ORM数据库操作流程:
1. 配置数据库(项目同名包中settings.py和__init__.py)
2. 定义类(app包中models.py),执行建表命令(Tools--->Run managy.py Task:makemigrations ---> migrate)
3. 视图(app包中views.py)中定义相关的函数数据库表操作语句
ORM数据库配置:
· 默认配置情况下,ORM使用jango自带的数据库db(在项目文件settings.py中默认配置项:DATABASES)
· 自定义数据库配置(推荐):
以Mysql为例:
修改项目文件settings.py文件中的DATABASES配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 指定数据库引擎
'NAME': 'ormtest', # 指定数据库
'USER': "root", # 配置数据库用户名
'PASSWORD': '', # 配置数据库密码
'HOST': '127.0.0.1', # 配置数据库地址ip
'PORT': 3306, # 配置数据库端口port
# 'OPTIONS': {
# 'init_command': "SET default_storage_engine='INNODB'",
# 'init_command': "SET sql_mode='STRICT_TRANS_TABLES'", } #设置数据库的严格模式
}
}
打印orm翻译成的sql语句配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置项目同名的包中__init__.py文件:
import pymysql
pymysql.install_as_MySQLdb()
ORM的建表语句规则:
· 在app应用的models.py模块中定义类(必须继承models.Model)
· 类名对应表名,属性对应表字段(数据库中的实际表名:app应用名_类名(全小写),例如:app01_book)
· 属性调用models中不同的类方法(如:models.CharField())对表字段进行类型设置,字符串必须指定最大长度
· 在不设置id指定主键的情况下,orm会自动创建一个主键字段id,可以使用id或者pk来调用其值
· 约束条件和长度当成属性类型实例化类的参数,不指定null时默认为非空约束
定义类:app应用包中models.py
from django.db import models
class Book(models.Model):
# id=models.AutoField(primary_key=True) #不写会自动创建
name=models.CharField(max_length=32)
price=models.FloatField()
date=models.DateField()
publisher=models.CharField(max_length=32)
update_time=models.DateTimeField(auto_now=True)
执行创建命令:
工具栏Tools--->Run managy.py Task(或者Ctrl+alt+R)
>>>makemigrations
>>>migrate
ORM单表操作:
增:
单个插入:
(1)实例化对象,调用对象save方法
obj=models.Book(name="完美人生",price=10.00,date='2019-05-24',publisher='未来出版社')
obj.save() #就是pymysql的那个commit提交
(2)调用控制器objects的create方法(常用)
models.Book1.objects.create(name="完美人生",price=10.00,date='2019-05-24',publisher='未来出版社')
或(用**将字典打散,在前端发送来数据先用dic=request.POST.dict()直接转成dic字典)
book={'name':"完美人生",'price':10.00,'date':'2019-05-24','publisher':'未来出版社'}
models.Book.objects.create(**book)
其他插入:
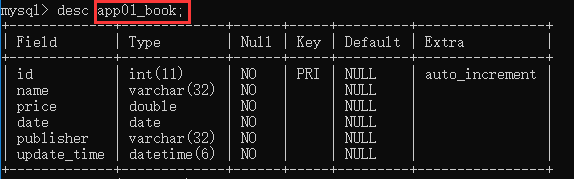
(1)批量插入:先实例化对象,存在一个列表,再调用控制器objects的bulk_create方法
li = []
book_li = [["书籍1", 12, '2019-05-01', '不详'],
["书籍2", 13, '2019-05-04', '不详'],
["书籍3", 13, '2019-05-04', '不详'],
["书籍4", 15, '2019-05-05', '不详']
]
for book in book_li:
book_obj = models.Book(name=book[0], price=book[1], date=book[2], publisher=book[3])
li.append(book_obj)
models.Book.objects.bulk_create(li)
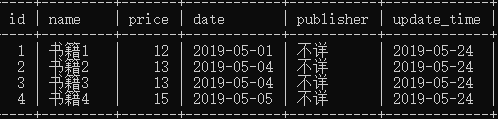
(2)更新或插入:调用控制器objects的update_or_create方法(先查有则更新无则追加)
models.Book.objects.update_or_create(
name="书籍1", #先用get查询(最多只能查到一条,否则报错),找到的更新,找不到追加本条信息
defaults={ #设置更新或者追加的值
"name":"书籍2"
}
)
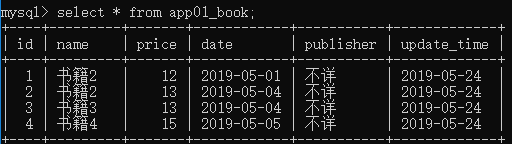
models.Book.objects.update_or_create(
name="书籍2",
defaults={
'price':14
}
)

