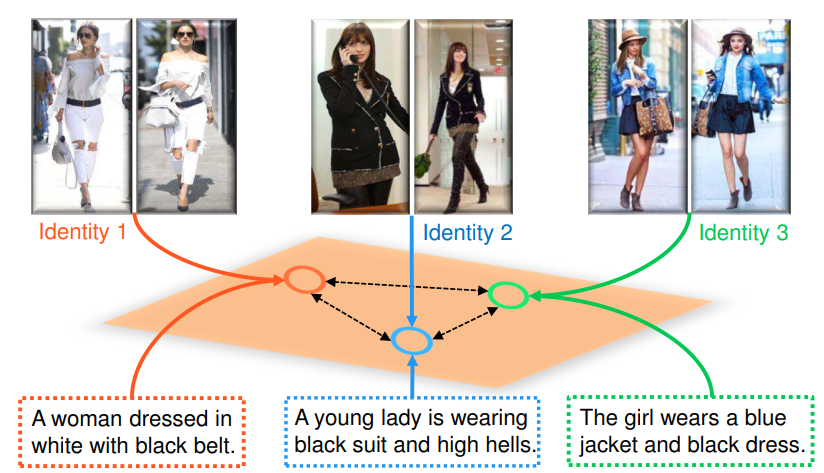
Introduction
本文提出了一个两阶段的identity-aware图文匹配框架:
第一阶段通过引入Cross-Modal Cross Entropy (CMCE) 损失来学习identity-aware特征表示。训练得到初始的匹配结果。但作者认为第一阶段匹配的结果只是粗略的,图文特征不能紧密的匹配。因此设计第二阶段,引入了latent co-attention机制来对图像注意力和文本语义注意力联合训练。
Proposed Method
第一阶段的训练:
作者认为现有的pairwise分类损失和三元组max-margin损失存在这样的不足:
1) 当训练集有N个ID时,pairwise的训练样本规模为O(N²),对于挖掘难样本会比较困难;
2) 在评估阶段,计算损失的时间复杂度比较高。
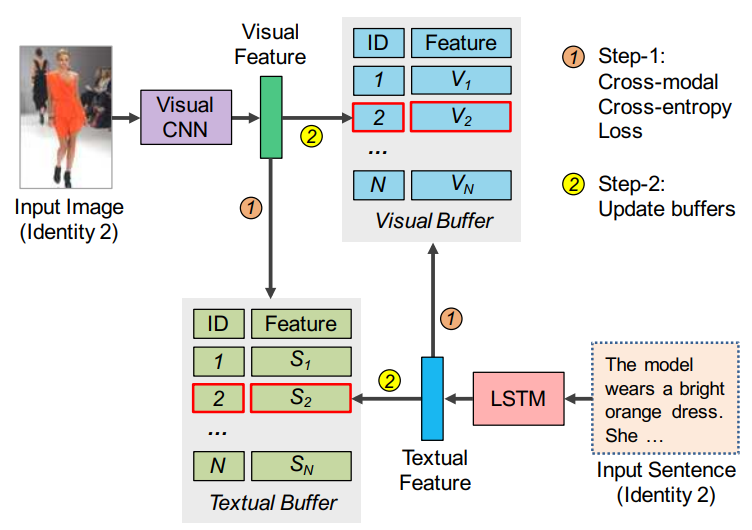
因此提出了CMCE损失:每次iteration,都把一个模态的n个ID的特征与另一个模态所有N个ID的特征进行比较,这n个ID的特征需要和另一个模态对应n个ID的特征具有较高的匹配度,和其余N-n个ID的特征具有较低的匹配度。匹配度的计算采用两种模态向量之间的内积。CMCE损失的复杂度为O(N).
图像特征![]() 和文本特征集
和文本特征集![]() 的匹配度计算为:
的匹配度计算为:
![]()
其中![]() 为控制峰值概率的超参数。
为控制峰值概率的超参数。
同理,文本特征和图像特征集的匹配度计算为:
![]()
则CMCE的损失函数为:
![]()
第二阶段的训练:

第一阶段训练得到的模型只能提取全局的特征,而这里的第二阶段精细化训练可以利用注意力机制捕捉局部细节特征。对于每个文本单词都通过Encoder LSTM提取特征,再通过空间注意力机制计算word-image特征,找到每个单词对应高注意力的局部。得到的输出再传入语义注意力模块中,再通过Decoder LSTM提取得到最终的特征。具体如下:
1) Encoder word-LSTM with spatial attention
LSTM编码的单词特征为:![]()
![]()
图像局部特征为:![]()
空间注意力权重计算为:

