。
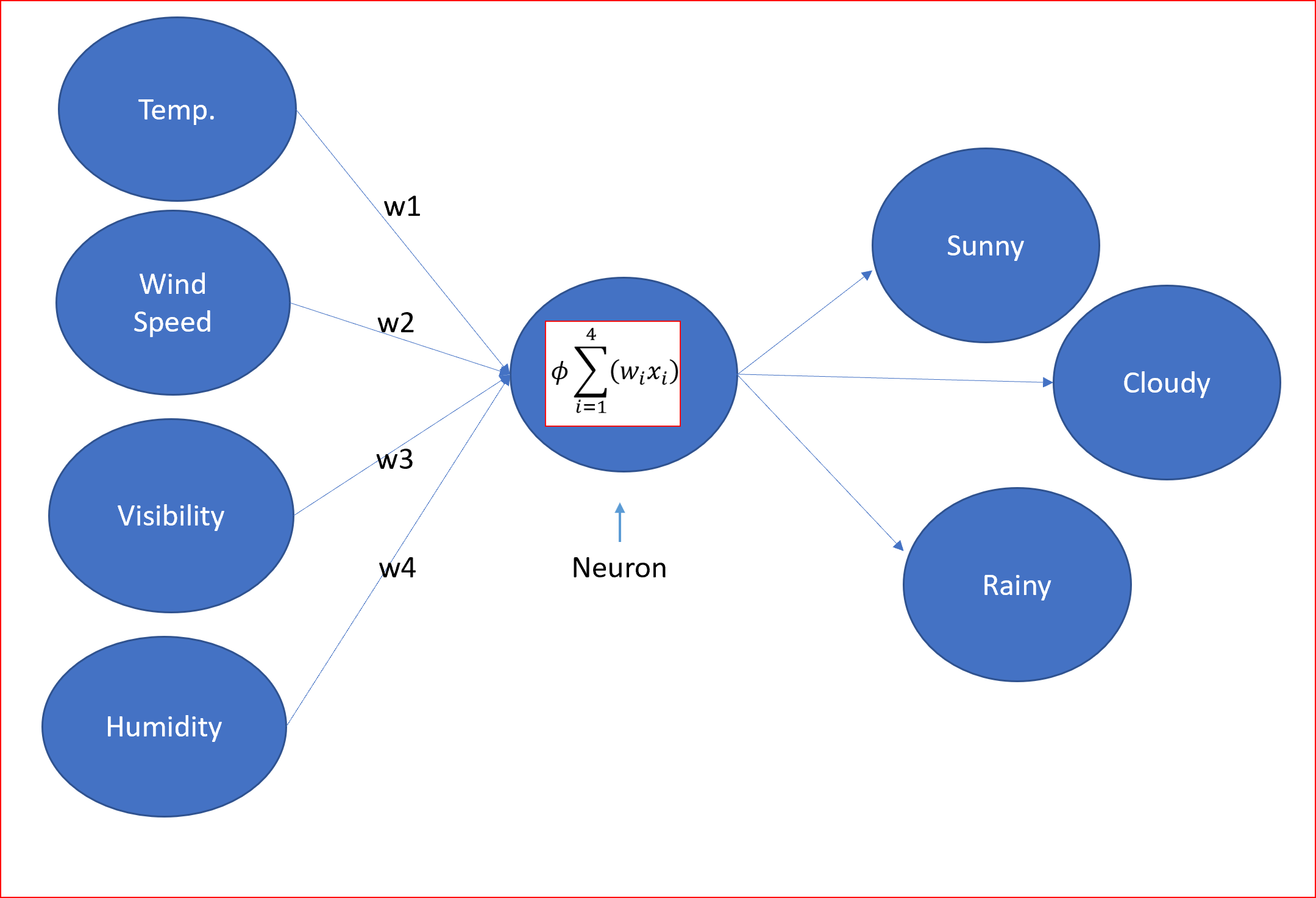
那么,神经网络的组成部分是什么呢
神经网络会有
- 输入层,偏置单元为1。
- 一个或多个隐藏层,每个隐藏层将有一个偏置单元
- 输出层
- 与每个连接相关的权重
- 将节点的输入信号转换为输出信号的激活函数
输入层、隐含层和输出层通常称为全连接层
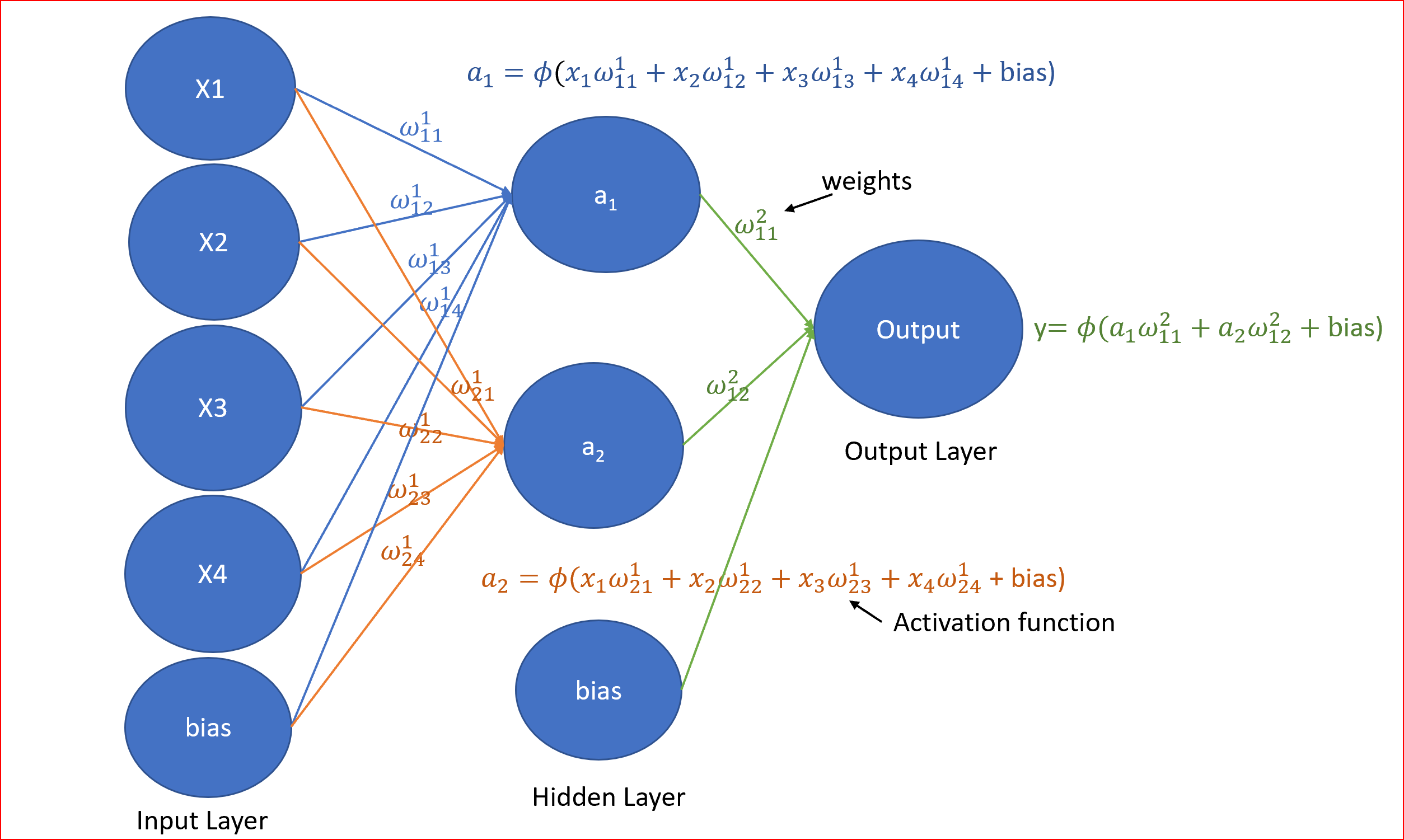
这些权值是什么,什么是激活函数,这些复方程是什么?
让我们简化
权重是神经网络学习的方式。我们调整权重来确定信号的强度。
权重帮助我们得到不同的输出。
例如,要预测晴天,温度可能介于宜人到炎热之间,晴天的能见度非常好,因此温度和能见度的权重会更高。
湿度不会太高,否则当天会下雨,所以湿度的重量可能会小一些,也可能是负的。
风速可能与晴天无关,它的强度要么为0,要么非常小。
我们随机初始化权重(w)与输入(x)相乘并添加偏差项(b),所以对于隐藏层,一个版本是计算z,然后应用激活函数(ɸ)。
我们称之为前项传播。一个方程可以表示如下,其中(l)为层的编号。对于输入层(l=1)。
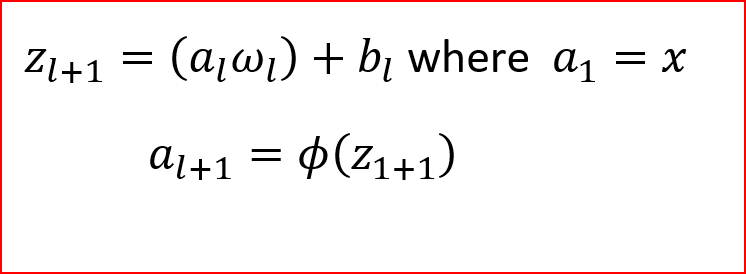
说到激活函数,我们来了解一下它们的用途
激活函数帮助我们决定是否需要激活一个神经元如果我们需要激活一个神经元那么信号的强度是多少。
激活函数是神经元通过神经网络处理和传递信息的机制。
让我们用预测天气的样本数据来理解神经网络
为了更好地理解,我们将进行简化,我们只需要两个输入:有两个隐藏节点的温度和能见度,没有偏置,我们仍然希望将天气划分为晴天或不晴天
温度是华氏温度,能见度是英里。
让我们看一个温度为50华氏度,能见度为0.01英里的数据。
步骤1:我们将权重随机初始化为一个接近于0但不等于0的值。
步骤2:接下来,我们用我们的温度和能见度的输入节点获取我们的单个数据点,并通过神经网络。
步骤3:应用从左到右的前项传播,将权值乘以输入值,然后使用ReLU作为激活函数。我们知道ReLU是隐层的最佳激活函数。
步骤4:现在我们预测输出,并将预测输出与实际输出值进行比较。由于这是一个分类问题,我们使用交叉熵函数
