我只是简单的部署测试,并没有深入的研究相关内容,可能下面的描述并不是准确。
ceph 的中文文档很不错,访问地址: http://docs.ceph.org.cn。
1、ceph 架构简介
先了解下 ceph 基本组成,有一个大概的了解,这部分内容主要摘抄自 ceph 文档和别人的文章。
以下部分来自:http://docs.ceph.org.cn/start/intro/
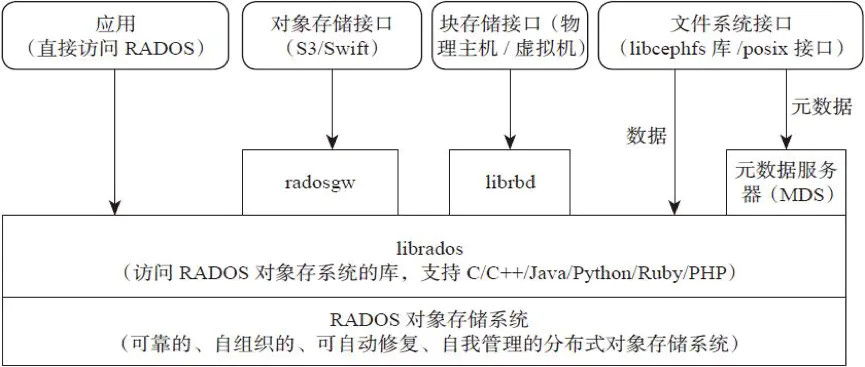
不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
- Ceph OSDs: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到
active+clean状态( Ceph 默认有3个副本,但你可以调整副本数)。- Monitors: Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDSs: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如
ls、find等基本命令。Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。

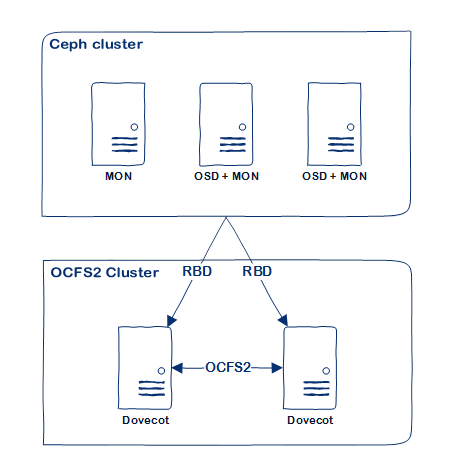
rados 结构,以下部分来自 https://www.jianshu.com/p/cc3ece850433
一个 Ceph 集群的服务器关系图,来自 https://docs.switzernet.com/3/public/130910-ceph-dovecot/
更多的内容这里就不转载了,请直接网络搜索吧。
参考资料
2、集群节点规划
我这里只是测试一下,所以开了三个虚拟机进行测试。三个虚拟机操作系统都是 CentOS 8。
| 节点 | IP | 数据盘(OSD) | 角色 |
|---|---|---|---|
| ceph-mon1 | 192.168.122.103 | MON、MDS、PROM、GRAFANA | |
| ceph-osd1 | 192.168.122.200 | /dev/vdb1 | OSD |
| ceph-osd2 | 192.168.122.201 | /dev/vdb1 | OSD |
3、准备工作
先在三台机器上,修改 /etc/hosts 文件,添加下面内容:
# ceph 集群节点主机名对应的 ip,每个节点都需要添加
192.168.122.103 ceph-mon1
192.168.122.200 ceph-osd1
192.168.122.201 ceph-osd2
然后分别在每个节点机器上,根据节点所承担的角色设置主机名
# 下面的 ceph-mon1 需要根据实际节点进行确定
hostnamectl set-hostname ceph-mon1
4、使用 cephadm 部署一个 ceph 集群
4.1、离线安装包
因为后续需要离线部署到实际工作环境中,所以我这里参照网上的部署方案,制作了一个简单的离线安装部署包。
安装包里面的 cephadm 程序被我修改了,将里面的 command_pull 函数里面 cmd 数组中的 'pull' 改为了 'images' 。因为离线部署不需要使用 docker 或者 podman 去实际拉取镜像,使用本地镜像即可。
离线安装包只适合在 CentOS 8 x86_64 下使用,其他系统环境无法兼顾。离线安装包主要是打包了 podman、python3、smartmontools、chrony 的安装包,以及 cephadm 及其需要用到的几个容器镜像。
cephadm 使用到的镜像列表如下:
sudo podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.ceph.io/ceph-ci/ceph v17.0.0 fb6c62c88122 11 hours ago 1.14 GB
docker.io/ceph/ceph-grafana 6.7.4 80728b29ad3f 3 months ago 495 MB
