查找的基本概念:
1.查找表
2.关键字:关键字是数据元素(或记录)中某个数据项的值,用它可以标识一个数据元素(或记录)。若关键字可以唯一地标识一个记录,则称此关键字为主关键字(对不同的记录,其主关键字均不同)。反之,称用以识别若干记录的关键字为次关键字。当数据元素只有一个数据项时,其关键字即为该数据元素的值
3.查找
4.动态查找表和静态查找表:在查找的同时做修改操作(如插入和删除),则相应的表称之为动态查找表,否则称之为静态查找表。
5.平均查找长度:为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值,陈伟查找算法。
在查找成功的平均查找长度(ASL)。
对于含有n个记录的表,查找成功时的平均查找长度为
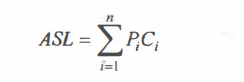
其中, pi为查找表中第i个记录的概率,且所有元素概率和为1。
线性表的查找:
1.顺序查找
基本实现方法:


int Search(SSTable ST,keyType key) { for(i = ST.length;i>=1;--i) if(ST.R[i].key == key) return i; return 0; }
带哨兵:
// 有哨兵顺序查找数组a中从a[1]到数组末尾的key // 设置一个哨兵可以解决不需要每次让i与a.length作比较。 // 返回-1说明查找失败,注意:从数组下标为1的位置开始查找 int seqSearch(int[] a, int key) { int i = a.length - 1; // 设置循环从数组尾部开始 a[0] = key; // 设置a[0]:"哨兵" while (a[i] != key) i--; if(i>0) return i; else return -1; }
2.折半查找(二分查找)
算法描述:
int Search_Bin(SSTable ST, KeyType key) {//在有序表ST中折半查找其关键字等于key的数据元素。若找到,则函数值为改元素在表中的位置,否则为0 low=1; high=ST.length; while(low<=high) { mid=(low+high)/2; if(key==ST.R[mid].key) return mid; else if(key<ST.R[mid]) high=mid-1; else low = mid+1; } return 0; }
需要注意的地方是,循环执行条件是low<=high, 而不是low<high
3.分块查找(索引顺序查找)
这是一种性能介于顺序查找和折半查找之间的一种查找方法。在此查找法中,除表本身以为,尚需建立一个“索引表”。对于每个子表(或称块)建立一个索引项,其中包括两项内容:关键字项(其值为该子表内的最大关键字)和指针项(知识该子表的第一个记录在表中的位置)
分块查找的平均查找长度为:


数表的查找:
1.二叉排序树(二叉查找树)
2.二叉平衡树(AVL数):
(1)左子树和右子数的深度之差的绝对值不超过1;
(2)左子树和右子树也是平衡二叉树
平衡二叉树的平衡调整方法:找到离插入结点最近且平衡因子绝对值超过1的祖先结点,以该结点为根的子树为最小不平衡子树,可将重新平衡的范围局限于这颗子树。
3.B-树:
一颗m阶的B-数,或为孔数,或为满足下列特性的m叉树:
(1)树的每个结点至多有m颗子树
(2)若根结点不是叶子结点,则至多有两颗子树
(3)除根之外的所有非终端结点至少有【m/2】棵子树
(4)所有的叶子结点都出现在同一层次上,并且不带信息,通常陈伟失败结点(失败结点并不存在,指向这些结点的指针为空。引入失败结点是为了便于分析B-树的查找性能);
(5)所有非终端结点最多有m-1个关键字,结点的结构,如图所示:

4.B+树:
一颗m阶的B+树和m阶的B-树的差异在于
(1)有n棵子树的结点中含有n个关键字;
(2)所有的叶子结点中包含了全部关键字的信息,以及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
(3)所有的分终端结点可以看成是索引部分,结点中仅含有其子树(跟结点)中最大(或最小)关键字。
散列表:

构造方法:
1.数字分析法
2.平方取中法
3.折叠法
4.除留余数法
处理冲突方法:
1.开放地址法:

(1)线性探测法
di=1,2,3······, m-1
(2)二次探测法
di=1^2, (-1)^2, 2^2, (-2)^2, ······, k^2, (-k)^2(k<=m/2)
(3)伪随机探测法
di=伪随机数序列
2.链地址法