1. Why NoSQL
1.1 单机版本
前提:网站访问量不大的时候,单机版的数据库足够
思考(应用瓶颈),出现如下三种情况之一,架构必须要升级:
1. 数据量太大,单个数据库无法存放
2. 数据索引(单表数据量大于300W,一定要建立索引)索引太大内存无法存放;
3. 访问量(读写混写)单个数据库扛不住峰值
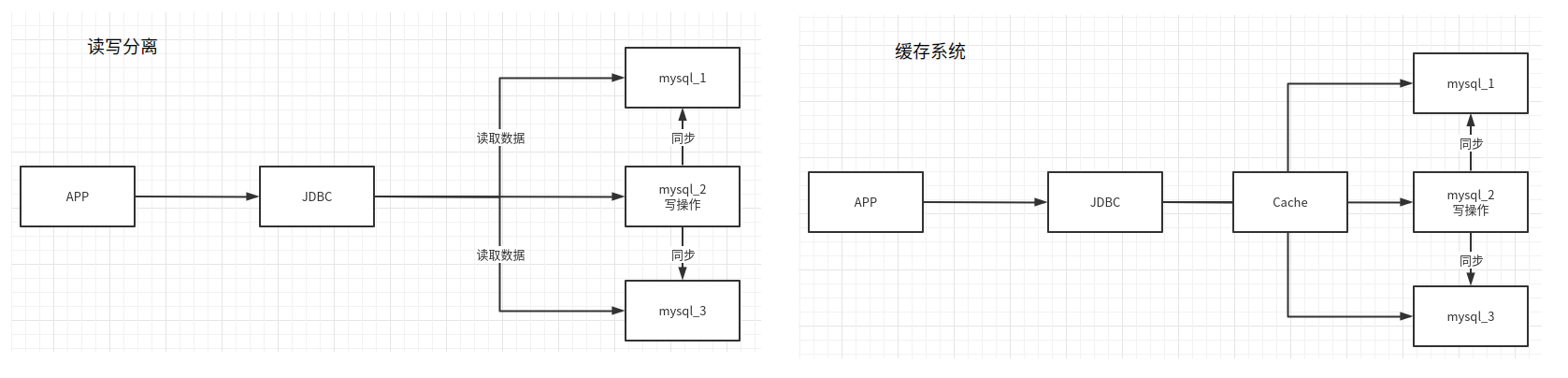
1.2 缓存&读写分离版本
Memcached(缓存)+ MySQL + 垂直拆分(读写分离)
分析发展过程:优化数据结构和索引==>文件缓存(IO)==>Memcache
1. 早期在没有MyCat等数据库中间件的时候,3个MySQL实例会有数据同步的问题,可以同时冗余三分一模一样的数据
2. 引入另外一种策略(读写分离),3个实例:一个负责写操作,两外两个负责读,并增加同步机制;
3. 针对频查询的数据,增加缓存机制,减轻数据库压力
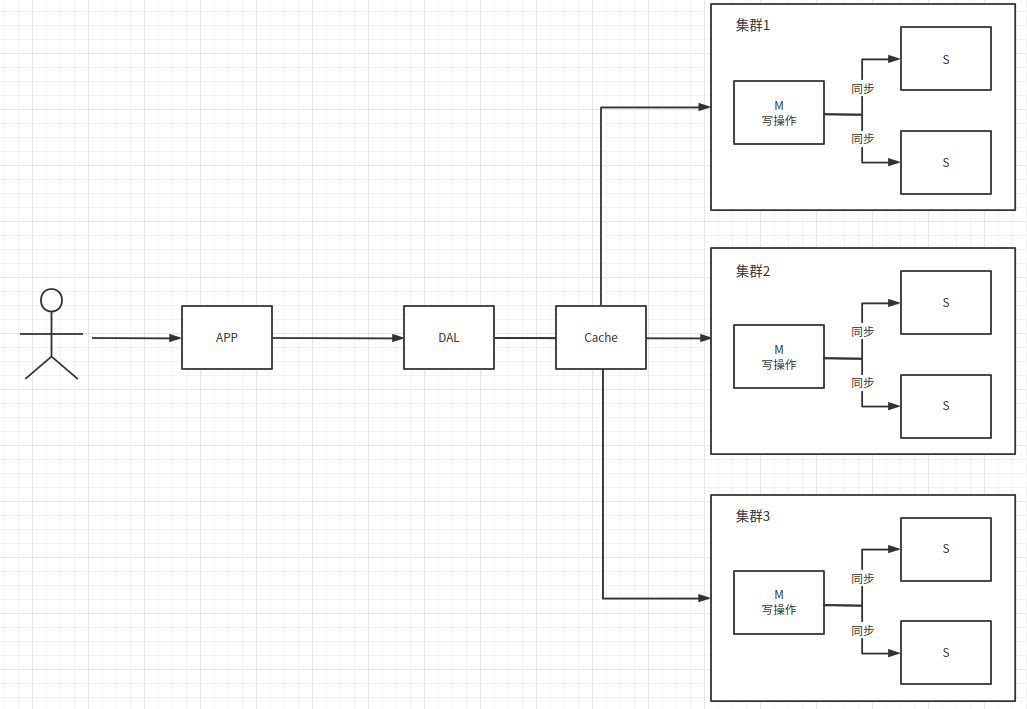
1.3 分库分表&集群版本
分库分表 + 水平拆分(MySQL集群)
早期MyISM:表锁,查询表中的一条记录会锁住整张表,效率低下,高并发下会出现严重的锁问题
转战Innodb:查询时行锁,锁一行数据
分库分表解决写的压力,分表(根据不同的字段拆分大表)
1.4 SQL瓶颈
如今的时代
1.定位+音乐+热榜+图片数据的存储不适用于关系型MySQL数据库,效率低下 ===>NoSQL
2.大数据量的IO下,表结构几乎无法修改
2. What‘s NoSQL
2.1 NoSQL分类&特点
## NoSQL四大分类:
1.KV键值对:Redis、Memcache
2.文档型数据库:MongoDB、ConthDB
3.列存储数据库:HBase、分布式文件系统
4.图数据库:Neo4j、InfoGrid A*,最短路径算法
## NoSQL特点:
1. 方便扩展(数据之间没有关系)
2. 大数据量,高性能(Redis一秒写8W次,一秒读11W)
3. 数据类型多样,不需要设计数据库
2.2 RDBMS和NoSQL区别
SQL
- 数据和关系维护在单独的表中
- 数据定义语言
- 严格的一致性
- 基础的事务
NoSQL
- 键值对存储数据、列存储、文档存储、图形数据库
- 最终一致性
- CAP定理和BASE理论
- 保证三高特性【高性能,高可用,高可扩展】
3. 拓展
大数据时代的3V(描述问题):海量,多样,实时
大数据时代的3高(程序要求):高并发、高可拓(可随时拓展集群)、高性能(保证用户体验和性能)
实际项目:NoSQL+RDBMS配合使用