docker.io/prom/prometheus v2.18.1 de242295e225 11 months ago 141 MB
docker.io/prom/alertmanager v0.20.0 0881eb8f169f 16 months ago 53.5 MB
离线安装包下载地址:
链接: https://pan.baidu.com/s/1zIODZ9cfMVCxLQrU9YRyow 提取码: cxi5 复制这段内容后打开百度网盘手机App,操作更方便哦
注意,在安装完成之后,可以将 cephadm 复制到 /usr/bin 目录下,后续可以直接使用,无需指定路径。
4.2、在 ceph-mon1 节点进行部署
将上面说的离线安装包上传到 ceph-mon1 节点,解压后进入 ceph_centos8_x86_64 文件夹,执行下面命令进行基础依赖组件安装:
# 执行 install.sh 脚本,安装必要的一些软件,以及导入镜像到容器
./install.sh
安装完成基础组件后,再执行 cluster.gen.sh 脚本来创建集群,执行的过程中,会要求输入 MON 节点的 IP,直接输入后回车即可:
./cluster.gen.sh
... ...
Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。
请输入 MON (Ceph Monitor) 节点 IP:192.168.122.103
如果执行没有出错的话,应该会有类似下面的输出:
... ...
Enabling firewalld port 8443/tcp in current zone...
Ceph Dashboard is now available at:
URL: https://ceph-mon1:8443/
User: admin
Password: j75kmrecsd
You can access the Ceph CLI with:
sudo ./cephadm shell --fsid be48dd3a-983d-11eb-b776-525400648899 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
这表示已经安装成功了,可以使用浏览器打开 https://ceph-mon1:8443/ 进行访问,用户名和密码也在输出中。
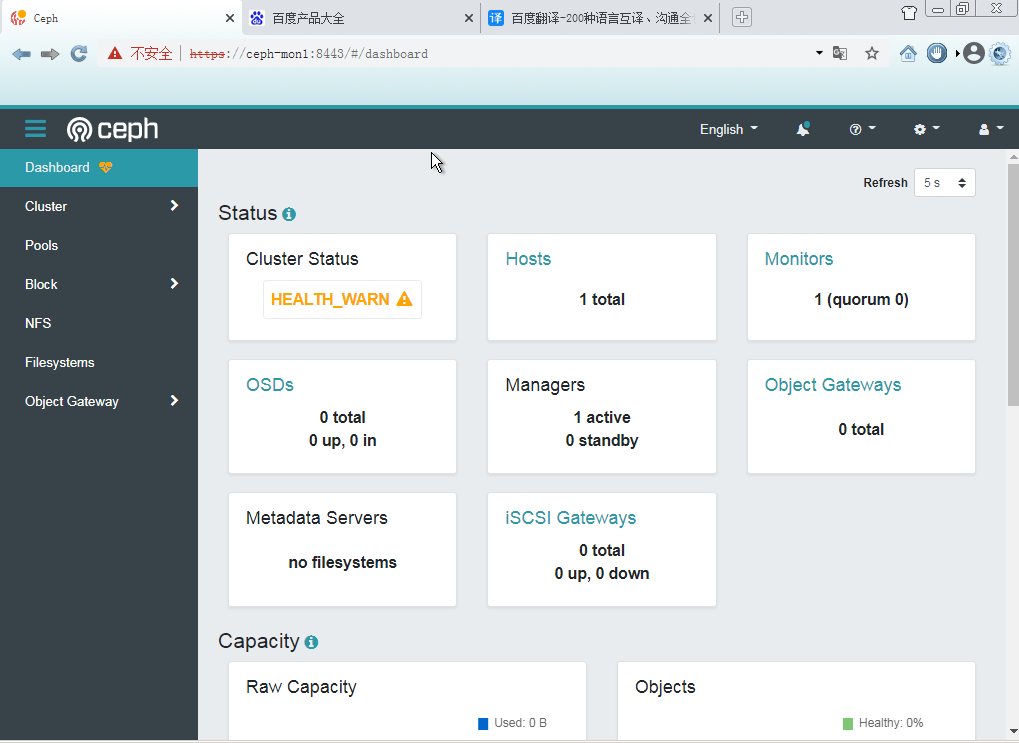
4.3、添加 ceph-ods1、ceph-ods2 节点到集群
4.3.1、集群节点间的 SSH 免密访问设置
前面安装过程结束后,会在 /etc/ceph 目录下生成 ceph.pub 文件,这个是 ssh 创建的公钥文件,将它上传到 ceph-ods1 和 ceph-ods2 节点,以便实现 SSH 免密登陆。
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-osd1
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-osd2
可以使用 ssh-keygen 命令创建新的密钥对也是可以的。
ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:2FaZgTcTf3ol/aafNHh69m9Bb2i8xKiwx8Um6aTtvmw root@ceph-osd1
The key's randomart image is:
+---[RSA 3072]----+
| .o. |
| . += . |
| .+o. o o|
| o . o +.|
| . S o.+o.+|
| .. + =.B+o|
| O = +.*.|
| o.E =++|
| ==. .oo*|
+----[SHA256]-----+
# 创建之后,将 公钥 拷贝到 ceph-osd1 和 ceph-osd2
ssh-copy-id -f -i /root/.ssh/id_rsa.pub root@ceph-osd1
上面操作只能实现 ceph-mon1 节点免密 SSH 登陆 ceph-osd1(2) 节点,要能够都互相之间访问,则需要反过来也操作。
4.3.2、添加节点到集群
下面说的步骤中,直接将离线安装包拷贝到所有节点上,并执行 install.sh 脚本,就不用麻烦了,可以直接跳到 4.4 的第三个步骤。
注意,下面所说的都是在各个节点分别进行的过程,不是在 ceph-mon1 节点了。
然后将离线安装包上传到 ceph-osd1 和 ceph-osd2 节点
scp -r ceph_centos8_x86_64 root@ceph-osd1:/root/
scp -r ceph_centos8_x86_64 root@ceph-osd1:/root/
然后 ssh 登陆到 ceph-osd1 和 ceph-osd2 节点,安装好 python3
# 这里只记录对 ceph-osd1 的操作,ceph-osd2 的操作是一样的
ssh root@ceph-osd1
rpm -Uvh /root/ceph_centos8_x86_64/python3/*.rpm --nodeps
rpm -Uvh /root/ceph_centos8_x86_64/podman/*.rpm --nodeps
# 不安装 python3 ,添加节点到集群时候会报错:
# Error EINVAL: Can't communicate with remote host `192.168.122.200`,
# possibly because python3 is not installed there: cannot send (already closed?)
# 不安装 podman ,添加节点到集群时候会报错:
# Error EINVAL: New host ceph-osd1 (192.168.122.200) failed check(s): []
注意:如果不进行上面的安装操作,将无法将节点添加到集群!
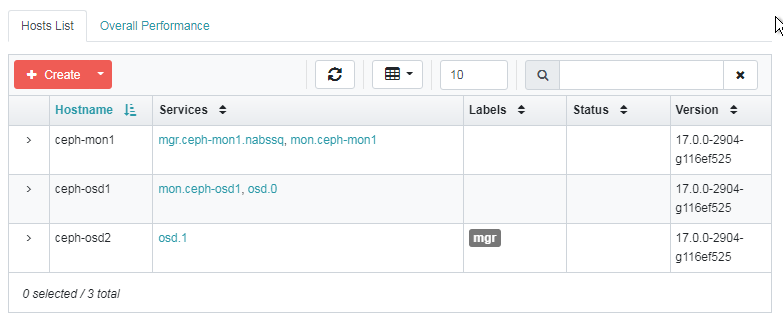
执行完成上面的操作之后,可以回到 ceph-mon1 节点,执行下面的命令将 ceph-osd1 和 ceph-osd2 添加到集群。
# 下面最后的 IP 说是可选项,但是如果加上这个 IP 的话,在我这边无法将节点加入集群
ceph orch host add ceph-osd1 192.168.122.200
ceph orch host add ceph-osd2 192.168.122.201
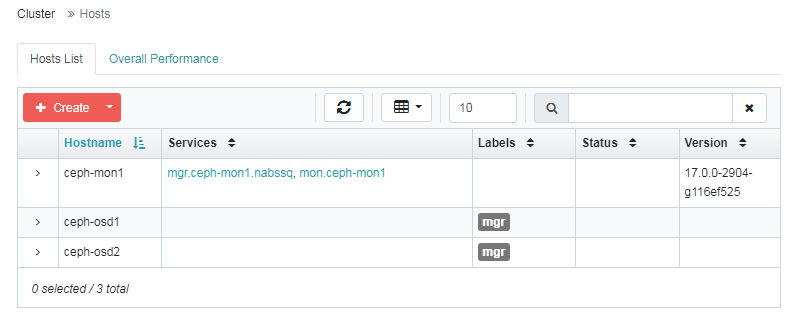
上面的标签是使用下面命令添加的(这是在 ceph-mon1 节点执行的),标签可以添加也可以移除。
ceph orch host label add ceph-osd1 mgr
ceph orch host label add ceph-osd2 mgr
ceph orch apply mgr label:mgr
4.4、在 ceph-ods1、ceph-ods2 节点安装 OSDs
下面的操作都是在 ceph-ods1、ceph-ods2 节点进行的,两个节点都要执行。
4.4.1、依赖项安装
将离线安装包里面的 ceph-common 、chrony 安装。(如果上面步骤中是执行 install.sh 安装的,则跳过此步骤)
rpm -Uvh /root/ceph_centos8_x86_64/chrony/*.rpm --nodeps
rpm -Uvh /root/ceph_centos8_x86_64/ceph-common/*.rpm --nodeps
执行上面的操作后,可以执行下 ceph 命令看看是否正常,应该是会报一下错误的:
ceph
Error initializing cluster client: ObjectNotFound('RADOS object not found (error calling conf_read_file)',)
这个只需要将 ceph-mon1 节点上的 /etc/ceph/ceph.conf 和 ceph.client.admin.keyring 文件拷贝到其他节点即可
[root@ceph-mon1 ceph]# scp /etc/ceph/ceph.conf root@ceph-osd1:/etc/ceph/
