def YuSu(self): #语速设置 f = wave.open(r"test.wav", "rb") # 读取格式信息 # (nchannels, sampwidth, framerate, nframes, comptype, compname) params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] # 读取波形数据 str_data = f.readframes(nframes) f.close() # 将波形数据转换为数组 wave_data = np.fromstring(str_data, dtype=np.short) time = np.arange(0, nframes) * (1.0 / framerate) # 要通过我们设定的名字来调用这些组件 # price_box.toPlainText() 是一个内置的可以读取输入框中的值的函数。 # 通过函数读取到的是一个 string 类型的值,所以我们需要把他转换成 integer 类型并存在一个price 变量中 # price = int(self.price_box.toPlainText()) # value() 是读取spinbox 中值的函数 yusu = self.yusu_doubleSpinBox.value() # 语速设置 wave_data1 = wave_data.astype(np.short) f = wave.open(r"test_yusu.wav", "wb") # 配置声道数、量化位数和取样频率 f.setnchannels(1) f.setsampwidth(2) f.setframerate(yusu * framerate) #改变采样率 # 将wav_data转换为二进制数据写入文件 f.writeframes(wave_data1.tostring()) f.close() chunk = 1024 f = wave.open(r"test_yusu.wav", "rb") p = pyaudio.PyAudio() # 打开声音输出流 stream = p.open(format=p.get_format_from_width(f.getsampwidth()), channels=f.getnchannels(), rate=f.getframerate(), output=True) # 写声音输出流进行播放 while True: data = f.readframes(chunk) if data == "": break stream.write(data) stream.close() p.terminate() f = wave.open(r"test_yusu.wav", "rb") # 读取格式信息 # (nchannels, sampwidth, framerate, nframes, comptype, compname) params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] # 读取波形数据 str_data = f.readframes(nframes) f.close() # 将波形数据转换为数组 wave_data = np.fromstring(str_data, dtype=np.short) time = np.arange(0, nframes) * (1.0 / framerate) self.curve2.setData(time, wave_data) self.curve2.attach(self.qwtPlot_2) self.qwtPlot_2.replot()
回声添加,两种方法:叠加法和滤波法
def HuiSheng(self): f = wave.open(r"test.wav", "rb") # 读取格式信息 # (nchannels, sampwidth, framerate, nframes, comptype, compname) params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] # 读取波形数据 str_data = f.readframes(nframes) f.close() # 将波形数据转换为数组 wave_data = np.fromstring(str_data, dtype=np.short) time = np.arange(0, nframes) * (1.0 / framerate) huisheng = self.huisheng_spinBox.value() # 滤波,一次回声 b1 = np.array([1]) b2 = np.zeros([1, 6000]) b3 = np.array([0.7]) b = np.append(b1, b2) b = np.append(b, b3) a = 1 wave_data = np.append(wave_data, np.zeros([1, nframes])) wave_filter = signal.lfilter(b, a, wave_data) # 写Wave文件 # t = np.arange(0,np.max(time)*2,1.0/framerate) # 打开WAV文档 wave_filter = wave_filter.astype(np.short) f = wave.open(r"test_huisheng.wav", "wb") # 配置声道数、量化位数和取样频率 f.setnchannels(1) f.setsampwidth(2) f.setframerate(framerate) # 将wav_data转换为二进制数据写入文件 f.writeframes(wave_filter.tostring()) f.close() # 播放声音 chunk = 1024 f = wave.open(r"test_huisheng.wav", "rb") p = pyaudio.PyAudio() # 打开声音输出流 stream = p.open(format=p.get_format_from_width(f.getsampwidth()), channels=f.getnchannels(), rate=f.getframerate(), output=True) # 写声音输出流进行播放 while True: data = f.readframes(chunk) if data == "": break stream.write(data) stream.close() p.terminate() f = wave.open(r"test_huisheng.wav", "rb") # 读取格式信息 # (nchannels, sampwidth, framerate, nframes, comptype, compname) params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] # 读取波形数据 str_data = f.readframes(nframes) f.close() # 将波形数据转换为数组 wave_data = np.fromstring(str_data, dtype=np.short) time = np.arange(0, nframes) * (1.0 / framerate) self.curve2.setData(time, wave_data) self.curve2.attach(self.qwtPlot_2) self.qwtPlot_2.replot()
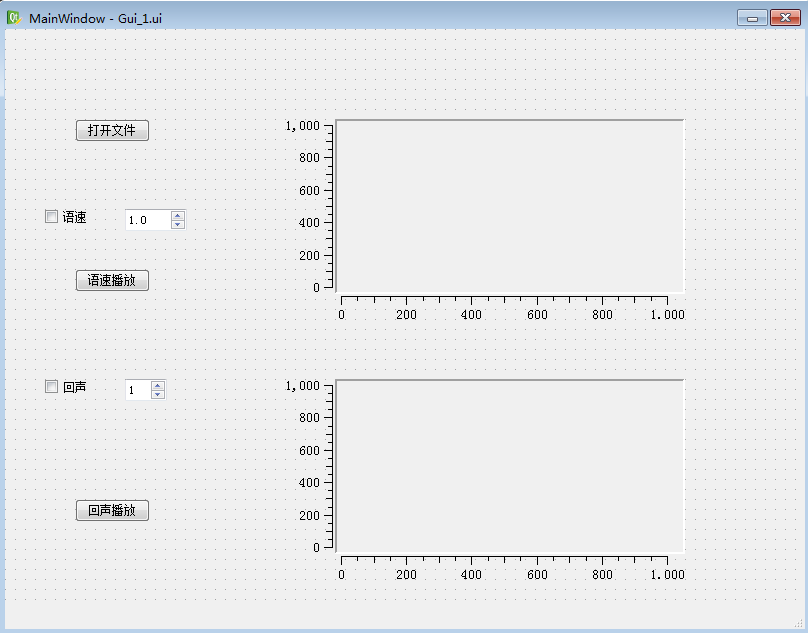
界面: