欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
上一篇文章中一直围绕着CNN处理图像数据进行讲解,而CNN除了处理图像数据之外,还适用于文本分类。CNN模型首次使用在文本分类,是Yoon Kim发表的“Convolutional Neural Networks for Sentence Classification”论文中。在讲解text-CNN之前,先介绍自然语言处理和Keras对自然语言的预处理。
自然语言处理就是通过对文本进行分析,从文本中提取关键词来让计算机处理或理解自然语言,完成一些有用的应用,如:情感分析,问答系统等。比如在情感分析中,其本质就是根据已知的文字和情感符号(如评论等)推测这段文字是正面还是负面的。想象一下,如果我们能够更加精确地进行情感分析,可以大大提升人们对于事物的理解效率。比如不少基金公司利用人们对于某家公司的看法态度来预测未来股票的涨跌。
接下来将使用imdb影评数据集简单介绍Keras如何预处理文本数据。该数据集在这里下载。由于下载得的是tar.gz压缩文件,可以使用python的tarfile模块解压。解压后的目录为:
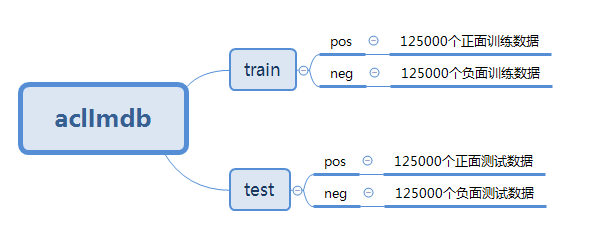
1.读取imdb数据集
我们通过以下函数分别读取train和test中的所有影评
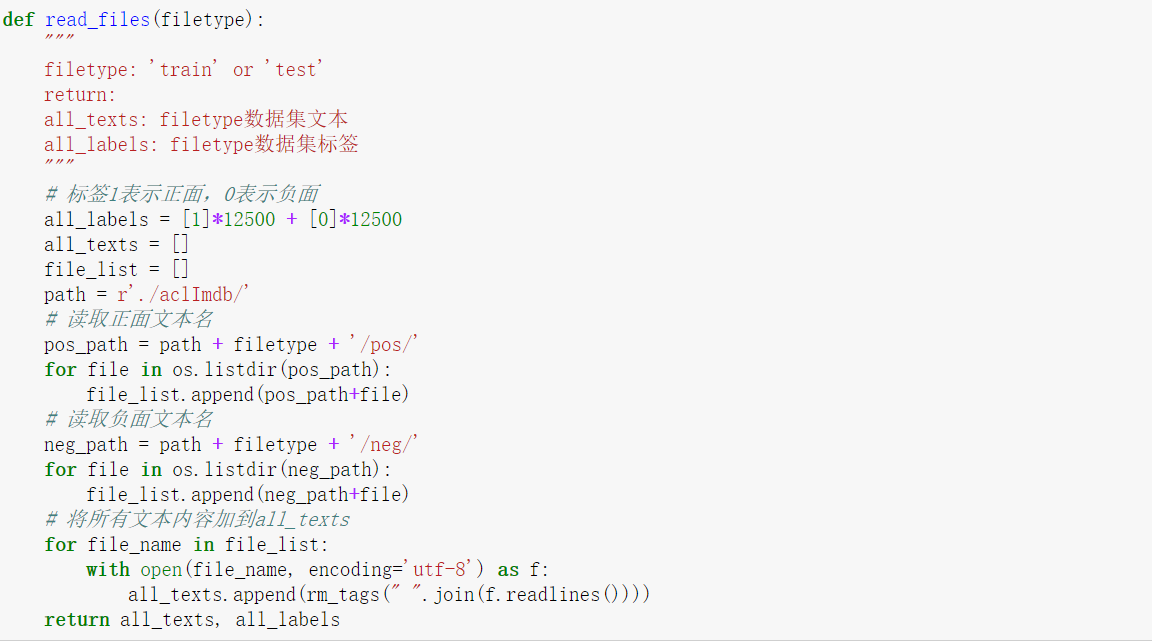
得到的影评如下图,每条影评用双引号包住。

2.使用Tokenizer将影评文字转换成数字特征
在上文中已经得到了每条影评文字了,但是text-CNN的输入应该是数字矩阵。可以使用Keras的Tokenizer模块实现转换。
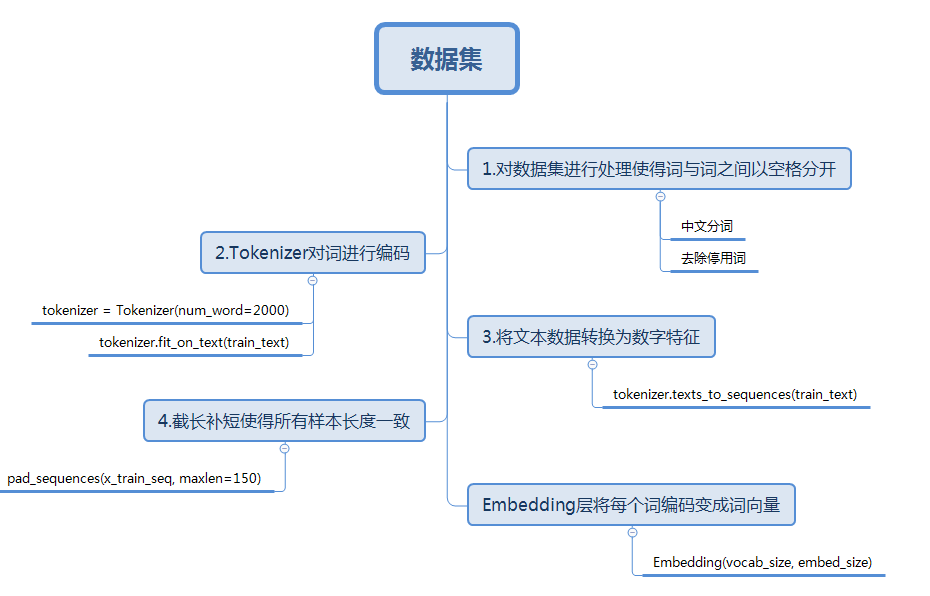
简单讲解Tokenizer如何实现转换。当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。可能这时会有疑问:Tokenizer是如何判断文本的一个词呢?其实它是以空格去识别每个词。因为英文的词与词之间是以空格分隔,所以我们可以直接将文本作为函数的参数,但是当我们处理中文文本时,我们需要使用分词工具将词与词分开,并且词间使用空格分开。具体实现如下:

使用word_index属性可以看到每次词对应的编码,可以发现类似”the”、”a”等词的词频很高,但是这些词并不能表达文本的主题,我们称之为停用词。对文本预处理的过程中,我们希望能够尽可能提取到更多关键词去表达这句话或文本的中心思想,因此我们可以将这些停用词去掉后再编码。网上有许多归纳好的停用词,大家可以下载了之后,去除该文本中的停用词。

对每个词编码之后,每句影评中的每个词就可以用对应的编码表示,即每条影评已经转变成一个向量了:

3.让每句数字影评长度相同
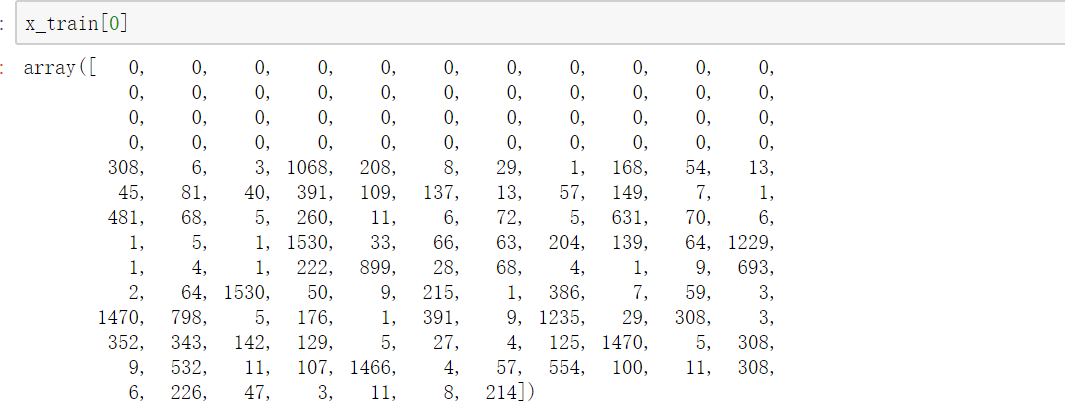
对每个词编码之后,每句影评中的每个词就可以用对应的编码表示,即每条影评已经转变成一个向量。但是,由于影评的长度不唯一,需要将每条影评的长度设置一个固定值。

每个句子的长度都固定为150,如果长度大于150,则将超过的部分截掉;如果小于150,则在最前面用0填充。每个句子如下:
4.使用Embedding层将每个词编码转换为词向量
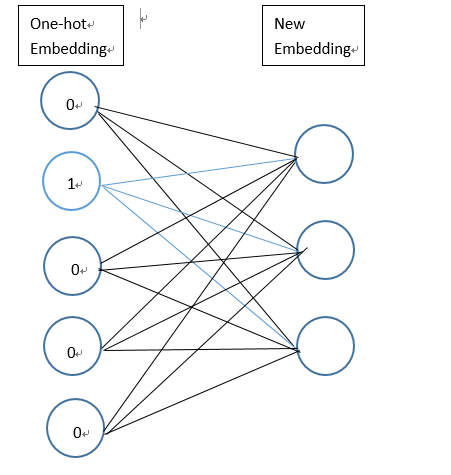
通过以上操作,已经将每个句子变成一个向量,但上文已经提及text-CNN的输入是一个数字矩阵,即每个影评样本应该是以一个矩阵,每一行代表一个词,因此,需要将词编码转换成词向量。使用Keras的Embedding层可以实现转换。Embedding层基于上文所得的词编码,对每个词进行one-hot编码,每个词都会以一个vocabulary_size(如上文的2000)维的向量;然后通过神经网络的训练迭代更新得到一个合适的权重矩阵(具体实现过程可以参考skip-gram模型),行大小为vocabulary_size,列大小为词向量的维度,将本来以one-hot编码的词向量映射到低维空间,得到低维词向量。比如the的编号为1,则对应的词向量为权重矩阵的第一行向量。如下图,蓝色线对应权重值组成了该词的词向量。需要声明一点的是Embedding层是作为模型的第一层,在训练模型的同时,得到该语料库的词向量。当然,也可以使用已经预训练好的词向量表示现有语料库中的词。
至此已经将文本数据预处理完毕,将每个影评样本转换为一个数字矩阵,矩阵的每一行表示一个词向量。下图梳理了处理文本数据的一般步骤。在此基础上,可以针对相应数据集的特点对数据集进行特定的处理。比如:在该数据集中影评可能含有一些html标签,我们可以使用正则表达式将这些标签去除。
下一篇文章,我们将介绍text-CNN模型,利用该模型对imdb数据集进行情感分析,并在文末给出整个项目的完整代码链接。欢迎持续关注!