一、背景
在使用过程某些操作步骤与其相邻步骤存在一定的依赖关系,需要需要将上一个请求的响应结果作为下一个请求的参数。
Jmeter中后置处理器正则表达式提取器和XPath Extractor都可以将页面上置顶内容获取并保存到一个参数中。
所以可通过两步骤实现上面的需求:
①能够将返回页面上的指定内容保存在参数中;
②能够将GET或POST方法中的数据使用该参数来替换;
二、正则表达式提取器和XPath Extractor的区别
XPath Extractor的使用方法与正则表达式提取器(Regular Expression Extractor)类似,只不过该Expression中指定的不是正则表达式,而是给定的XPath路径。
正则表达式提取器和XPath Extractor的区别:
①正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
②XPath Extractor则可以提取返回页面任意元素的任意属性;
③如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
④如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。
三、XPath Extractor界面及说明
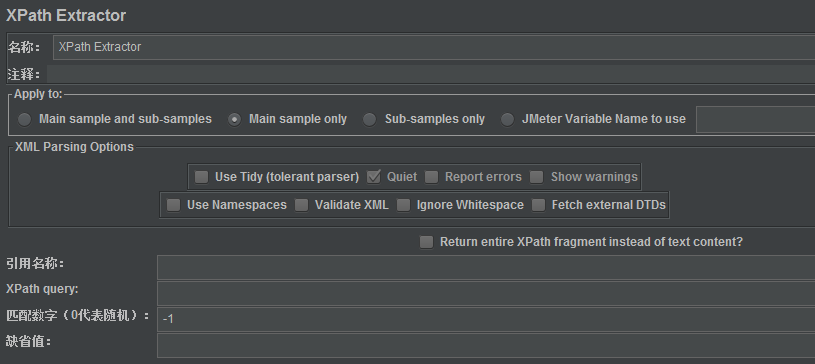
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet:表示只显示需要的HTML页面,
Report errors:表示显示响应报错,
Show warnings:表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name(引用名称):存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
Default Value(缺省值):参数的默认值。
四、使用实例
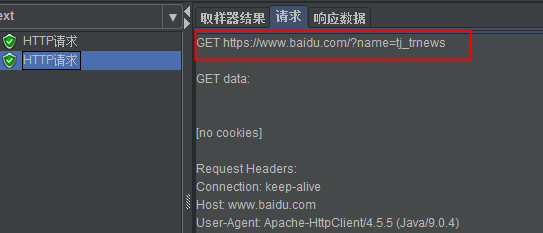
1、比如需要提取如下响应文本中的这个元素的属性name的值

2、设置XPath Extractor

3、引用提取出来的值
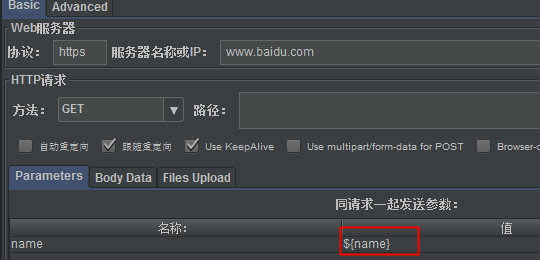
4、执行结果