删:(filter得到的query set和get得到的model对象均可调用delete方法)
models.Book.objects.filter(pk=1).delete()
或
models.Book.objects.get(pk=1).delete()
或
改:(只有filter得到的query set才可调用update方法)
models.Book.objects.filter(id=3).update(price=20)
查:
查所有(QuerySet):
ret =models.Book.objects.all()
print(ret)
查询结果为QuerySet:
<QuerySet [<Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>]>
有且仅有一条(类对象):
ret=models.Book.objects.get(id=2) 只有一条正常显示
print(ret)
查询结果为类对象:
Book object
ret=models.Book.objects.get(id=2) 没有会报错

ret=models.Book.objects.get(name="书籍2") 超过一条报错

选择性查询(QuerySet):
ret=models.Book.objects.filter(name="书籍2")
print(ret)
查询结果QuerySet:
<QuerySet [<Book: Book object>, <Book: Book object>]>
filter选择性查询条件:
以下是常用的双下划线条件:
models.Book.objects.filter(price=10)#等于某个值
models.Book.objects.filter(price__gt=13)#大于某个值
models.Book.objects.filter(price__lt=13)#小于某个值
models.Book.objects.filter(price__in=[12,14,15])#在某几个元素中
models.Book.objects.filter(price__range=(11,15))#在某个范围内(前后包含)
models.Book.objects.filter(name__contains="书籍")#内容包括某个值
models.Book.objects.filter(name__icontains="pyhton")#内容包含某个值(加i不区分大小写)
models.Book.objects.filter(name__startswith="书籍")#以某个值开头
models.Book.objects.filter(name__istartswith="python")#以某个值开头(加i不区分大小写)
models.Book.objects.filter(date__year=2019,date__month=12,date__day=2)#年月日为某个值
查询API:
|
1 |
all() |
查询所有结果,结果是queryset类型 |
|
2 |
filter(**kwargs): |
· 它包含了与所给筛选条件相匹配的对象,结果也是queryset类型 · Book.objects.filter(title='linux',price=100) #里面的多个条件用逗号分开,并且这几个条件必须都成立,是and的关系 · queryset对象也可调用filter · 控制器可直接调用filter |
|
3 |
get(**kwargs) |
返回与所给筛选条件相匹配的对象,不是queryset类型,是行记录对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。捕获异常try。 Book.objects.get(id=1) |
|
4 |
exclude(**kwargs) |
· 排除的意思,它包含了与所给筛选条件不匹配的对象, · 直接用exclude,返回值是queryset类型 · Book.objects.exclude(id=6),返回id不等于6的所有的对象, · 或者在queryset基础上调用,Book.objects.all().exclude(id=6) |
|
5 |
order_by(*field) |
· queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值还是queryset类型; · models.Book.objects.all().order_by('price','id') #直接写price,默认是按照price升序排列, · 按照字段降序排列,就写个负号就行了order_by('-price'), · order_by('price','id')是多条件排序,按照price进行升序,price相同的数据,按照id进行升序 |
|
6 |
reverse() |
queryset类型的数据来调用,对查询(order_by之后)结果反向排序,返回值还是queryset类型 |
|
7 |
count() |
queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量。 |
|
8 |
first() |
· queryset类型的数据来调用,返回第一条记录 · 控制器调用返回第一个对象 · Book.objects.all()[0] = Book.objects.all().first(),得到的都是model对象,不是queryset |
|
9 |
last() |
queryset类型的数据来调用,返回最后一条记录 |
|
10 |
exists() |
· queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False; · 空的queryset类型数据也有布尔值True和False,但是一般不用查询的queryset结果直接来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits · 例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT (1) AS `a` FROM `app01_book` LIMIT 1,就是通过limit 1,取一条来看看是不是有数据 |
|
11 |
values(*field) |
· 控制器调用 · queryset类型的数据来调用,返回一个ValueQuerySet——一个特殊的QuerySet, · 运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列, · 只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的。 |
|
12 |
values_list(*field) |
它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 |
|
13 |
distinct() |
values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录 |