介绍
我是个超级板球迷。从我记事起,我就迷上了这项运动,至今它仍在我的日常生活中起着重要的作用。我相信很多读到这篇文章的人都会点头!
但是自从我开始工作以来,要跟上所有的比赛就成了一件棘手的事。我不能看一场完整的比赛,只能看一些短暂的片段,或者看文字解说。
所以作为数据科学家的我决定做点什么。有没有一种方法可以让我使用我的Python技能并剪辑出比赛的所有重要部分?实际上,我想用Python创建我自己的集锦集合。
事实证明,我甚至不需要依靠机器学习或深度学习技术来做到这一点!现在,我想分享我的代码,在后面附有代码。这将让你尝试我们将在这篇文章中使用的一个简单的语音分析方法:
我将讨论我如何编写这个集锦生成的处理流程,使你可以学习和应用到任何比赛(或任何你想要的其他运动)。
目录
- 体育视频集锦简介
- 集锦生成的不同方法
- 我自己生成集锦的方法
- 理解问题描述
- 在Python中实现集锦生成
体育视频集锦简介
我们都看过一些体育比赛的精彩部分。即使你对运动没有兴趣,你也会在餐馆、酒店等地方看到电视上的精彩镜头。
集锦生成是从体育视频中提取最有趣的部分的剪辑的过程。
你可以将其视为视频摘要的经典用例。在视频摘要中,全长视频将转换为较短的格式,以便保留最重要的内容。
在板球比赛中,完整的比赛视频包含了四分打、六分打、三柱门等动作。未经过剪辑的版本会捕捉一些无趣的事件,如防御、离场、歪球、失误点等。
另一方面,集锦是人们肾上腺素激增的开始。所有主要的视频集锦,例如四分打、六分打、三柱门,这些结合在一起就构成了典型的集锦组合。

从一场完整的比赛视频中手动提取集锦需要大量的人工。这是一项耗时的工作,除非你想日复一日地从事这项工作,否则你需要找到其他方法。
存储一场完整的比赛视频也占用大量资源。因此,一场完整的比赛视频中自动提取集锦可以为创作者和用户节省大量时间。这就是我们将在本文中讨论的内容。
集锦生成的不同方法
除了手动方法之外,我们还有其他方法可以生成集锦。我们可以使用两种常见的方法-自然语言处理(NLP)和计算机视觉。在开始使用我的方法之前,让我们简要讨论一下它们如何工作。
基于自然语言处理(NLP)的方法
在查看以下步骤之前,请先考虑一下。你如何使用NLP或基于文本的方法从板球比赛中提取重要的数据?
以下是流程:
- 从输入视频中提取音频
- 将音频转录为文本
- 对文本应用基于提取的摘要技术来识别最重要的短语
- 提取相应重要短语的片段,生成集锦
基于计算机视觉的方法
这种基于计算机视觉的方法会给人一种非常直观的印象。毕竟,计算机视觉是我们训练机器看图像和视频的领域。因此,使用计算机视觉生成集锦的一种方法是一直跟踪比赛的记分卡,只有在出四分打、六分打、三柱门时才进行提取。
我自己生成集锦的方法
在这一点上,你可能想知道,我们刚才谈到了机器学习和深度学习的两个子领域。但是文章的标题和介绍表明我们不会使用这两个领域。那么我们真的可以在不构建模型的情况下生成集锦吗?是的!
“并非每个问题都需要深度学习和机器学习。对领域和数据的透彻理解可以解决大多数问题。” – Sunil Ray
我将讨论使用自动生成的集锦的概念——简易语音分析(Simple Speech Analysis)。在讨论最终方法之前,让我们讨论一些术语。
什么是短时能量?
