作者|Jacob Gursky
编译|VK
来源|Towards Data Science

介绍
如果我告诉你训练神经网络不需要计算梯度,只需要前项传播你会怎么样?这就是神经进化的魔力!同时,我要展示的是,所有这一切只用Numpy都可以很容易地做到!学习统计学你会学到很多关于基于梯度的方法,但是不久前我读了Uber AI的人写的一篇非常有趣的文章,他表明在解决Atari游戏时,简单的遗传算法与最复杂的基于梯度的RL方法是挺有竞争力的。我链接了下面的来源,如果你对强化学习感兴趣,我强烈建议你读一读。
什么是神经进化
首先,对于那些还不知道的人,神经进化描述了进化和遗传算法在训练神经网络结构和权值方面的应用,它作为一种无梯度的替代方法!我们将在这里使用一个非常简单的神经进化案例,只使用一个固定拓扑网络,只关注优化权重和偏差。神经进化过程可以定义为四个基本步骤,重复这些步骤直到达到收敛,首先是一个随机生成的网络池。
- 评估种群的适应度
- 选择最适合复制的个体
- 使用最适合网络的副本重新填充
- 在网络权值中引入正态分布突变
哇,这看起来很简单!让我们把一些术语分解一下:
-
适应度:这只是描述网络在特定任务中的表现,并允许我们确定要培育哪些网络。注意,因为进化算法是非凸优化的一种形式,因此可以与任何损失函数一起使用,而不管其可微性(或缺乏可微性)如何
-
变异:这个可能是最简单的!为了改进我们的子网络,我们必须对网络权值引入随机变化,这些权值通常来自均匀或正态分布。有很多不同形式的突变:移位突变(将参数乘以随机数)、交换突变(将参数替换为随机数)、符号突变(更改参数的符号)等等。我们只会使用简单的加性突变,但这里有很大的创新空间!
神经进化的优势
我们还应该考虑神经进化模型的理论优势。首先,我们只需要使用网络的前向传递,因为我们只需要计算损失,以确定要复制的网络。这意味着显而易见,反向传播通常是最昂贵的!其次,在给定足够的迭代次数的情况下,进化算法保证能找到损失曲面的全局最小值,而基于凸梯度的方法则陷入局部最小值。最后,更复杂的神经进化形式使我们不仅可以优化网络的权值,还可以优化结构本身!
那为什么不一直用神经进化呢?
这是一个复杂的问题,但它可以归结为,当有足够的梯度信息时,精确的梯度下降法更有效。这意味着损失曲面越凸出,你就越想使用SGD之类的分析方法,而不是遗传算法。因此,在有监督的环境下使用遗传算法是非常罕见的,因为通常有足够的梯度信息可用,传统的梯度下降方法将工作得很好。然而,如果你是在RL环境下工作,或者是在不规则的缺失面或低凸度的情况下(如连续的GAN),那么神经进化提供了一个可行的选择!事实上,最近的许多研究发现,参数化神经进化模型在这些环境下可以做得更好。
实现
加载库
正如介绍中所述,我们将尝试在这个项目中只使用numpy,只定义我们需要的helper函数。
import numpy as np
import gym
关于数据
我们将使用来自gym的经典侧手翻环境来测试我们的网络。我们的目标是通过左右移动来观察这个网络能让杆子保持直立多久。作为一个RL任务,神经进化方法应该是一个很好的选择!我们的网络将接收4个观测结果作为输入,并将左右输出作为一个动作。
helper函数
首先,我们将定义几个帮助函数来建立我们的网络。首先是relu激活函数,我们将使用它作为隐藏层的激活函数,使用softmax函数作为网络的输出,以获得网络输出的概率估计!最后,我们需要定义一个函数,当我们需要计算分类交叉熵时,该函数生成响应向量的one-hot编码。
def relu(x):
return np.where(x>0,x,0)
def softmax(x):
x = np.exp(x — np.max(x))
x[x==0] = 1e-15
return np.array(x / x.sum())
定义我们的网络
首先,我们将为总体中的各个网络定义一个类。我们需要定义一个初始化方法,它随机分配权重和偏差,并以网络结构作为输入,一个预测方法,这样我们可以得到一个输入的概率,最后一个评估方法,返回给定输入和响应的网络的分类交叉熵!同样,我们只使用我们定义的函数或numpy中的函数。注意,初始化方法也可以将另一个网络作为输入,这就是我们将如何在代之间执行突变!
# 让我们定义一个新的神经网络类,可以与gym交互
class NeuralNet():
def __init__(self, n_units=None, copy_network=None, var=0.02, episodes=50, max_episode_length=200):
# 测试我们是否需要复制一个网络
if copy_network is None:
# Saving attributes
self.n_units = n_units
# 初始化空列表以容纳矩阵
weights = []
biases = []
# 填充列表
for i in range(len(n_units)-1):
weights.append(np.random.normal(loc=0,scale=1,size=(n_units[i],n_units[i+1])))
biases.append(np.zeros(n_units[i+1]))
# 创建参数字典
self.params = {'weights':weights,'biases':biases}
else:
self.n_units = copy_network.n_units
self.params = {'weights':np.copy(copy_network.params['weights']),
'biases':np.copy(copy_network.params['biases'])}
# 突变权重
self.params['weights'] = [x+np.random.normal(loc=0,scale=var,size=x.shape) for x in self.params['weights']]
self.params['biases'] = [x+np.random.normal(loc=0,scale=var,size=x.shape) for x in self.params['biases']]
def act(self, X):
# 获取权重和偏置
weights = self.params['weights']
biases = self.params['biases']
# 第一个输入
a = relu((X@weights[0])+biases[0])
# 在其他层传播
for i in range(1,len(weights)):
a = relu((a@weights[i])+biases[i])
#获取概率
probs = softmax(a)
return np.argmax(probs)
# 定义评估方法
def evaluate(self, episodes, max_episode_length, render_env, record):
# 为奖励创建空列表
rewards = []
# 首先,我们需要建立我们的gym环境
env=gym.make('CartPole-v0')
# 如果需要的话,我们可以录像
if record is True:
env = gym.wrappers.Monitor(env, "recording")
env._max_episode_steps=1e20
for i_episode in range(episodes):
observation = env.reset()
for t in range(max_episode_length):
if render_env is True:
env.render()
observation, _, done, _ = env.step(self.act(np.array(observation)))
if done:
rewards.append(t)
break
# 关闭环境
env.close()
# 获取最终奖励
if len(rewards) == 0:
return 0
else:
return np.array(rewards).mean()
定义我们的遗传算法类
最后,我们需要定义一个类来管理我们的种群,以执行神经进化的四个关键步骤!我们需要三个方法。首先,创建一个随机网络池并设置属性的初始化方法。接下来,我们需要一个fit方法,给定一个输入,重复执行上面列出的步骤:首先评估网络,然后选择最合适的网络,创建子网络,最后修改子网络!最后,我们需要一个预测的方法,这样我们就可以使用最好的网络训练类。让我们开始测试吧!
