希尔排序(Shell Sort)是插入排序的一种,是针对直接插入排序算法的改进,是将整个无序列分割成若干小的子序列分别进行插入排序,希尔排序并不稳定。该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
一、基本思想
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
二、下面让我们看一下希尔排序的一个实例:
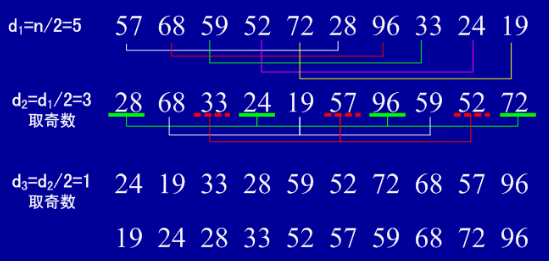
三、希尔排序的时间性能优于直接插入排序的原因:
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插人排序有较大的改进。
增量序列的选择:Shell排序的执行时间依赖于增量序列。好的增量序列的共同特征(查到的资料都这么讲):
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
四、具体的java代码实现
public static void shellSort(int[] a){
double gap = a.length;//增量长度
int dk,sentinel,k;
while(true){
gap = (int)Math.ceil(gap/2);//逐渐减小增量长度
dk = (int)gap;//确定增量长度
for(int i=0;i<dk;i++){
//用增量将序列分割,分别进行直接插入排序。随着增量变小为1,最后整体进行直接插入排序
for(int j=i+dk;j<a.length;j = j+dk){
k = j-dk;
sentinel = a[j];
while(k>=0 && sentinel<a[k]){
a[k+dk] = a[k];
k = k-dk;
}
a[k+dk] = sentinel;
}
}
//当dk为1的时候,整体进行直接插入排序
if(dk==1){
break;
}
}
}
五、算法分析
希尔排序的算法性能
|
排序类别 |
排序方法 |
时间复杂度 |
空间复杂度 |
稳定性 |
复杂性 |
||
|
平均情况 |
最坏情况 |
最好情况 |
|||||
|
插入排序 |
希尔排序 |
O(Nlog2N) |
O(N1.5) |
|
O(1) |
不稳定 |
较复杂 |
时间复杂度
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。
算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为N/2并且对步长取半直到步长达到1。虽然这样取可以比O(N2)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就
不会以如此短的时间完成排序了。

已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,...),该序列的项来自这两个算式。
这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
算法稳定性
由上文的希尔排序算法演示图即可知,希尔排序中相等数据可能会交换位置,所以希尔排序是不稳定的算法。
六、问题
希尔排序一定正确么?换句话说如何选取增量序列才能保证正确(包括长度、值)?是的,最后一次只要保证增量是1就ok(不管序列长度,只不过效率就低了),若是序列只有1,那就是直接插入排序了,不知道对否。
七、下面给大家列出8种排序之间的关系: