Introduction
现有主流方法采用了复杂的骨干网络,参数量大,处理速度慢。因此本文的目标是构建一个计算效率更高、更适合ReID的轻量级网络。
Neural Architecture Search(NAS)被利用来搜索轻量高效的网络,但一般需要非常高昂的计算资源,Differentiable architecture search的利用又大大降低了搜索成本,却依然存在以下瓶颈:1) cell之间包含复杂链接,不规则的cell结构不利于GPU运算;2) 没有区分不同层次的结构,而作者认为CNN需要级联不同深度的模式信息;3) 为了避免贡献非常低的分支在前向传播时也被计算,现有方法在两个节点中只计算了权重大的分支,而这个方法容易陷入局部最优。此外,作者发现,现有所搜空间不能学习ReID的组合模式特征,如下图所示。(对NAS不够了解,这部分不是很理解)

作者提出了一个新的搜索空间称为Combined Depth Sapce(CDS)和一个新的搜索策略称为Top-k Sample Search。在CDS中,设计了一个高效的Combind Block(CBlock),其包含了两个独立分支来学习组合模式特征。此外,Top-k Sample Search依据前向传播时的权重计算前k个分支,避免了可忽略计算的分支以及陷入局部最优。且在每个阶段独立搜索cell。在训练阶段,进一步提出一个简单高效的Balance Neck(BLNeck)来解决交叉熵和三元组损失的训练目标不一致。引入局部条纹思想,得到Fine-grained Balance Neck(FBLNeck)进一步提高性能。
Methodology
(1) Combined Depth Space:
① CBlock:
作者采用Lite 3x3作为最基础的block;Lite k表示将Lite kxk替换为![]() 个Lite 3x3以减少参数量;CBlock采用了双分支Lite结构,设置组合为
个Lite 3x3以减少参数量;CBlock采用了双分支Lite结构,设置组合为![]() ,
,![]() ,由此得到6中CBlock。如下图所示:
,由此得到6中CBlock。如下图所示:

定义将x输入到卷积核为k的Lite中,计算过程为:
![]()
op o t意思为op的过程重复t次.
两个Lite分支的融合过程引入了Adaptive Fusion Gate,在通道维度进行加权求和,最终通过1x1卷积恢复特征图尺寸。
② MBlock:
MBlock整合了上述CK中的6个不同卷积核尺寸的CBlock,每个分支赋予一个权重,表示该分支的重要性。
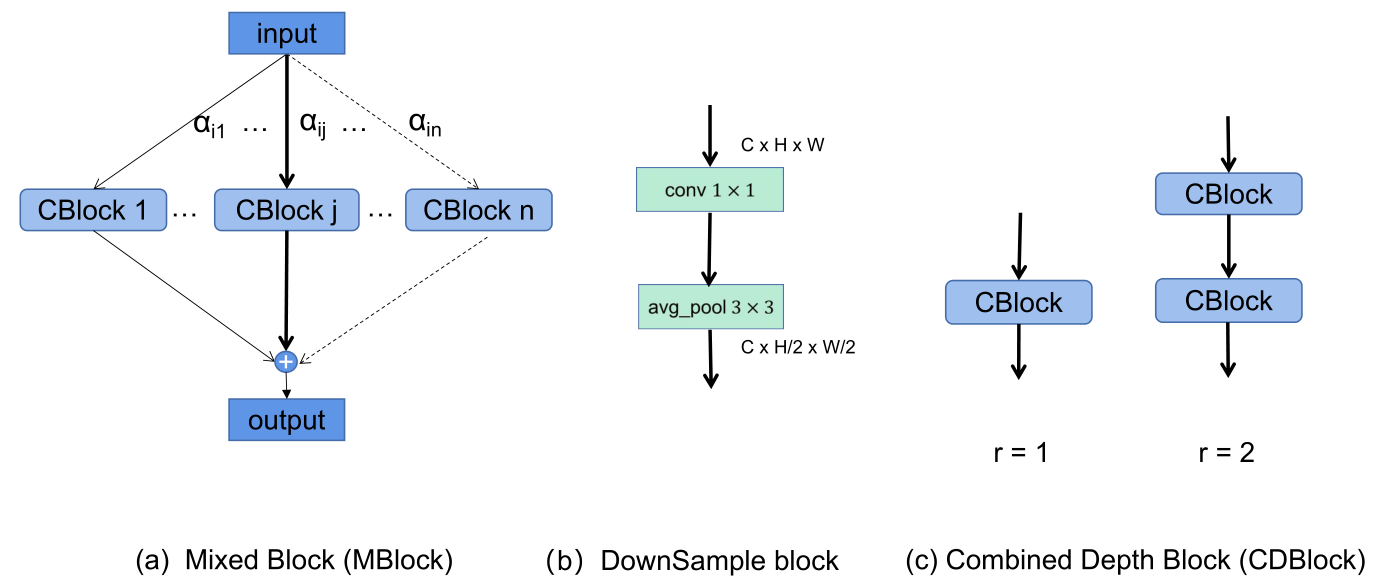
作者认为不同深度的网络模块会关注不同的信息,因此设计了一个宏观的框架,对不同深度的网络独立进行搜索。在开头采用了一个卷积stem,包含了一个7x7(stride=2)卷积和一个最大池化层(stride=2),整体氛围3个阶段,每个阶段包含2个MBlock:
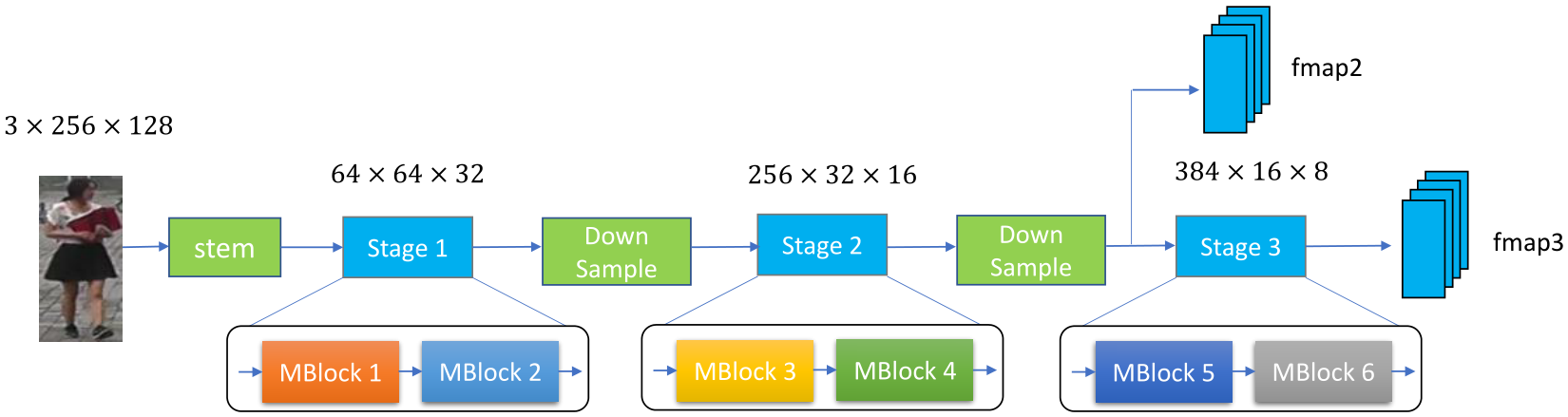
上述搜索空间称为Combined Space(CS),该搜索框架称为CNet,由于每个MBlock有6个候选分支,因此搜索空间大小为![]() 。
。
③ CDBlock:
为了有效地加深网络,作者认为应该在每个阶段分配适量的MBlock,而不是随机或者均匀分配。因此作者引入了depth factor到CS中,新的搜索空间为DCS,![]()
![]()
![]() ,
,![]() ,其中r表示CBlock重复次数。新的搜索空间大小为:
,其中r表示CBlock重复次数。新的搜索空间大小为:![]() 。
。
(2) Top-k Sample Search:
对于一个MBlock,定义6个MBlock权重为![]()
![]() ,CS每个分支有6种选择,CDS每个分支有12种选择,即对应
,CS每个分支有6种选择,CDS每个分支有12种选择,即对应![]() 的维数。因此,任务的目标为:
的维数。因此,任务的目标为:
![]()
其中w为搜索网络,![]() 为validation loss,
为validation loss,![]() 为training loss。训练时,先用训练集更新w,再用验证集更新α。
为training loss。训练时,先用训练集更新w,再用验证集更新α。
在搜索过程中,仅计算权重排名前k个分支。定义第i个MBlock前向传播为![]() ,定义MBlock的第j个分支为
,定义MBlock的第j个分支为![]() ,定义分支数量为n,则MBlock的各个分支的概率分布为
,定义分支数量为n,则MBlock的各个分支的概率分布为![]()
![]() :
:
![]()
之后定义一个二进制向量![]() ,如果第j个分支权重位于前k名,则设置为1,即:
,如果第j个分支权重位于前k名,则设置为1,即:
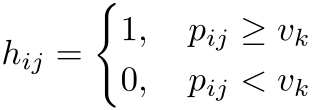
则前向传播计算为:

由于h值为0/1离散值,无法进行反向传播,因此设计如下计算:

其中带*的参数表示复制的不带梯度的变量,其梯度计算为:
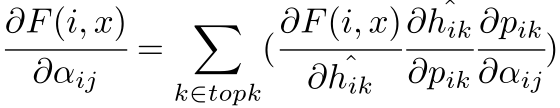

(3) Fine-grained Balance Neck:
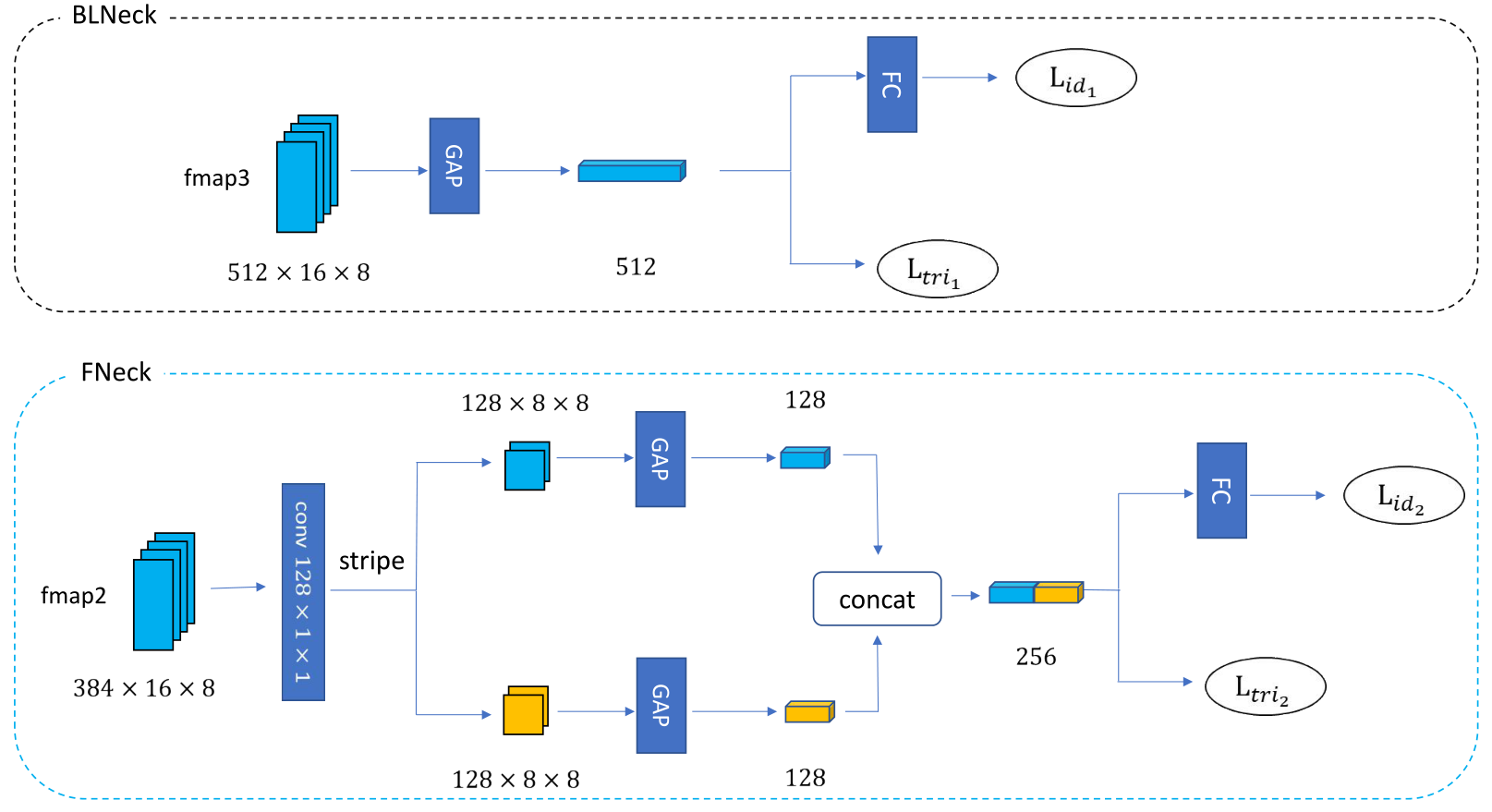
对浅层特征采用分块策略,对深层特征采用全局策略。注意在ID损失前增加了FC层,将适合三元组的映射空间转到适合softmax的映射空间。
Experiments