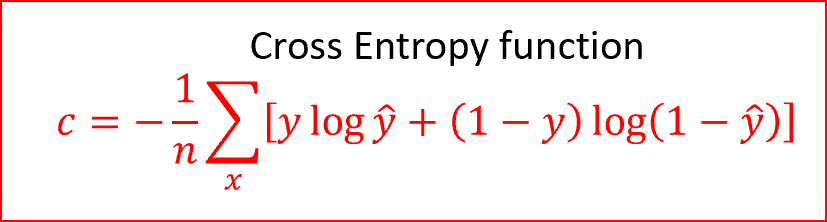
交叉熵是一个非负的代价函数,取值范围在0和1之间
在我们的例子中,实际的输出不是晴天,所以y的值为0。如果ŷ是1,那么我们把值代入成本函数,看看得到什么

类似地,当实际输出和预测输出相同时,我们得到成本c=0。
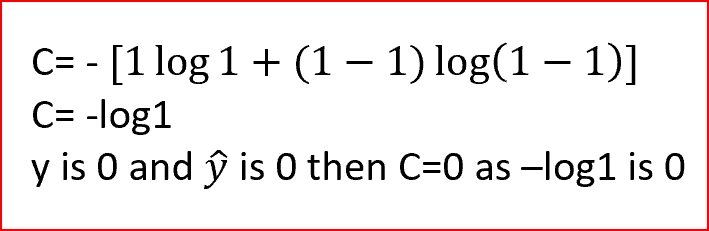
我们可以看到,对于交叉熵函数,当预测的输出与实际输出相匹配时,成本为零。当预测产量与实际产量不匹配时,成本是无穷大的。
步骤5:从右向左反向传播并调整权重。权重是根据权重对错误负责的程度进行调整的。学习率决定了我们更新权重的多少。
反向传播,学习率。我们将用简单的术语来解释一切。
反向传播
把反向传播看作是我们有时从父母、导师、同伴那里得到的反馈机制。反馈帮助我们成为一个更好的人。
反向传播是一种快速的学习算法。它告诉我们,当我们改变权重和偏差时,成本函数会发生怎样的变化。从而改变了神经网络的行为。
不需要深入研究反向传播的详细数学。在反向传播中,我们计算每个训练实例的成本对权重的偏导数和成本对偏差的偏导数。求所有训练样本的偏导数的平均值。
对于我们的单个数据点,我们确定每个权值和偏差对错误的影响程度。基于这些权值对错误的影响程度,我们同时调整所有权值。
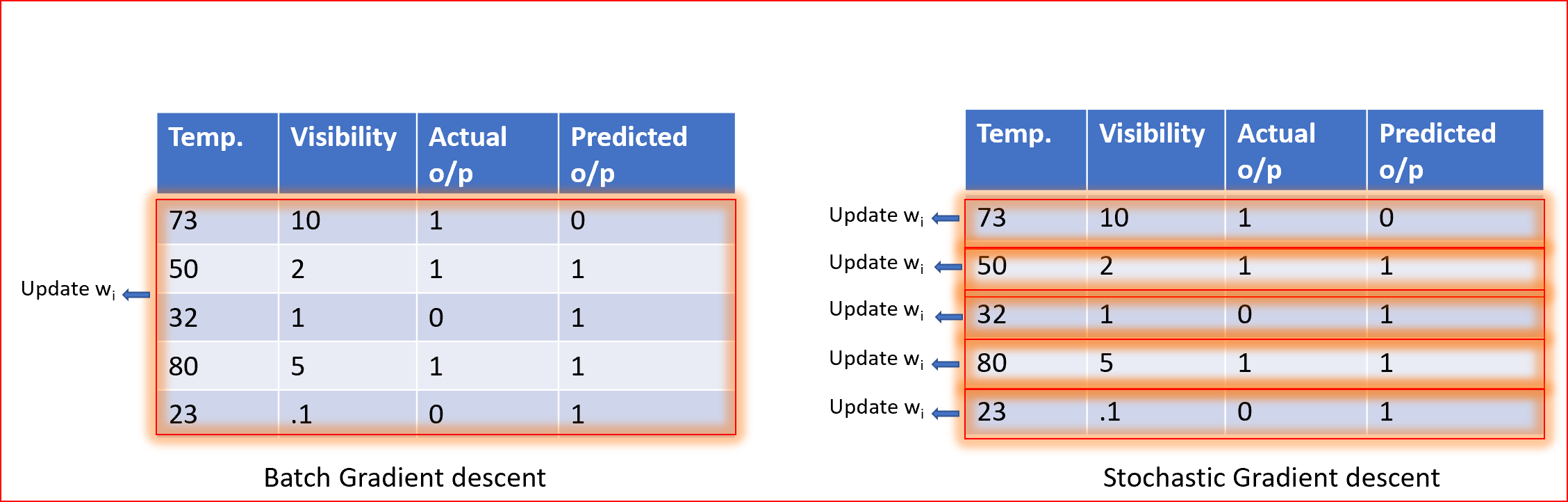
对于使用批量梯度下降(GD)的所有训练数据,可以更新一次权值;对于使用随机梯度下降(SGD)的每个训练示例,可以更新一次权值。
对于不同的权重,我们使用GD或SGD重复步骤1到步骤5。
随着权重的调整,某些节点将根据激活函数打开或关闭。
在我们的天气例子中,温度与预测多云的相关性较小,因为夏季的温度可能在70度以上,而冬季仍然是多云的,或者冬季的温度可能在30度或更低,但仍然是多云的。在这种情况下,激活函数可以决定关闭负责温度的隐藏节点,只打开可见度节点,以预测输出不是晴天,如下图所示
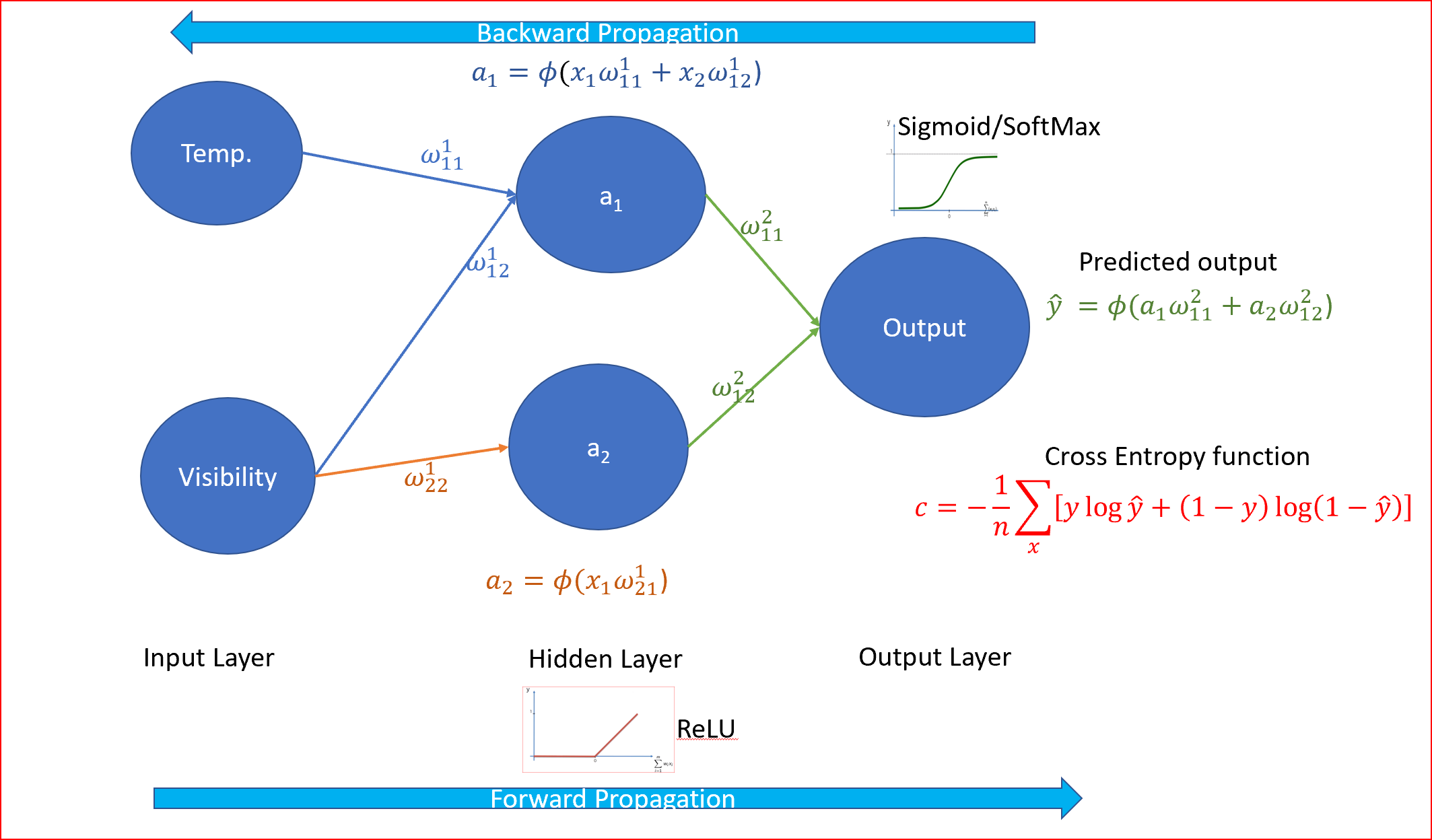
Epoch是指用于一次学习,一次正向传播和一次反向传播的完整数据集。
我们可以重复也就是在多个epoch下前项和反向传播,直到我们收敛到一个全局极小值。
什么是学习率?
学习率控制着我们应该在多大程度上根据损失梯度调整权重。
值越低,学习率越慢,收敛到全局最小。
较高的学习率值不会使梯度下降收敛
学习率是随机初始化的。

如何确定隐藏层的数量和每个隐藏层的节点数量?
随着隐层数目的增加和隐层神经元或节点数目的增加,神经网络的容量也随之增大。神经元可以协作来表达不同的功能。这常常会导致过拟合,我们必须小心过拟合。
对于神经网络中隐藏层的最优数量,根据Jeff Heaton提出的下表

对于隐藏层中神经元的最佳数目,我们可以采用下面的任何一种方法
- 输入层和输出层神经元数目的平均值。
- 在输入层的大小和输出层的大小之间。
- 2/3输入层的大小,加上输出层的大小。
- 小于输入层大小的两倍。
这是一种试图以一种简单的方式解释人工神经网络而不深入复杂数学的文章。
原文链接:https://medium.com/datadriveninvestor/neural-network-simplified-c28b6614add4
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/