[root@ceph-mon1 ceph]# scp /etc/ceph/ceph.client.admin.keyring root@ceph-osd1:/etc/ceph/
# 上面命令是在 mon1 节点上操作的,复制到其他节点也是一样的操作。
然后将 docker.io 和 quay.ceph.io 里面的容器镜像导入到 podman。(如果上面步骤中是执行 install.sh 安装的,则跳过此步骤)
podman load -i quay.ceph.io/ceph-ci/ceph.tar quay.ceph.io/ceph-ci/ceph:v17.0.0
podman load -i docker.io/ceph/ceph-grafana.tar docker.io/ceph/ceph-grafana:6.7.4
podman load -i docker.io/prom/prometheus.tar docker.io/prom/prometheus:v2.18.1
podman load -i docker.io/prom/alertmanager.tar docker.io/prom/alertmanager:v0.20.0
podman load -i docker.io/prom/node-exporter.tar docker.io/prom/node-exporter:v0.18.1
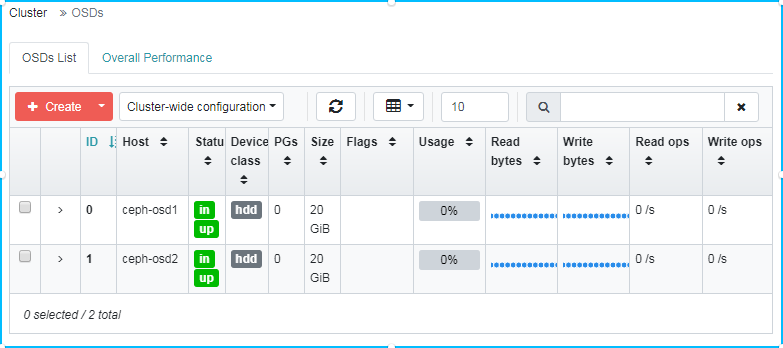
4.4.2、添加 OSD 角色(服务)到集群
前面添加了节点到集群,并且也在每个节点都进行必要的依赖项安装,以及 podman 镜像的导入,下面可以进行 OSD 角色(服务)的添加了。
在任意节点(因为都已经安装了 ceph-common,所以那个节点都一样),
# 在 ceph-osd1 和 ceph-osd2 节点创建 osd 服务
# 注意,下面的 /dev/vdb 是在节点机器上的一个未使用的磁盘
ceph orch daemon add osd ceph-osd1:/dev/vdb
ceph orch daemon add osd ceph-osd2:/dev/vdb
Created osd(s) 1 on host 'ceph-osd2'
# 添加别的角色也是类似的操作,比如添加一个 mon
ceph orch daemon add mon ceph-osd1:192.168.122.200/24
查看一下集群状态:
ceph -s
cluster:
id: be48dd3a-983d-11eb-b776-525400648899
health: HEALTH_WARN
clock skew detected on mon.ceph-osd1
OSD count 2 < osd_pool_default_size 3
services:
mon: 2 daemons, quorum ceph-mon1,ceph-osd1 (age 31m)
mgr: ceph-mon1.nabssq(active, since 25h)
osd: 2 osds: 2 up (since 20m), 2 in (since 20m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 9.9 MiB used, 40 GiB / 40 GiB avail
pgs:
因为我这里只有两个 OSDs ,所以这里会有警告。
5、创建一个文件系统卷
执行完成上面的操作之后,可以创建一个文件系统进行测试一下
# 可以先创建两个 Pool,如果不创建的话,会默认创建的
# ceph osd pool create testfs.data # 用于保存数据
# ceph osd pool create testfs.meta # 用于保存元数据
# 创建一个文件系统卷 testfs
# 下面命令中的 testfs.meta testfs.data 不指定就会创建默认名称是
# cephfs.testfs.meta 和 cephfs.testfs.data 的 Pool
# 如果上面创建了别的名字的 Pool ,这里也是可以用的,指定 Pool 名称就是
ceph fs volume create testfs # testfs.meta testfs.data
