Non-local neural networks(CVPR2018)
传统的卷积神经网络的感受野相对较小,比如3*3、5*5,但对于注意力机制而言,需要更大的感受野来获取全局的注意力得分,Nonlocal的目的就是计算全局感受野的注意力。Nonlocal的计算由相似度计算函数 f 和映射函数 g 组成,g 采用1x1卷积实现。可以理解为计算某一个node的全局的相似度映射,再与该node的映射相乘。【参考Gapeng知乎文章:传送门】
![]()

最终采用残差网络的形式作为一个block插入到网络结构中:

Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identification(BMVC2019)
本文的思路是将nonlocal模块嵌入到resnet50的结构中,提出了Non-local Video Attention Network(NVAN),在MARS数据集上的rank1达到了90%,但同时引入了很大的计算量,实用性较差。为了降低计算量,作者改进了NVAN,提出了Spatially and Temporally Efficient Non-local Video Attention Network(STE-NVAN),降低了72.7%的计算量,同时只降低了1.1%的准确率。
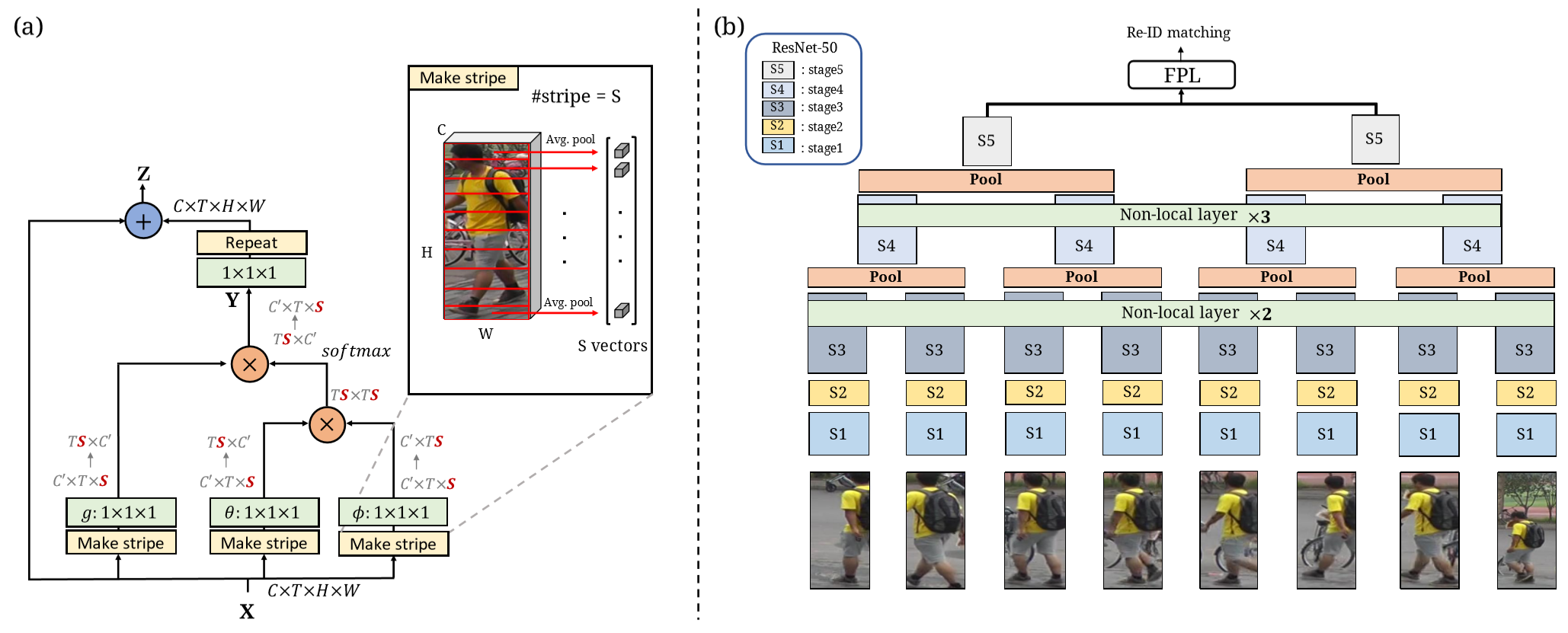
(1)NVAN的网络结构如下,其中Nonlocal模块采用了高斯映射。提取得到特征映射后,采用3D平均池化层(3DAP)在时空维度进行特征融合,获得特征向量。

(2)STE-NVAN的网络结构如下。首先空间上分块,将图像分为多块,默认同一块上的像素差异不是很大,所以块内不重复进行non-local计算,重点针对块间计算。在resnet s4之后,送入后面三层non-local层之前,将视频中相邻两帧的feature进行Pool融合,时间维度上减半。【参考知乎:传送门】