不上博客园有一段时间,回过头来翻看之前写的几篇博客,都是写了一半就丢了,又一次更深的认识自己的懒惰。
做大数据项目快三个月了,一个新的领域一边探索一边实现,特别有意思,现在回来梳理对Spark的认识。专题的资料来源是官网和网络上的博客,暂时还不会涉及对源码的阅读。这是专题的第一篇文章,写写我对Spark工作流的整体理解,接下来的专题内容会对工作流中的各个组成部分作探究,主要思路:
- 定义,即是什么?
- 为什么要在Spark中这么实现?
- 在Spark中是如何实现的?
- 如若涉及到调优,该如何调优?
首先,说明spark的一个application组成:
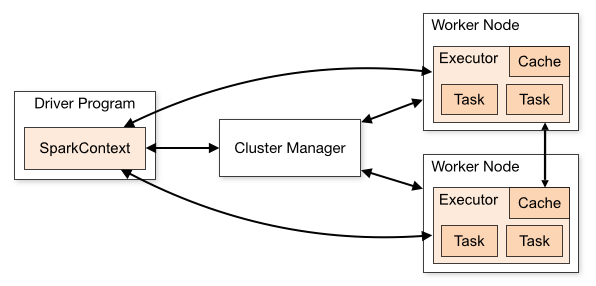
图1
这张是Spark集群工作图,负责调度的是Cluster Manager,一个Appliaction,即用户自己写的 Spark 程序(driver program),比如 WordCount.scala,它包含一个driver(驱动)和多个executor(执行器),其中:
- 驱动(driver)持有应用(SparkContext),为工作调度任务;
- 执行器(executor)独立于应用(SparkContext),在应用的持续时间内运行,执行应用的任务。
接着,看一个Application具体如何流转。

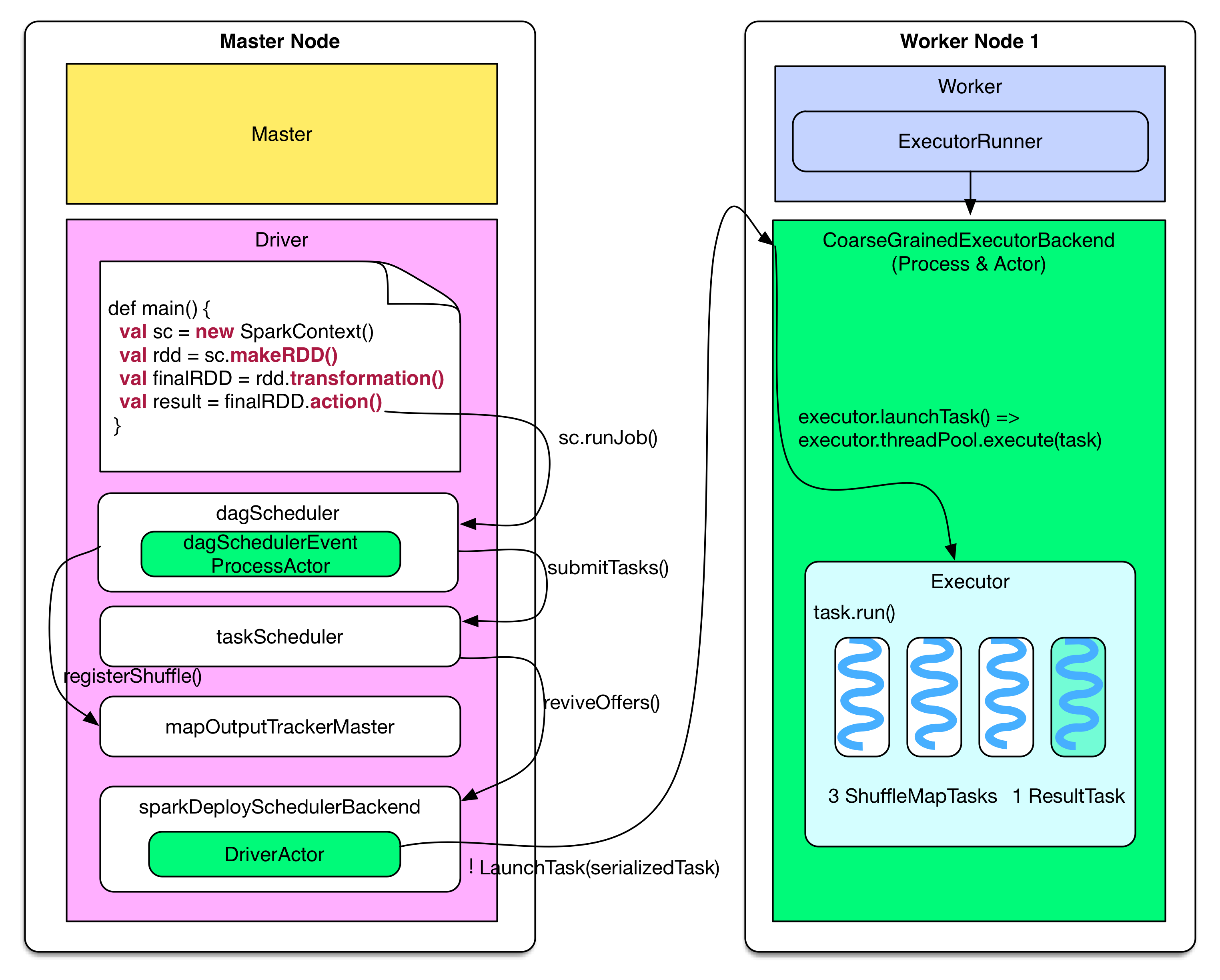
图2 图3
Application的工作流程分为Job提交和Task任务执行两个部分,对应图2、图3的左半图和右半图。Job提交具体的是每个stage的提交,其流程步骤如下:
- 根据rdd.transformation()操作建立 computing chain(一系列的 RDD),这是Job的逻辑执行图;
- 执行rdd.action(),调用SparkContext的runJob()方法,生成DAGScheduler;
- DAGScheduler运行自己的runJob()方法,生成stages【备注:可能生成多个stage】;
- 接着,DAGScheduler运行自己的submitStage()方法,在这个方法中,定义ShuffleMapTasks 或 ResultTasks任务,然后将任务打包到一个TaskSet,提交给taskScheduler这个任务调度器;
- sparkDeploySchedulerBackend 接收到TaskSet的任务后,会进行序列化,然后通过DriverActor发送给Worker节点Executor的CoarseGrainedExecutorBackend Actor【备注:一个 CoarseGrainedExecutorBackend 进程有且仅有一个 executor 对象】;
- 最后,Executor把task包装成taskRunner,每个taskRunner从线程池中抽取出一个空闲线程运行。
对于Task任务的执行流程,看一张图:
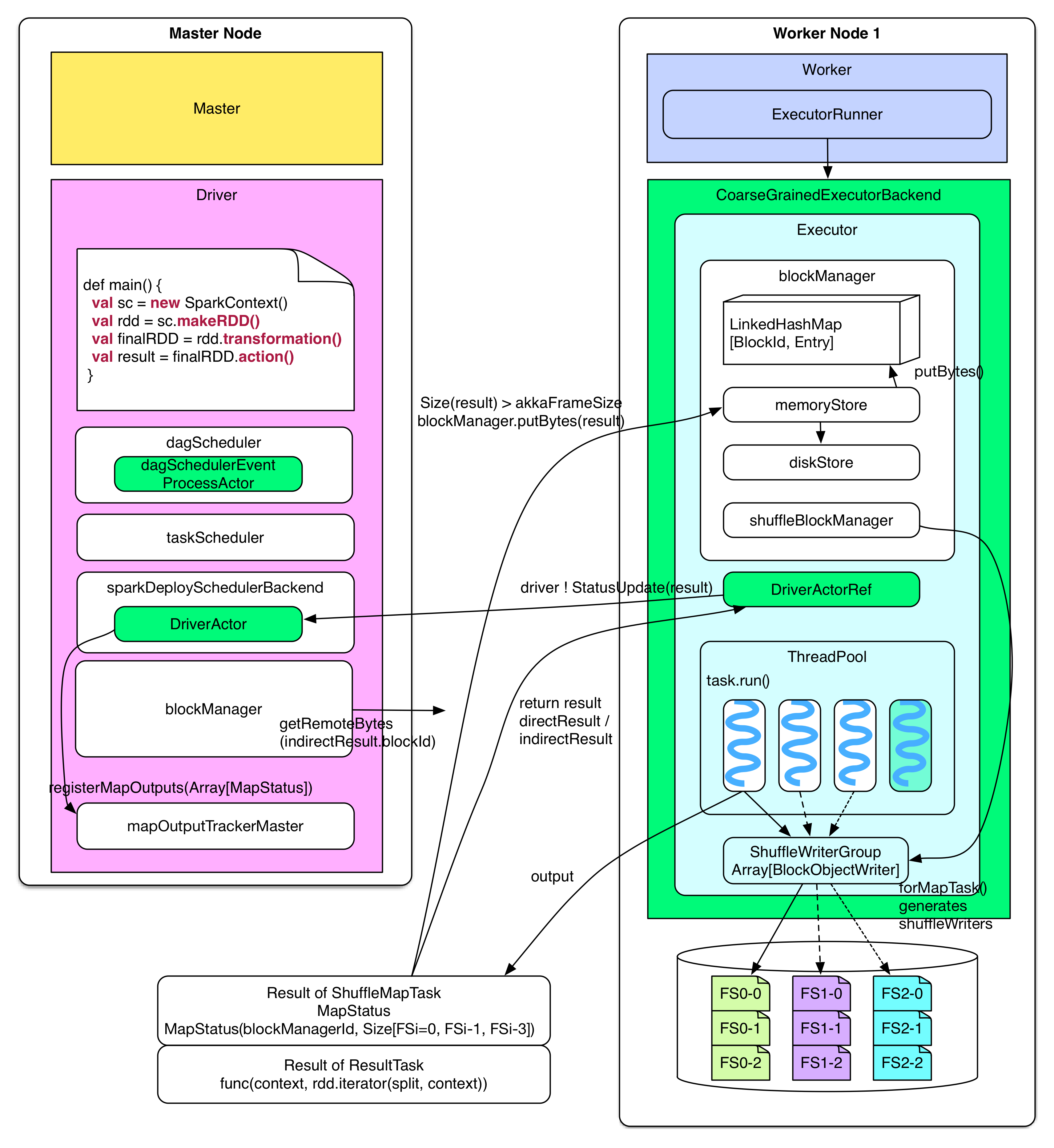
图4
Task任务执行的流程图具体步骤:
- Executor反序列化接收到的任务,运行任务返回结果directResult/indirectResult给driver:如果directResult比较小,直接返回给driver;否则将结果通过blockManager的“memory + hard disk”模式管理结果,返回给driver的只是包含存储任务运行结果位置的indirectResult,由driver通过HTTP主动拉取任务运行结果;【备注:是否直接返回任务运行结果的阈值属性设置为spark.akka.frameSize = 10MB】
- driver获得该task任务的计算结果result后,它会通知taskScheduler,任务已经处理完成,并分析结果;
- 如果计算结果result来自于ResultTask,在driver中通过resultHandler 统计这个result,如果是ShuffleMapTask这类结果,会存储到mapOutputTrackerMaster做下一步处理;
- 如果task任务是stage中的最后一个,那么开始提交下一个stage;
- 如果stage是一个job中的最后一个,则通知DAGScheduler这个job已经完成处理。
参考资料:https://github.com/JerryLead/SparkInternals/blob/master/markdown/english/5-Architecture.md