数据源:
“姓名”“基数”“个人比例”“个人缴纳”“公司比例”“公司缴纳”“总计”,共7列7行数据,其中姓名列,第1、2行与第6、7行内容重复
目标:
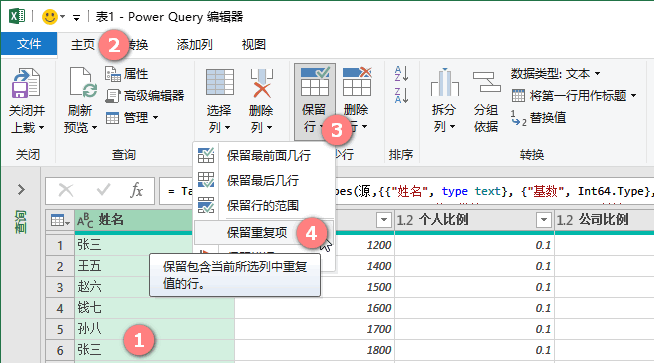
留下第1、2、6、7姓名列中内容重复的行
操作过程:
选取指定列》【主页】》【保留行】》【保留重复项】
M公式:
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
说明:
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 给指定的列名一个说法,叫作“columnNames”
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【分组依据】计算指定列里各个值出现次数,并将这结果命名为addCount
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【保留行】保留“Count”列中值大于1的行
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 【删除列】将“Count”列删除
= let columnNames = {"指定列名"}, addCount = Table.Group(步骤名, columnNames, {{"Count", Table.RowCount, type number}}), selectDuplicates = Table.SelectRows(addCount, each [Count] > 1), removeCount = Table.RemoveColumns(selectDuplicates, "Count") in Table.Join(步骤名, columnNames, removeCount, columnNames, JoinKind.Inner)
- 将原表和只保留重复值的表进行【合并查询】,连接种类使用“内部”
将所有步骤拆分如图所示。
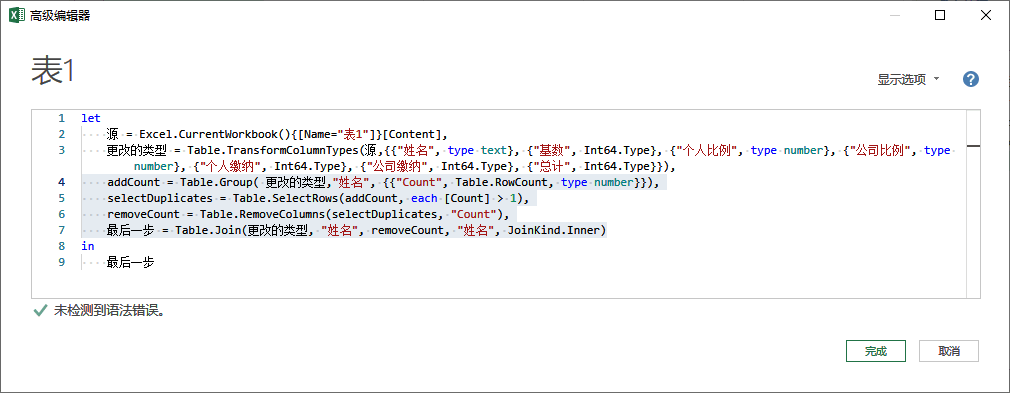
其中核心部分:
addCount = Table.Group( 更改的类型,"姓名", {{"Count", Table.RowCount, type number}}),
selectDuplicates = Table.SelectRows(addCount, each [Count] > 1),
removeCount = Table.RemoveColumns(selectDuplicates, "Count"),
最后一步 = Table.Join(更改的类型, "姓名", removeCount, "姓名", JoinKind.Inner)
最终效果:
数据只剩下姓名列中重复的四行数据
多说一句:
好吧,我承认,我被这个公式惊到了!这其实已经不是一个简单的公式,而是一段M代码,这不是有let开头,in结尾么……