# 定义处理网络种群的类
class GeneticNetworks():
#定义我们的初始化方法
def __init__(self, architecture=(4,16,2),population_size=50, generations=500,render_env=True, record=False,
mutation_variance=0.02,verbose=False,print_every=1,episodes=10,max_episode_length=200):
# 创建我们的网络列表
self.networks = [NeuralNet(architecture) for _ in range(population_size)]
self.population_size = population_size
self.generations = generations
self.mutation_variance = mutation_variance
self.verbose = verbose
self.print_every = print_every
self.fitness = []
self.episodes = episodes
self.max_episode_length = max_episode_length
self.render_env = render_env
self.record = record
# 定义我们的fiting方法
def fit(self):
# 遍历所有代
for i in range(self.generations):
# 评估
rewards = np.array([x.evaluate(self.episodes, self.max_episode_length, self.render_env, self.record) for x in self.networks])
# 跟踪每一代的最佳得分
self.fitness.append(np.max(rewards))
# 选择最佳网络
best_network = np.argmax(rewards)
# 创建子网络
new_networks = [NeuralNet(copy_network=self.networks[best_network], var=self.mutation_variance, max_episode_length=self.max_episode_length) for _ in range(self.population_size-1)]
#设置新网络
self.networks = [self.networks[best_network]]+new_networks
# 如果必要输出结果
if self.verbose is True and (i%self.print_every==0 or i==0):
print('Generation:',i+1,'| Highest Reward:',rewards.max().round(1),'| Average Reward:',rewards.mean().round(1))
# 返回最佳网络
self.best_network = self.networks[best_network]
测试算法
如上所述,我们将在CartPole问题上测试我们的网络,只使用一个包含16个节点的隐含层和两个表示向左或向右移动的输出节点。我们还需要多次迭代中平均,这样我们就不会不小心为下一代选择了一个糟糕的网络!我在经过一些尝试和错误之后选择了许多这样的参数,所以你的情况可能会有所不同!此外,我们将只引入方差为0.05的突变,以免破坏网络的功能。
# 让我们训练一个网络种群
from time import time
start_time = time()
genetic_pop = GeneticNetworks(architecture=(4,16,2),
population_size=64,
generations=5,
episodes=15,
mutation_variance=0.1,
max_episode_length=10000,
render_env=False,
verbose=True)
genetic_pop.fit()
print('Finished in',round(time()-start_time,3),'seconds')
Generation: 1 | Highest Reward: 309.5 | Average Reward: 29.2
Generation: 2 | Highest Reward: 360.9 | Average Reward: 133.6
Generation: 3 | Highest Reward: 648.2 | Average Reward: 148.0
Generation: 4 | Highest Reward: 616.6 | Average Reward: 149.9
Generation: 5 | Highest Reward: 2060.1 | Average Reward: 368.3
Finished in 35.569 seconds
最初的随机网络
首先,让我们看看一个随机初始化的网络是如何执行这个任务的。很明显,这里没有策略,杆子几乎马上就倒了。请忽略下面gif图中的光标
random_network = NeuralNet(n_units=(4,16,2))
random_network.evaluate(episodes=1, max_episode_length=int(1e10), render_env=True, record=False)
5代之后……
仅仅经过5代,我们可以看到我们的网络已经几乎完全掌握了CartPole!而且只花了大约30秒的训练时间!请注意,随着进一步的训练,网络学习保持它完全直立,几乎所有的时间都是这样,但目前我们只是感兴趣的速度,5代是相当短的!我们应该把这看作是神经进化力量的一个很好的例子。
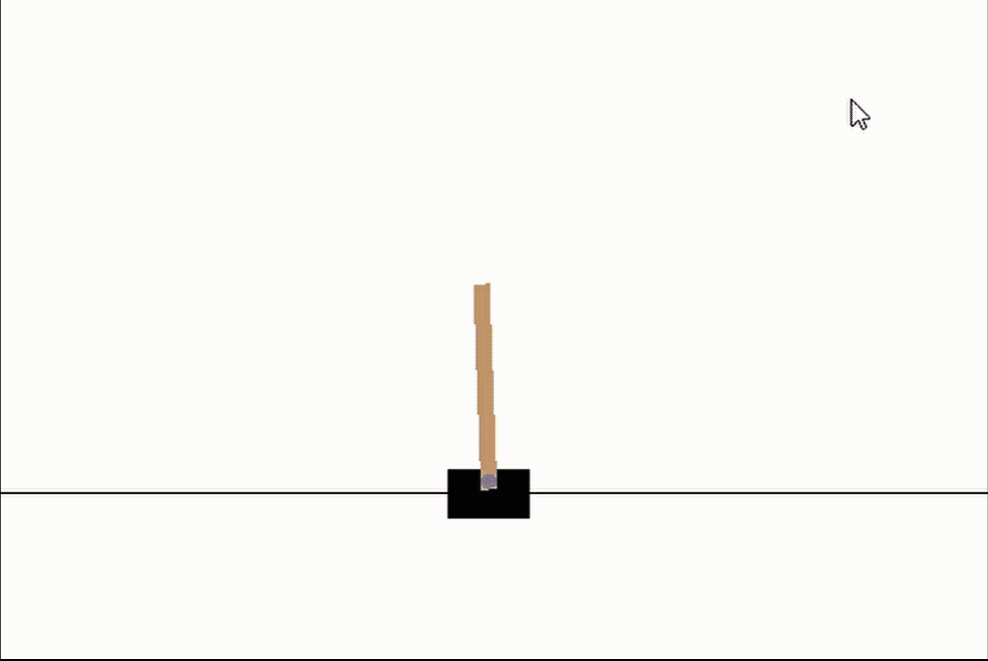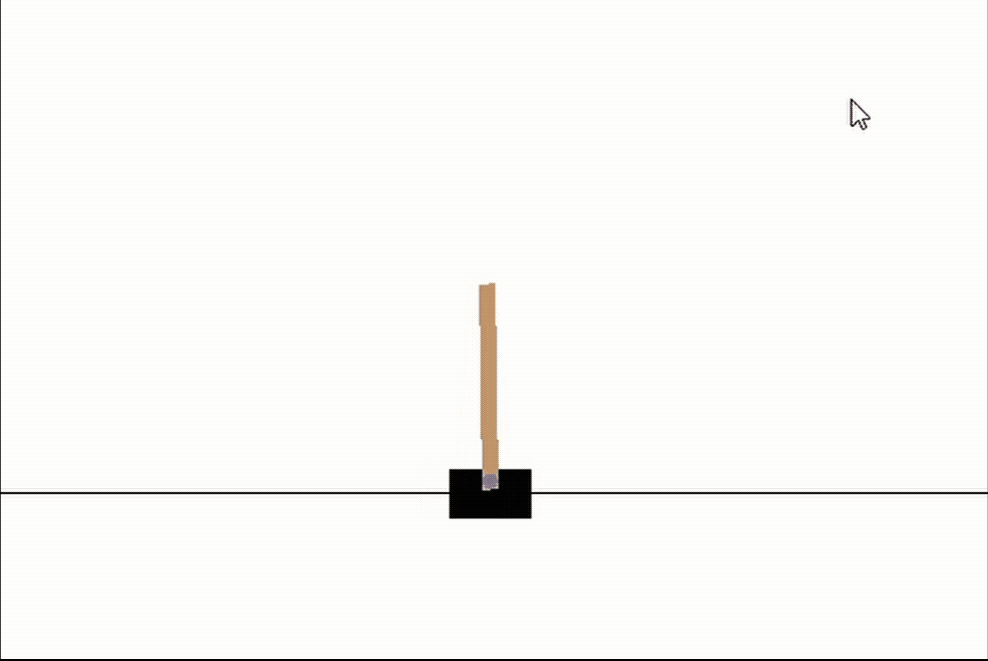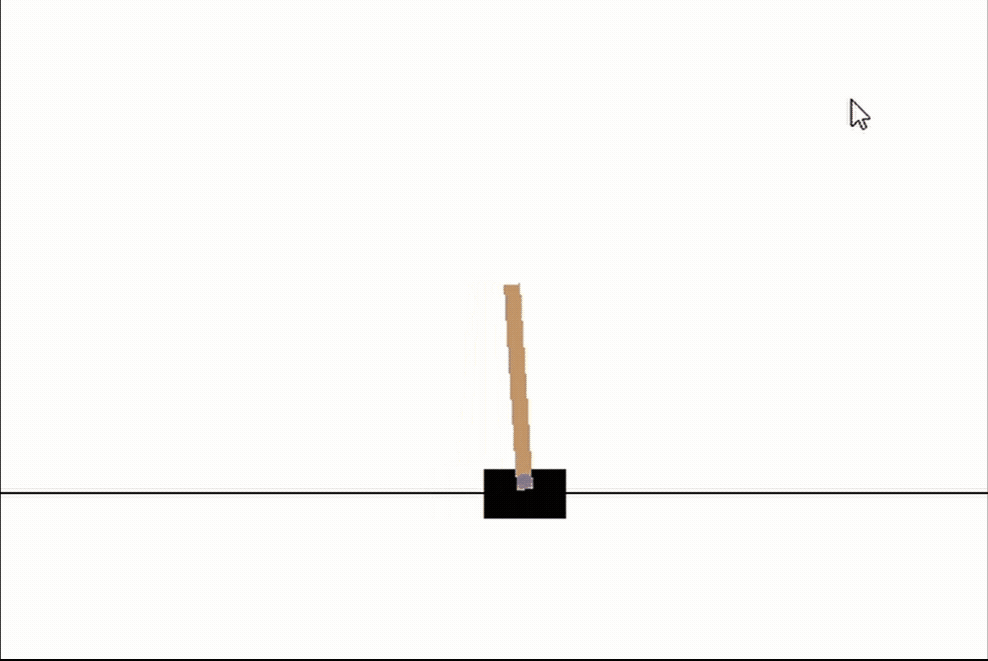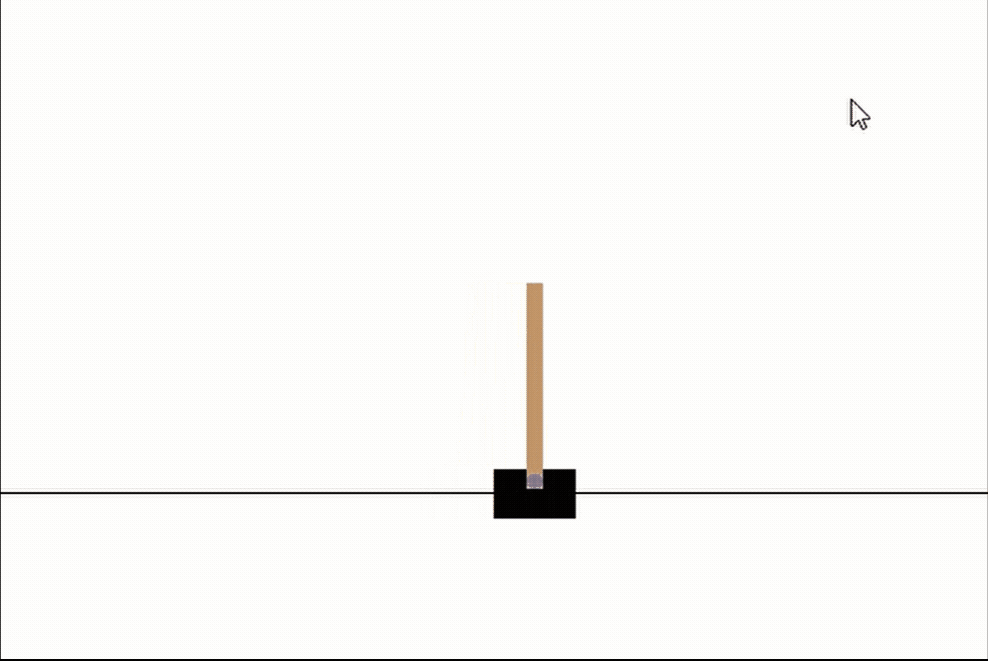
# 让我们看看我们最好的网络
genetic_pop.best_network.evaluate(episodes=3, max_episode_length=int(1e10), render_env=True, record=False)
结尾
很明显,我们可以在未来添加很多东西来进一步检验神经进化的有效性。首先,研究不同的突变操作如交叉操作的影响是很有趣的。
转移到像TensorFlow或PyTorch这样的现代深度学习平台也是一个明智的想法。请注意,遗传算法是高度并行的,因为我们所要做的就是在一个前项传播的设备上运行每个网络。不需要反映权重或复杂的分配策略!因此,每增加一个处理单元,我们的运行时间几乎会直线下降。
最后,我们应该在不同的强化学习任务中探索神经进化,甚至在梯度难以评估的其他情况下,例如在生成对抗网络或长序列LSTM网络中。
进一步的阅读
如果你对神经进化及其应用感兴趣,Uber在几篇论文中有一个精彩的页面,展示了神经进化在强化学习方面的现代优势:
https://eng.uber.com/tag/deep-neuroevolution/
这个项目的源代码可以在GitHub库中找到:
https://github.com/gursky1/Numpy-Neuroevolution
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/