mysql的工作流程:
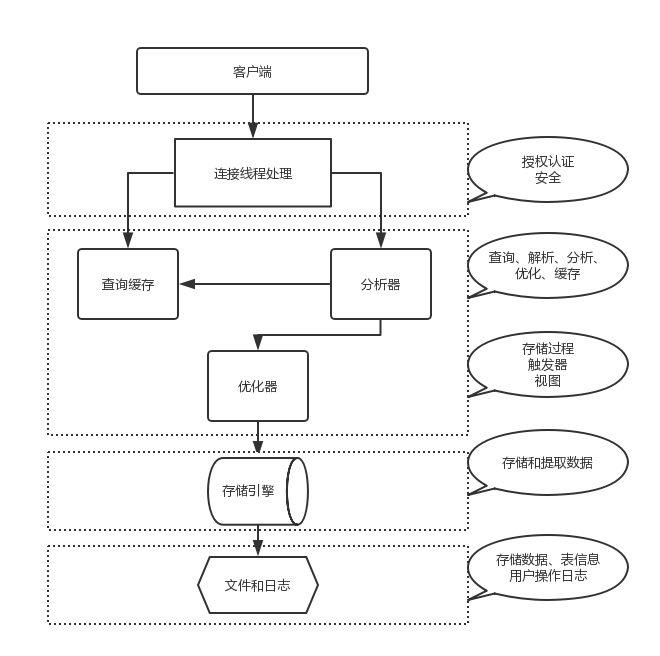
1.mysql 架构
mysql 分为 server 层和存储引擎
1.1.server层
连接器:管理连接权限验证
查询缓存:命中缓存直接换回查询结果
分析器:分析语法
优化器:生成执行计划,选择索引
执行器:操作索引返回结果
1.2. 存储引擎
存储引擎负责数据的存储和提取;其架构是插件式的。innodb 在 mysql5.5.5 版本开始成为 mysql 默认存储引擎。
各存储引擎比对:
InnoDB:支持事务,支持外键,InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据,不支持全文索引。
MyISAM:不支持事物,不支持外键,MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的,查询效率上 MyISAM 要高于 InnnDB ,因此做读写分离的时候一般选择用 InnoDB 做主机,MyISAM 做从机
Memory:有比较大的缺陷使用场景很少;文件数据都存储在内存中,如果 mysqld 进程发生异常,重启或关闭机器这些数据都会消失。
1.3.sql 的执行过程
第一步客户端连接上 mysql 数据库的连接器,连接器获取权限,维持管理连接;连接完成后如果你没有后续的指令这个连接就会处于空闲状态,如果太长时间不使用这个连接这个连接就会断开,这个空闲时长默认是 8 小时,由 wait_timeout 参数控制。
第二步你往 mysql 数据库发送了一条 sql ,这个时候查询缓存开始工作,看看之前有没有执行过这个 sql ,如果有则直接返回缓存数据到客户端,只要对表执行过更新操作缓存都会失效,因此一些很少更新的数据表可考虑使用数据库缓存,对频繁更新的表使用缓存反而弊大于利。使用缓存的方法如以下 sql ,通过 SQL_CACHE 来指定:
select SQL_CACHE * from table where xxx=xxx
第三步当未命中缓存的时候,分析器开始工作;分析器判断你是 select 还是 update 还是 insert ,分析你的语法是否正确。
第四步优化器根据你的表的索引和 sql 语句决定用哪个索引,决定 join 的顺序。
第五步执行器执行 sql ,调用存储引擎的接口,扫描遍历表或者插入更新数据。
2 mysql 日志
2.1 mysql 日志介绍
mysql 有两个重要日志—— redolog 和 binlog ,redolog 是独属于 innodb 的日志,binlog 则是属于 server 层的日志。下面介绍这两个日志有什么用:当我们更新数据库数据的时候,这两个日志文件也会被更新,记录数据库更新操作。
redolog 又称作重做日志,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。它在数据库重启恢复的时候被使用,innodb 利用这个日志恢复到数据库宕机前的状态,以此来保证数据的完整性。redolog 是物理日志,记录的是某个表的数据做了哪些修改,redolog 是固定大小的,也就是说后面的日志会覆盖前面的日志。
binlog 又称作归档日志,它记录了对 MySQL 数据库执行更改的所有操作,但是不包括 SELECT 和 SHOW 这类操作。binlog 是逻辑日志,记录的是某个表执行了哪些操作。binlog 是追加形式的写入日志,后面的日志不会被前面的覆盖。
2.2 数据更新过程
我们执行一个更新操作是这样的:读取对应的数据到内存—>更新数据—>写 redolog 日志—> redolog 状态为 prepare —>写 binlog 日志—>提交事务—> redolog 状态为 commit ,数据正式写入日志文件。我们发现 redolog 的提交方式为“两段式提交”,这样做的目的是为了数据恢复的时候确保数据恢复的准确性,因为数据恢复是通过备份的 binlog 来完成的,所以要确保 redolog 要和 binlog 一致。
6执行计划和慢查询日志
6.1 执行计划
在查询 sql 之前加上 explain 可查看该条 sql 的执行计划,如:
EXPLAIN SELECT * FROM table
这条 sql 会返回这样一个表:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | extra | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | simple |
这个表便是 sql 的执行计划,我们可以通过分析这个执行计划来知道我们 sql 的运行情况。现对各列进行解释:
1)id:查询中执行 select 子句或操作表的顺序。
2)select_type:查询中每个 select 子句的类型(简单 到复杂)包括:
-
-
-
SIMPLE:查询中不包含子查询或者UNION;
-
PRIMARY:查询中包含复杂的子部分;
-
SUBQUERY:在SELECT或WHERE列表中包含了子查询,该子查询被标记为SUBQUERY;
-
DERIVED:衍生,在FROM列表中包含的子查询被标记为DERIVED;
-
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;
-
UNION RESULT:从UNION表获取结果的SELECT被标记为UNION RESULT;
-
-
3) type:表示 MySQL 在表中找到所需行的方式,又称“访问类型”,包括:
-
-
-
ALL:Full Table Scan, MySQL 将遍历全表以找到匹配的行;
-
index:Full Index Scan,index 与 ALL 区别为 index 类型只遍历索引树;
-
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于 between < > 等查询;
-
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。常见于使用非唯一索引即唯一索引的非唯一前缀进行的查找;
-
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描;
-
onst 和 system:当 MySQL 对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于 where 列表中,MySQL 就能将该查询转换为一个常量,system 是 const 类型的特例,当查询的表只有一行的情况下, 使用 system;
-
NULL:MySQL 在优化过程中分解语句,执行时甚至不用访问表或索引。
-
-
4)possible_keys:指出 MySQL 能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。
5)key:显示 MySQL 在查询中实际使用的索引,若没有使用索引,显示为 NULL。
6)key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
7)ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
8)rows:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
9)Extra:其他重要信息 包括:
-
-
-
Using index:该值表示相应的 select 操作中使用了覆盖索引;
-
Using where:MySQL 将用 where 子句来过滤结果集;
-
Using temporary:表示 MySQL 需要使用临时表来存储结果集,常见于排序和分组查询;
-
Using filesort:MySQL 中无法利用索引完成的排序操作称为“文件排序”。
-
-
6.2 慢查询日志
mysql 支持慢查询日志功能—— mysql 会将查询时间过长的 sql 相关信息写入日志。这个查询时间阀值由参数 long_query_time 指定, long_query_time 的默认值为 10,运行 10S 以上的查询 sql 会被记录到慢查询日志中。默认情况下,Mysql 数据库并不启动慢查询日志,需要我们手动来设置这个参数。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
可通过以下 sql 查看慢查询日志是否开启:
show variables like '%slow_query_log%';
通过以下 sql 开启慢查询:
set global slow_query_log=1;
使用 sql 修改慢查询日志设置只对当前数据库生效,如果 MySQL 重启后则会失效。如果要永久生效,就必须修改配置文件 my.cnf。
通过以下 sql 查看修改慢查询的阈值:
show variables like 'long_query_time%';
et global long_query_time=4;
7 主从备份
7.1 主从备份原理
主从复制是指一台服务器充当主数据库服务器,另一台或多台服务器充当从数据库服务器,主服务器中的数据自动复制到从服务器之中。通过这种手段我们可以做到读写分离,主库写数据,从库读数据,从而提高数据库的可用。MySQL 主从复制涉及到三个线程,一个运行在主节点(log dump thread),其余两个(I/O thread, SQL thread)运行在从节点。
主节点 binary log dump 线程:
当从节点连接主节点时,主节点会创建一个 logdump 线程,用于发送 binlog 的内容。在读取 binlog 中的操作时,此线程会对主节点上的 binlog 加锁,当读取完成,甚至在发动给从节点之前,锁会被释放。
从节点I/O线程: 用于从库将主库的 binlog复制到本地的 relay log中,首先,从库库会先启动一个工作线程,称为IO工作线程,负责和主库建立一个普通的客户端连接。如果该进程追赶上了主库,它将进入睡眠状态,直到主库有新的事件产生通知它,他才会被唤醒,将接收到的事件记录到 relay log(中继日志)中。
从节点 SQL 线程:
SQL 线程负责读取 relay log 中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
7.2 主从备份延迟
主备延迟最直接的表现是,备库消费中继日志( relay log)的速度,比主库生产 binlog 的速度要慢。可能导致的原因有:
-
-
大事务,主库上必须等事务执行完成才会写入 binlog,再传给备库,当一个事物用时很久的时候,在从库上会因为这个事物的执行产生延迟。
-
从库压力大。
-
主备延迟当然是不好的,那么有哪些办法尽量减小主备延迟呢?有下面几个办法:
-
-
一主多从——多接几个从库,让这些从库来分担读的压力。这样方法适用于从库读压力大的时候。
-
通过 binlog 输出到外部系统,比如 Hadoop 这类系统,让外部系统提供统计类查询的能力
-
8 分布式事务
这里不再对分布式事物的概念做普及,直接介绍两种分布式事务: XA 分布式事务和 TCC 分布式事务。
8.1 XA 分布式事务
XA 是两阶段提交的强一致性事物。在 MySQL 5.7.7 版本中,Oracle 官方将 MySQL XA 一直存在的一个 “bug” 进行了修复,使得MySQL XA 的实现符合了分布式事务的标准。
XA 事务中的角色:
-
-
-
资源管理器(resource manager):用来管理系统资源,是通向事务资源的途径。数据库就是一种资源管理器。资源管理还应该具有管理事务提交或回滚的能力。
-
事务管理器(transaction manager):事务管理器是分布式事务的核心管理者。事务管理器与每个资源管理器(resource manager)进行通信,协调并完成事务的处理。事务的各个分支由唯一命名进行标识。
-
-
XA 规范的基础是两阶段提交协议:
在第一阶段,交易中间件请求所有相关数据库准备提交(预提交)各自的事务分支,以确认是否所有相关数据库都可以提交各自的事务分支。当某一数据库收到预提交后,如果可以提交属于自己的事务分支,则将自己在该事务分支中所做的操作固定记录下来,并给交易中间件一个同意提交的应答,此时数据库将不能再在该事务分支中加入任何操作,但此时数据库并没有真正提交该事务,数据库对共享资源的操作还未释放(处于锁定状态)。如果由于某种原因数据库无法提交属于自己的事务分支,它将回滚自己的所有操作,释放对共享资源上的锁,并返回给交易中间件失败应答。
在第二阶段,交易中间件审查所有数据库返回的预提交结果,如所有数据库都可以提交,交易中间件将要求所有数据库做正式提交,这样该全局事务被提交。而如果有任一数据库预提交返回失败,交易中间件将要求所有其它数据库回滚其操作,这样该全局事务被回滚。
mysql 允许多个数据库实例参与一个全局的事务。MySQL XA 的命令集合如下:
-- 开启一个事务,并将事务置于 ACTIVE 状态,此后执行的 SQL 语句都将置于该是事务中。
XA START xid
-- 将事务置于 IDLE 状态,表示事务内的 SQL 操作完成。
XA END xid
-- 事务提交的准备动作,事务状态置于 PREPARED 状态。事务如果无法完成提交前的准备操作,该语句会执行失败。
XA PREPARE xid
-- 事务最终提交,完成持久化。
XA COMMIT xid
-- 事务回滚终止
XA ROLLBACK xid
-- 查看 MySQL 中存在的 PREPARED 状态的 xa 事务。
XA RECOVER
MySQL 在 XA 事务中扮演的是参与者的角色,被事务协调器所支配。XA 事务比普通本地事务多了一个 PREPARE 状态,普通事务是 begin-> commit 而分布式事务是 begin->PREPARE 等其他数据库事务都到 PREPARE 状态的时候再 PREPARE->commit。分布式事务 sql 示例:
xa start 'aaa';
insert into table(xxx) values(xxx);
xa end 'aaa';
xa prepare 'aaa';
xa commit 'aaa';
XA 事务存在的问题:
-
单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
-
同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞状态,直到提交完成才能释放资源。
-
数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务 commit 的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了 commit 操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
8.2 TCC 分布式事务
TCC 又被称作柔性事务,通过事务补偿机制来达到事务的最终一致性,它不是强一致性的事务。TCC 将事务分为两个阶段,或者说是由两个事务组成的。相对于 XA 事务来说 TCC 的并发性更好,XA 是全局性的事务,而 TCC 是由两个本地事务组成。
假设我们购买一件商品,后台需要操作两张表——积分表加积分而库存表扣库存,这两张表存在于两个数据库中,使用 TCC 事务执行这一事务:
1)TCC 实现阶段一:Try
在 try 阶段并不是直接减库存加积分,而是将相关数据改变为预备的状态。库存表先锁定一个库存,锁定的方式可以预留一个锁定字段,当这个字段为一的时候表示这个商品被锁定。积分表加一个数据,这个数据也是被锁定状态,锁定方式和库存表一样。其 sql 形如:
update stock set lock=1 where id=1;
nsert into credits (lock,...) values (1,...)
这两条 sql 如果都执行成功则进入 Confirm 阶段,如果执行不成功则进入 Cancel 阶段
2)TCC 实现阶段二:Confirm
这一阶段正式减库存加积分订单状态改为已支付。执行 sql 将锁定的库存扣除,为累加积分累加,以及一些其他的逻辑。
3)TCC 实现阶段三:Cancel
当 try 阶段执行不成功,就会执行这一阶段,这个阶段将锁定的库存还原,锁定的积分删除掉。退回到事务执行前的状态。
TCC 事务原理很简单,使用起来却不简单。首先 TCC 事务对系统侵入性很大,其次是让业务逻辑变得复杂。在实际使用中我们必须依赖 TCC 事务中间件才能让 TCC 事务得以实现。通常一个 TCC 事务实现大概是这样子的:某个服务向外暴露了一个服务,这个服务对外正常调用,其他服务并不能感知到 TCC 事务的存在,而其服务内部,分别实现了 Try,Confirm,Cancel 三个接口,注册到 TCC 中间件上去。当调用这个服务的时候,其事务操作由该服务和 TCC 中间件共同完成。
而 TCC 事务中间件还要做好其他事情,比如确保 Confirm 或者 Cancel 执行成功,如果发现某个服务的 Cancel 或者 Confirm 一直没成功,会不停的重试调用他的 Cancel 或者 Confirm 逻辑,务必要他成功!即使在尝试多次后无法成功也能通知到系统需要人工排查异常。TCC 事务还要考虑一些异常情况的处理,比如说订单服务突然挂了,然后再次重启,TCC 分布式事务框架要能够保证之前没执行完的分布式事务继续执行。TCC 分布式事务框架还需要做好日志的记录,保存下来分布式事务运行的各个阶段和状态,以便系统上线后能够排查异常,恢复数据。目前开源的 TCC 事务框架有:Seata ByteTCC tcc-transaction等。