# 查看一下当前的文件系统卷有哪些
ceph fs volume ls
[
{
"name": "testfs"
}
]
创建完成之后,添加一个 mds (元数据)服务
# 设置一下副本数量
ceph orch apply mds testfs --placement="2 ceph-osd1 ceph-osd2"
# 在节点 ceph-mon1 上添加 mds 服务
ceph orch daemon add mds testfs ceph-mon1
# 查看一下文件系统状态
ceph fs status testfs
testfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 reconnect testfs.ceph-mon1.hypudc 0 0 0 0
POOL TYPE USED AVAIL
cephfs.testfs.meta metadata 64.0k 18.9G
cephfs.testfs.data data 0 12.6G
MDS version: ceph version 17.0.0-2904-g116ef525 (116ef52566c5fb8f7621439218fb492595e2d85a) quincy (dev)
使用命令 ceph mds stat 查看下 mds 服务状态
ceph mds stat
testfs:1 cephfs:1 {cephfs:0=cephfs.ceph-mon1.komjhm=up:active,testfs:0=testfs.ceph-mon1.hypudc=up:active}
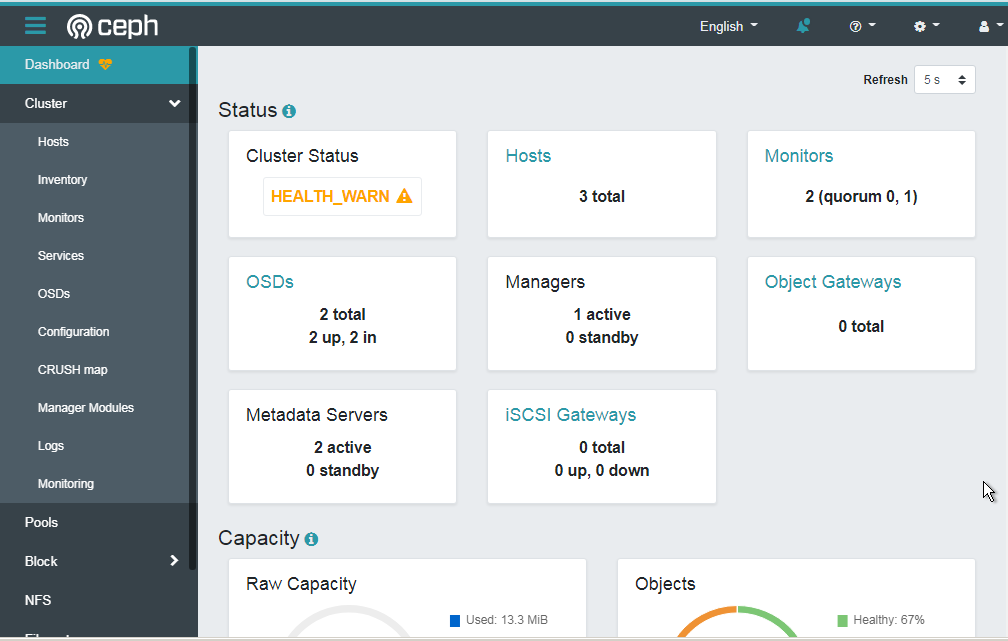
重新看一下集群状态,我这里因为创建了两个文件系统和 mds ,所以下面有的显示了两个的状态。
ceph -s
cluster:
id: be48dd3a-983d-11eb-b776-525400648899
health: HEALTH_WARN
insufficient standby MDS daemons available
clock skew detected on mon.ceph-osd1
Degraded data redundancy: 22/66 objects degraded (33.333%), 13 pgs degraded, 224 pgs undersized
OSD count 2 < osd_pool_default_size 3
services:
mon: 2 daemons, quorum ceph-mon1,ceph-osd1 (age 97m)
mgr: ceph-mon1.nabssq(active, since 26h)
mds: 2/2 daemons up
osd: 2 osds: 2 up (since 85m), 2 in (since 86m)
data:
volumes: 2/2 healthy
pools: 4 pools, 224 pgs
objects: 22 objects, 2.3 KiB
usage: 13 MiB used, 40 GiB / 40 GiB avail
pgs: 22/66 objects degraded (33.333%)
211 active+undersized
13 active+undersized+degraded
io:
client: 409 B/s rd, 0 op/s rd, 0 op/s wr
progress:
Global Recovery Event (22m)
[............................]
6、在客户端机器挂载 cephfs
先在客户端机器上安装 ceph-common,软件安装包在离线安装包里面有。
然后直接使用下面的命令进行挂载操作即可:
# 创建挂载点目录,我这里创建两个,把前面创建的两个 fs 都挂载上
mkdir /mnt/testfs
mkdir /mnt/cephfs