我们可以在时域或频域中分析音频信号。在时域中,针对时间分量分析音频信号,而在频域中,针对频率分量进行分析:
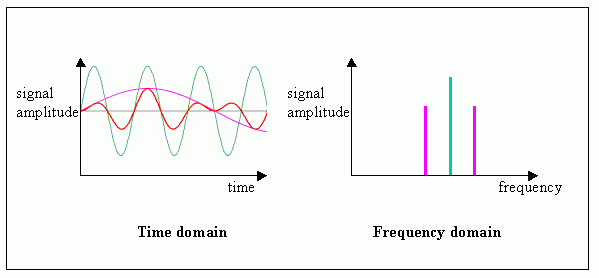
音频信号的能量是指声音的响度。它是由时域中音频信号幅度的平方和求出的。当为整个音频信号的一部分计算能量时,则称为短时能量。
解决方案背后的基本思想是,在大多数体育比赛中,每当发生有趣的事件时,评论员和观众的声音都会增加。
让我们以板球为例。每当击球手击中界线或投球手取球时,评论员的声音就会上升。观众的欢呼声就开始爆发。我们可以使用音频中的这些更改来捕捉视频中有趣的时刻。
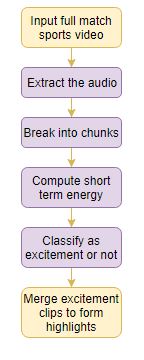
以下是流程:
- 输入完整匹配的视频
- 提取音频
- 将音频分成块
- 计算每个块的短时能量
- 将每个块归为是否"兴奋"(简单的基于阈值)
- 合并所有"兴奋"片段,以形成视频集锦
理解问题描述
板球运动是印度最著名的运动,在印度几乎所有地区都可以玩。因此,作为顽固的板球迷,我决定自动从完整比赛的板球视频中提取集锦。但是,相同的想法也可以应用于其他运动。
在本文中,我只考虑了2007年T20世界杯印度对澳大利亚半决赛的前6轮。你可以在YouTube上观看完整的比赛(https://www.youtube.com/watch?v=lFq4eW9ewRE&t=2162s),并从这里下载前六场的视频(https://drive.google.com/drive/folders/1FRODSq1dgp-JvUcXRALKjn6bvIu15gU6)。
在Python中实现集锦生成
我已经借助名为WavePad Audio Editor的软件从视频中提取了音频。你可以从此处下载音频剪辑(https://drive.google.com/drive/folders/1FRODSq1dgp-JvUcXRALKjn6bvIu15gU6)。
filename='powerplay.wav'
import librosa
x, sr = librosa.load(filename,sr=16000)我们可以使用以下代码以分钟为单位获取音频剪辑的持续时间:
int(librosa.get_duration(x, sr)/60)现在,由于我们有兴趣找出特定的音频块是否包含音频声音的上升,因此将音频分为5秒的块:
max_slice=5
window_length = max_slice * sr让我们听一听音频块:
import IPython.display as ipd
a=x[21*window_length:22*window_length]
ipd.Audio(a, rate=sr)计算块的能量:
energy = sum(abs(a**2))
print(energy)在时间序列域中可视化块:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(14, 8))
ax1 = fig.add_subplot(211)
ax1.set_xlabel('time')
ax1.set_ylabel('Amplitude')
ax1.plot(a)
如我们所见,信号幅度随时间变化。接下来,为每个块分配短期能量:
import numpy as np
energy = np.array([sum(abs(x[i:i window_length]**2)) for i in range(0, len(x), window_length)])让我们查看这些块的短时能量分布:
import matplotlib.pyplot as plt
plt.hist(energy)
plt.show()
如上图所示,能量分布是右偏的。我们将选择极值作为阈值,因为仅当评论者的讲话和观众的欢呼声很高时,我们才对剪辑感兴趣。
在这里,我认为阈值是12,000,因为它位于分布的尾部。随意尝试不同的值,看看会得到什么结果。
import pandas as pd
df=pd.DataFrame(columns=['energy','start','end'])
thresh=12000
row_index=0
for i in range(len(energy)):
value=energy[i]
if(value>=thresh):
i=np.where(energy == value)[0]
df.loc[row_index,'energy']=value
df.loc[row_index,'start']=i[0] * 5
df.loc[row_index,'end']=(i[0] 1) * 5
row_index= row_index 1将相连的时间间隔的连续音频片段合并为一个:
temp=[]
i=0
j=0
n=len(df) - 2
m=len(df) - 1
while(i<=n):
j=i 1
while(j<=m):
if(df['end'][i] == df['start'][j]):
df.loc[i,'end'] = df.loc[j,'end']
temp.append(j)
j=j 1
else:
i=j
break
df.drop(temp,axis=0,inplace=True)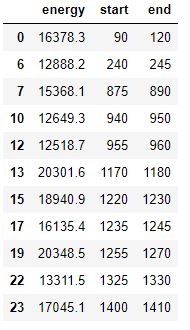
在特定时间间隔内提取视频以形成集锦。 切记,由于只有在击球手打完球之后,评论员的讲话和观众的欢呼才会增加,所以我考虑了每个“兴奋”的片段之前五秒:
from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
start=np.array(df['start'])
end=np.array(df['end'])
for i in range(len(df)):
if(i!=0):
start_lim = start[i] - 5
else:
start_lim = start[i]
end_lim = end[i]
filename="highlight" str(i 1) ".mp4"
ffmpeg_extract_subclip("powerplay.mp4",start_lim,end_lim,targetname=filename)我已经使用在线视频编辑器来合并所有提取的视频剪辑成单个视频。
恭喜你生成了你自己的集锦集合!继续将此技术应用于你想要的任何比赛或运动吧。它可能看起来很简单,但是它是一种强大的方法。这里有完整代码(https://github.com/aravindpai/Cricket-Highlights-Generation)
结尾
本文的关键结论是:在进入模型构建过程之前,要对领域和数据有一个全面的了解,因为它可以帮助我们更好地解决大多数问题。
在本文中,我们了解了如何使用简单的语音分析来自动提取一场完整体育比赛视频中的集锦。我建议你也尝试不同的运动。
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/