转载 https://arthurchiao.art/blog/ctrip-network-arch-evolution-zh/
云计算时代携程的网络架构变迁(2019)
前言
本文来自我在 GOPS 2019 深圳站 的分享,但叙述方式稍有调整,以更适合阅读,另外对内容做了少量更新。
本文介绍云计算时代以来携程在私有云和公有云上的几代网络解决方案。希望这些内容可以 给业内同行,尤其是那些设计和维护同等规模网络的团队提供一些参考。
本文将首先简单介绍携程的云平台,然后依次介绍我们经历过的几代网络模型:从传统的基 于 VLAN 的二层网络,到基于 SDN 的大二层网络,再到容器和混合云场景下的网络,最后是 cloud native 时代的一些探索。
0 携程云平台简介
携程 Cloud 团队成立于 2013 年左右,最初是基于 OpenStack 做私有云,后来又开发了自 己的 baremetal(BM)系统,集成到 OpenStack,最近几年又陆续落地了 Mesos 和 K8S 平 台,并接入了公有云。目前,我们已经将所有 cloud 服务打造成一个 CDOS — 携程数据中心操作系统的混合云平台,统一管理我们在私有云和公有云上的计算、网络 、存储资源。
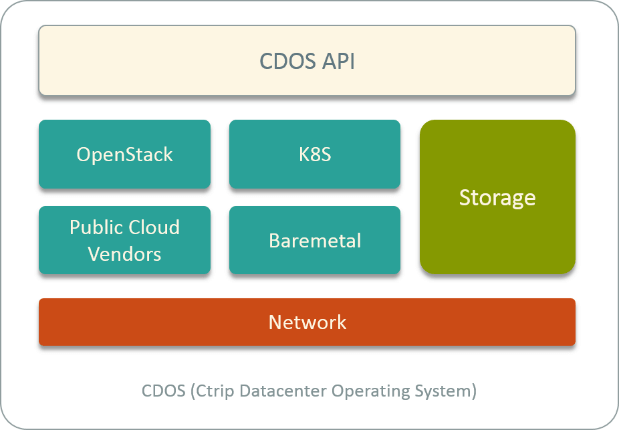
Fig 1. Ctrip Datacenter Operation System (CDOS)
在私有云上,我们有虚拟机、应用物理机和容器。在公有云上,接入了亚马逊、腾讯云、 UCloud 等供应商,给应用部门提供虚拟机和容器。所有这些资源都通过 CDOS API 统一管 理。
网络演进时间线
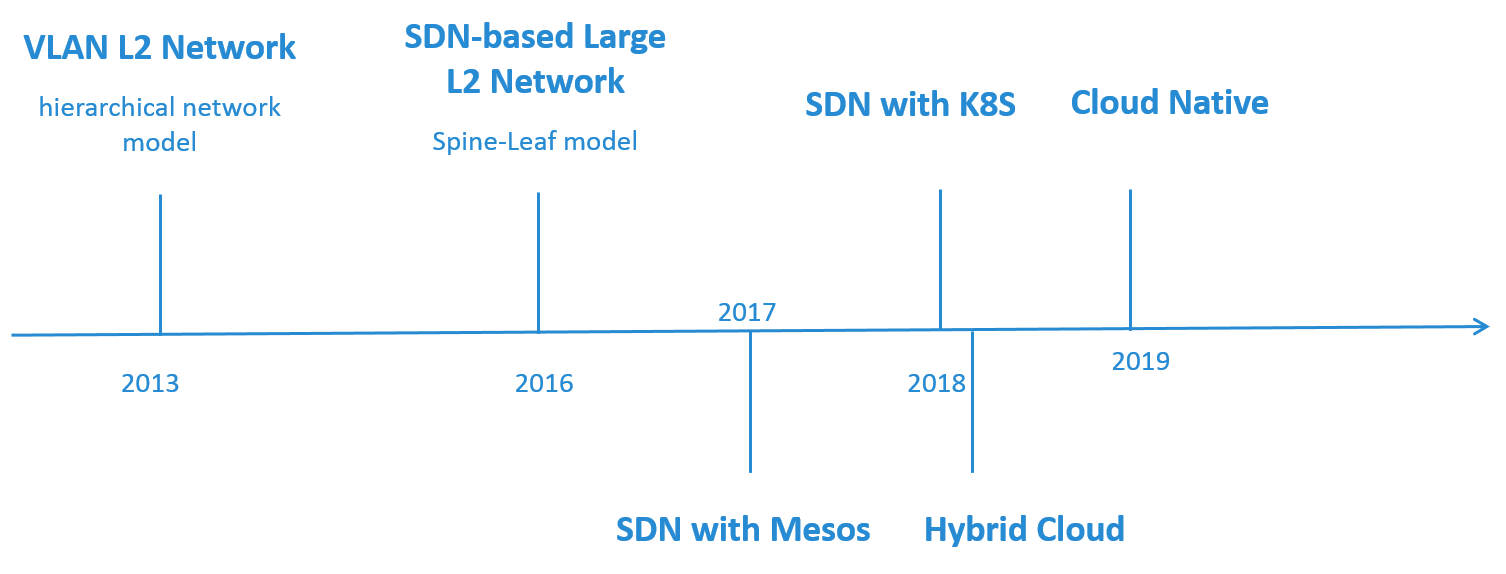
Fig 2. Timeline of the Network Architecture Evolution
图 2 我们网络架构演进的大致时间线。
最开始做 OpenStack 时采用的是简单的 VLAN 二层网络,硬件网络基于传统的三层网络模 型。
随着网络规模的扩大,这种架构的不足逐渐显现出来。因此,在 2016 年自研了基于 SDN 的大二层网络来解决面临的问题,其中硬件架构换成了 Spine-Leaf。