# 使用 mount.ceph 进行挂载,使用的相关参数等可以 man mount.ceph 进行查看
# secret 参数的值来自于 /etc/ceph/ceph.client.admin.keyring 文件内
# fs 用于指定使用那个 cephfs
#
mount -t ceph :/ /mnt/testfs -o name=admin,secret=AQCJs25gjmpIBBAAdbmFcI+nfdd9rfsa+zW78g==,fs=testfs
# 指定任意一个 MON 节点的 IP 都可以,也可以指定多个,用 , 分隔
mount -t ceph 192.168.122.200:6789:/ cephfs -o name=admin,secret=AQCJs25gjmpIBBAAdbmFcI+nfdd9rfsa+zW78g==,fs=cephfs
# 挂载后使用 df 命令查看下
df -h
文件系统 容量 已用 可用 已用% 挂载点
.... 多余的删掉了....
192.168.122.103:6789:/ 12G 2.4G 9.3G 21% /mnt/cephfs
192.168.122.200:6789:/ 11G 1.7G 9.3G 15% /mnt/testfs
更多参数和挂载示例还是通过 man mount.ceph 进行查询比较好。
使用 ceph fs dump 命令查看一下 cephfs 的状况。
ceph fs dump
dumped fsmap epoch 16
e16
enable_multiple, ever_enabled_multiple: 1,1
compat: compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
legacy client fscid: 1
Filesystem 'testfs' (1)
fs_name testfs
epoch 16
flags 12
created 2021-04-09T09:28:18.089566+0000
modified 2021-04-12T03:08:34.919957+0000
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 35
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=14646}
failed
damaged
stopped
data_pools [2]
metadata_pool 1
inline_data disabled
balancer
standby_count_wanted 1
[mds.testfs.ceph-mon1.hypudc{0:14646} state up:active seq 58769 join_fscid=1 addr [v2:192.168.122.103:6804/1724461665,v1:192.168.122.103:6805/1724461665]]
Filesystem 'cephfs' (2)
fs_name cephfs
epoch 14
flags 12
created 2021-04-09T09:40:15.916424+0000
modified 2021-04-09T09:50:45.474894+0000
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 0
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=24235}
failed
damaged
stopped
data_pools [3]
metadata_pool 4
inline_data disabled
balancer
standby_count_wanted 0
[mds.cephfs.ceph-mon1.komjhm{0:24235} state up:active seq 3 join_fscid=2 addr [v2:192.168.122.103:6802/4112730485,v1:192.168.122.103:6803/4112730485]]