作者|PRATEEK JOSHI
编译|VK
来源|Analytics Vidhya
决策树与随机森林的简单类比
让我们从一个思维实验开始,它将说明决策树和随机森林模型之间的区别。
假设银行必须为客户批准一笔小额贷款,而银行需要迅速做出决定。银行检查此人的信用记录和财务状况,发现他们还没有偿还旧贷款。因此,银行拒绝了申请。
但问题是,对于银行庞大的金库来说,贷款数额非常小,他们本可以在非常低风险的情况下批准贷款。因此,银行失去了赚钱的机会。
现在,又一个贷款申请将在几天内完成,但这一次银行提出了一个不同的策略——多个决策过程。有时它先检查信用记录,有时它先检查客户的财务状况和贷款金额。然后,银行结合这些多个决策过程的结果,决定向客户发放贷款。
即使这一过程比前一个过程花费更多的时间,银行也可以利用这一方法获利。这是一个典型的例子,集体决策优于单一决策过程。现在,你知道这两个过程代表了什么吧?

这些分别代表决策树和随机森林!我们将在这里详细探讨这个想法,深入探讨这两种方法之间的主要区别,并回答关键问题,你应该使用哪种算法?
目录
-
决策树简介
-
随机森林简介
-
随机森林与决策树的冲突
-
为什么随机森林优于决策树?
-
决策树与随机森林—你什么时候应该选择哪种算法?
决策树简介
决策树是一种有监督的机器学习算法,可用于分类和回归问题。决策树仅仅是为了达到特定结果而做出的一系列顺序决策。下面是一个正在运行的决策树的示例(使用上面的示例):
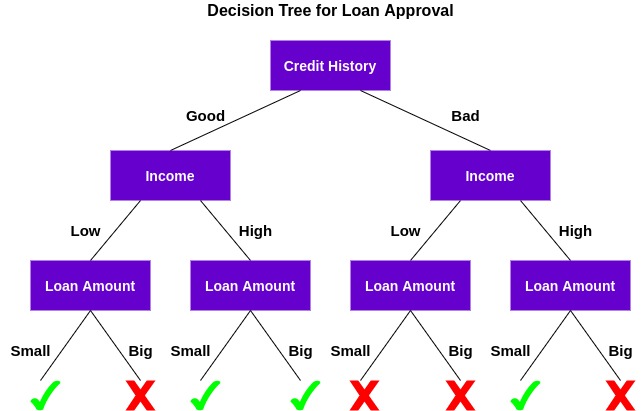
让我们了解这棵树是如何工作的。
首先,它检查客户是否有良好的信用记录。在此基础上,将客户分为信用记录良好的客户和信用记录不良的客户两类。然后,它检查客户的收入,并再次将他/她分为两组。最后,它检查客户要求的贷款金额。根据检查这三个特征的结果,决策树决定是否应该批准客户的贷款。
特征/属性和条件可以根据数据和问题的复杂性而改变,但总体思路保持不变。因此,决策树根据数据中的一组特征/属性(在本例中为信用历史、收入和贷款金额)做出一系列决策。
现在,你可能会想:
为什么决策树首先检查信用评分而不是收入?
这被称为特征的重要性,要检查的属性序列是根据基尼系数或信息增益等标准确定的。对这些概念的解释超出了本文的讨论范围,但你可以参考以下任一资源来了解有关决策树的所有信息:
注:本文的思想是比较决策树和随机森林。因此,我不会详细介绍基本概念。
随机森林简介
决策树算法易于理解和解释。但通常,一棵树不足以产生有效的结果。这就引入随机森林的概念。

随机森林是一种基于树的机器学习算法,它利用多个决策树的能力进行决策。顾名思义,这是一片由树组成的“森林”!
但为什么我们称之为“随机”森林?那是因为它是一个由随机创建的决策树组成的森林。决策树中的每个节点对随机的特征子集进行运算以计算输出。然后,随机森林将各个决策树的输出组合起来生成最终的输出。
简单地说:
随机森林算法将多个(随机创建的)决策树的输出组合起来生成最终输出。

将多个个体模型(也称为弱学习者)的输出结合起来的过程称为集成学习。
现在的问题是,我们如何决定在决策树和随机森林之间选择哪种算法?在我们做出任何结论之前,让我们看看他们在实践中是什么样子的!
随机森林与决策树的冲突
在本节中,我们将使用Python来解决使用决策树和随机森林的二分类问题。然后我们将比较他们的结果,看看哪一个最适合我们的问题。
我们将开发贷款预测数据集。这是一个二元分类问题,在这个问题上,我们必须根据一组特定的特征来确定一个人是否应该获得贷款。
步骤1:加载库和数据集
首先导入所需的Python库和数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
# 导入数据集
df=pd.read_csv('dataset.csv')
df.head()

该数据集由614行和13个特征组成,包括信用记录、婚姻状况、贷款金额和性别。这里,目标变量是Loan_Status,它指示是否应该向某人提供贷款。
步骤2:数据预处理
现在,是任何数据科学项目中最关键的部分——数据预处理和特征工程。在这一节中,我将处理数据中的分类变量,并输入缺失的值。
我将用模式来估算分类变量中的缺失值,对于连续变量,用平均值(对于各个列)来估算。另外,我们将对数据中的分类值进行标签编码。
#数据预处理与空值插补
# 标签编码
df['Gender']=df['Gender'].map({'Male':1,'Female':0})
df['Married']=df['Married'].map({'Yes':1,'No':0})
df['Education']=df['Education'].map({'Graduate':1,'Not Graduate':0})
df['Dependents'].replace('3+',3,inplace=True)
df['Self_Employed']=df['Self_Employed'].map({'Yes':1,'No':0})
df['Property_Area']=df['Property_Area'].map({'Semiurban':1,'Urban':2,'Rural':3})
df['Loan_Status']=df['Loan_Status'].map({'Y':1,'N':0})
#零值插补
rev_null=['Gender','Married','Dependents','Self_Employed','Credit_History','LoanAmount','Loan_Amount_Term']
df[rev_null]=df[rev_null].replace({np.nan:df['Gender'].mode(),
np.nan:df['Married'].mode(),
np.nan:df['Dependents'].mode(),
np.nan:df['Self_Employed'].mode(),
np.nan:df['Credit_History'].mode(),
np.nan:df['LoanAmount'].mean(),
np.nan:df['Loan_Amount_Term'].mean()})

步骤3:创建训练和测试集
现在,我们将数据集按80:20的比例分别拆分为训练集和测试集:
X=df.drop(columns=['Loan_ID','Loan_Status']).values
Y=df['Loan_Status'].values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)
让我们看看创建的训练集和测试集的形状:
print('Shape of X_train=>',X_train.shape)
print('Shape of X_test=>',X_test.shape)
print('Shape of Y_train=>',Y_train.shape)
print('Shape of Y_test=>',Y_test.shape)
太好了!现在我们准备好进入下一个阶段,在那里我们将建立决策树和随机森林模型!
步骤4:建立和评估模型
由于我们有训练集和测试集,现在是时候训练我们的模型并对贷款申请进行分类了。首先,我们将在此数据集上训练决策树:
# 建立决策树
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion = 'entropy', random_state = 42)
dt.fit(X_train, Y_train)
dt_pred_train = dt.predict(X_train)
接下来,我们将使用F1分数来评估这个模型。F1分数是精度和召回率的调和平均值,公式如下:

让我们使用F1分数来评估我们的模型的性能:
#训练集评估
dt_pred_train = dt.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,dt_pred_train))
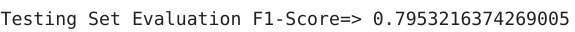
在这里,你可以看到决策树在样本内评估时表现良好,但在样本外评估时其性能急剧下降。你觉得为什么会这样?这里发生了过拟合。随机森林能解决这个问题吗?
建立随机森林模型
让我们看看一个正在运行的随机森林模型:
# 建立随机森林分类器
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(criterion = 'entropy', random_state = 42)
rfc.fit(X_train, Y_train)
#训练集评估
rfc_pred_train = rfc.predict(X_train)
print('Training Set Evaluation F1-Score=>',f1_score(Y_train,rfc_pred_train))

在这里,我们可以清楚地看到,在样本外评估中,随机森林模型比决策树表现得更好。让我们在下一节讨论这背后的原因。
为什么随机森林模型优于决策树?
随机森林利用了多个决策树的能力。它不依赖于单一决策树给出的特征重要性。让我们来看看不同算法对不同特征所赋予的特征重要性:
feature_importance=pd.DataFrame({
'rfc':rfc.feature_importances_,
'dt':dt.feature_importances_
},index=df.drop(columns=['Loan_ID','Loan_Status']).columns)
feature_importance.sort_values(by='rfc',ascending=True,inplace=True)
index = np.arange(len(feature_importance))
fig, ax = plt.subplots(figsize=(18,8))
rfc_feature=ax.barh(index,feature_importance['rfc'],0.4,color='purple',label='Random Forest')
dt_feature=ax.barh(index+0.4,feature_importance['dt'],0.4,color='lightgreen',label='Decision Tree')
ax.set(yticks=index+0.4,yticklabels=feature_importance.index)
ax.legend()
plt.show()

如上图所示,决策树模型高度重视一组特定的特征。但在训练过程中随机选择特征。因此,它不高度依赖于任何特定的特性集。这是随机森林的一个特殊效果。
因此,随机森林可以更好地对数据进行泛化。这种随机特征选择使得随机森林比决策树更加精确。
所以你应该选择哪一个,决策树还是随机森林?
当我们有一个大的数据集时,随机森林是合适的,可解释性不是主要的关注点。
决策树更容易解释和理解。由于一个随机森林结合了多个决策树,因此它变得更加难以解释。好消息是,要解释一个随机的森林并非不可能。
而且,随机森林比单一决策树具有更高的训练时间。你应该考虑到这一点,因为当我们增加随机森林中的树木数量时,训练每一棵树所需的时间也会增加。当你在机器学习项目中的DDL很紧的时候,这通常是至关重要的。
但我要说的是,尽管不稳定和依赖于一组特定的特性,决策树还是非常有用的,因为它们更容易解释,也更容易训练。任何对数据科学知之甚少的人也可以使用决策树快速做出数据驱动的决策。
结尾
决策树和随机森林的辩论,这是你需要知道的。当你对机器学习还不熟悉的时候,它可能会变得很棘手,但是本文应该为你澄清这些差异和相似之处。
原文链接:https://www.analyticsvidhya.com/blog/2020/05/decision-tree-vs-random-forest-algorithm/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/