
requests下载
好了,现在开始下载。我们在前面是用requests下载的,那么现在一样还是用这种方法

我们现在有了每个章节的网页代码,所以只需要重复之前的操作,对下载的文本数据进行清除

这个地方需要把exit()写上,意思是让循环一次就停下来
需要写在print()后面

问题来了,匹配字段怎么找呢?
我们需要打开第一章节,chrome浏览器里按F12,检测网页源代码

去找一下我们所需要的文字字段
看看有什么唯一的,这里可用ctrl+f 来进行查找是否唯一

你可以注意到‘2008年,4月5日’是我们想要的,所以就需要我们在前面找
这里有个很特殊的字段<div id="content">
又查找了一下,发现是唯一的,所以开头找好了,结尾也是这样

而这里我们需要用replace替换方法,把特殊的符号替换成空,如果还有其他的符号也要自己替换。
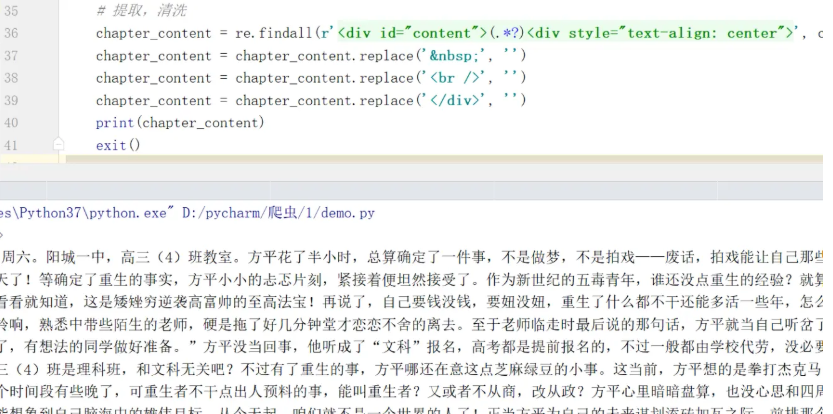
爬取成功,进行下载
我们不能每次都这样爬取,所以要把小说保存在我们之前建的文件里面

完成