可以理解为分别用一个线性层投影图像、文本特征,相加后再次投影。加权得到新的图像特征: 。最后通过级联融合文本特征和图像特征,即:
。最后通过级联融合文本特征和图像特征,即:![]() 。
。
2) Decoder LSTM with latent semantic attention:
语义注意力模块的计算为:

其中 f 为重要性计算函数,包含了两层卷积网络。最后加权得到用于分类的特征:

采用交叉熵损失:
![]()
测试阶段:
对任意一个图像或者文本样本,通过第一阶段的模型,在另一个模态的数据中评估出前20个相似样本,再用第二阶段的模型进行二分类,进一步判断是否匹配。
Experiments
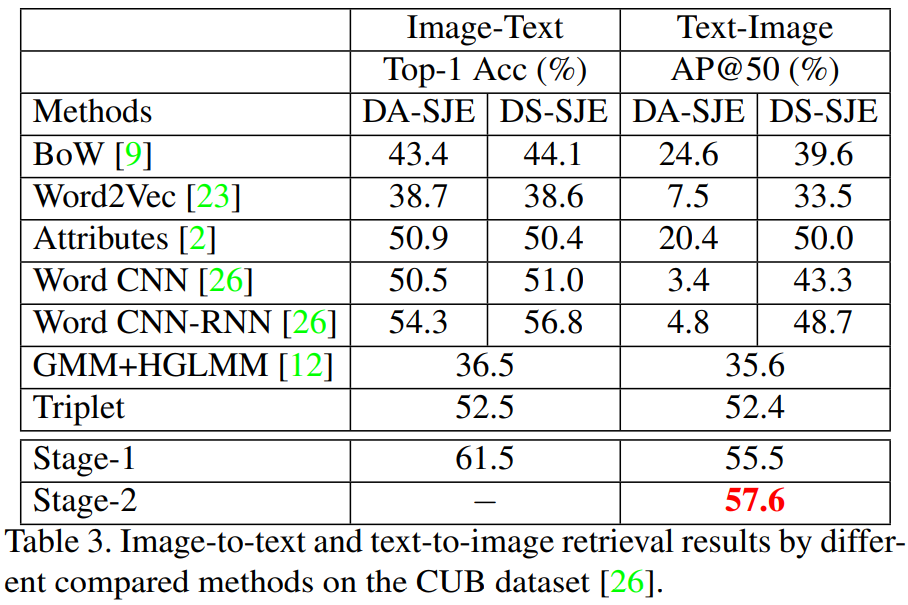
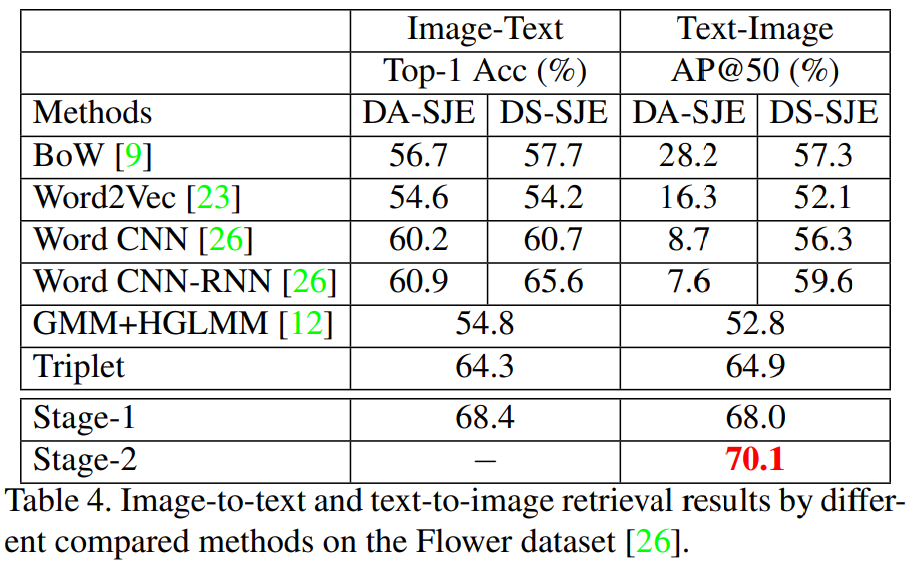
对于CUHK-PEDES任务选择了VGG-16作为CNN的backbone,对于CUB和Flower数据集选择了GoogleNet作为CNN的backbone。实验的参数具体看原文,设置比较复杂。实验结果如下: