这个算法看得一知半解的,无论如何,先把理解的写下来,往后再迭代。还是以问题为导向:
- 这个分类模型如何构建?
- 这个模型是如何工作的?
- 如何求解模型的参数?
- 逻辑回归模型有什么优点?
第一个问题,对于简单的线性模型,t=wT·x+b,可以用它作回归,然后利用最小二乘法求解参数w和b。当这个线性模型和sigmoid函数复合时,就构成了逻辑回归模型。
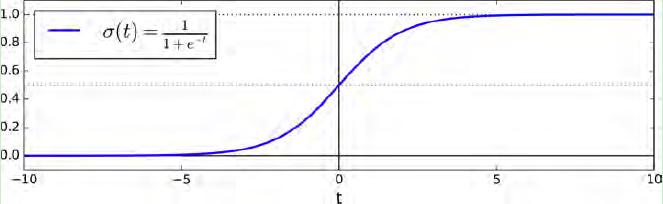
第二个问题,对于sigmoid函数σ(t),其作用是对于给定输入变量,根据选择的参数计算出输入变量x=1的可能性,如下图:其将t=wT·x+b值转化为一个接近于0或1的σ(t)函数值。当σ(t) < 0.5时,对应的分类标签为0;当σ(t) ≥ 0.5时,对应的标签为1 。
关于第三个问题,求解模型的参数主要是系数w和偏置b,如果构造这两个参数代价函数,不同的课程会给出不同的解释。其中Ng的机器学习视频和《Hands-On Machine Learning with Scikit-Learn and TersorFlow》这本书是直接给出代价函数的,而西瓜书和《统计学习方法》通过似然函数取对数似然函数,然后导出相同的代价函数。而求解代价函数的方法是梯度下降法或拟牛顿法。
因对似然函数不了解,特地在维基上查了相关知识点。