交叉熵
分类问题常用的损失函数为交叉熵(Cross Entropy Loss)。
交叉熵描述了两个概率分布之间的距离,交叉熵越小说明两者之间越接近。
原理这篇博客介绍的简单清晰:
https://blog.csdn.net/xg123321123/article/details/52864830
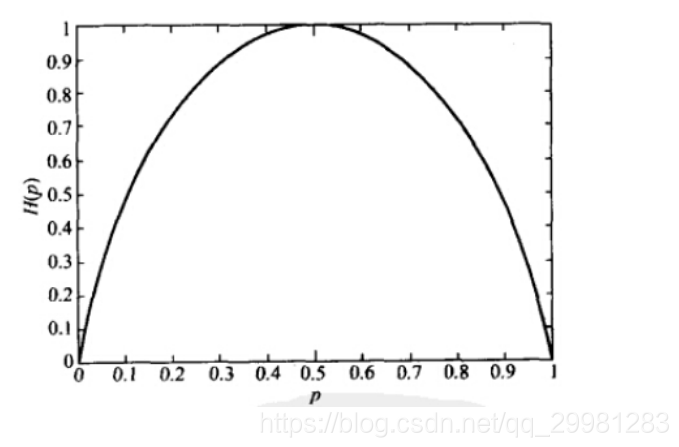
总结: 熵是信息量的期望值,它是一个随机变量的确定性的度量。
熵越大,变量的取值越不确定;反之,熵越小,变量取值就越确定。
熵与概率的关系如图:
 尽管交叉熵刻画的是两个概率分布之间的距离,但是神经网络的输出却不一定是一个概率分布。为此我们常常用Softmax回归将神经网络前向传播得到的结果变成概率分布。
尽管交叉熵刻画的是两个概率分布之间的距离,但是神经网络的输出却不一定是一个概率分布。为此我们常常用Softmax回归将神经网络前向传播得到的结果变成概率分布。
总之
在分类问题中用交叉熵可以更好的体现loss的同时,使其仍然是个凸函数,这对于梯度下降时的搜索很有用。
反观平方和函数,经过softmax后使得函数是一个非凸函数。
分类问题用 One Hot Label + Cross Entropy Loss
Training 过程,分类问题用 Cross Entropy Loss,回归问题用 Mean Squared Error。
validation / testing 过程,使用 Classification Error更直观,也正是我们最为关注的指标。
代码
class CrossEntropy2d(nn.Module):
def __init__(self):
super(CrossEntropy2d, self).__init__()
self.criterion = nn.CrossEntropyLoss(weight=None, size_average=True)
def forward(self, out, target):
n, c, h, w = out.size() # n:batch_size, c:class
out = out.view(-1, c) # (n*h*w, c)
target = target.view(-1) # (n*h*w)
# print('out', out.size(), 'target', target.size())
loss = self.criterion(out, target)
return loss
# 调用方式
criterion = loss.CrossEntropy2d()
loss = criterion(out, labels)