2017 年,我们开始在私有云和公有云上落地容器平台。在私有云上,对 SDN 方案进行了扩 展和优化,接入了 Mesos 和 K8S 平台,单套网络方案同时管理了虚拟机、应用物理机和容 器网络。公有云上也设计了自己的网络方案,打通了混合云。
最后是 2019 年,针对 Cloud Native 时代面临的一些新挑战,我们在调研一些新方案。
1 基于 VLAN 的二层网络
2013 年我们开始基于 OpenStack 做私有云,给公司的业务部门提供虚拟机和应用物理机资 源。
1.1 需求
网络方面的需求有:
首先,性能不能太差,衡量指标包括 instance-to-instance 延迟、吞吐量等等。
第二,二层要有必要的隔离,防止二层网络的一些常见问题,例如广播泛洪。
第三,实例的 IP 要可路由,这点比较重要。这也决定了在宿主机内部不能使用隧道 技术。
第四,安全的优先级可以稍微放低一点。如果可以通过牺牲一点安全性带来比较大的性能提 升,在当时也是可以接受的。而且在私有云上,还是有其他方式可以弥补安全性的不足。
1.2 解决方案:OpenStack Provider Network 模型
经过一些调研,我们最后选择了 OpenStack provider network 模型 [1]。
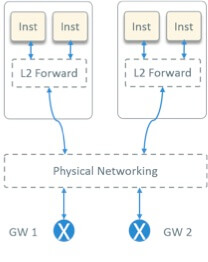
Fig 3. OpenStack Provider Network Model
如图 3 所示。宿主机内部走二层软交换,可以是 OVS、Linux Bridge、或者特定厂商的方案 ;宿主机外面,二层走交换,三层走路由,没有 overlay 封装。
这种方案有如下特点:
首先,租户网络的网关要配置在硬件设备上,因此需要硬件网络的配合,而并不是一个纯软 件的方案;
第二,实例的 IP 是可路由的,不需要走隧道;
第三,和纯软件的方案相比,性能更好,因为不需要隧道的封装和解封装,而且跨网段的路 由都是由硬件交换机完成的。
方案的一些其他方面:
- 二层使用 VLAN 做隔离
- ML2 选用 OVS,相应的 L2 agent 就是 neutron ovs agent
- 因为网关在硬件交换机上,所以我们不需要 L3 agent(OpenStack 软件实现的虚拟路由器)来做路由转发
- 不用 DHCP
- 没有 floating ip 的需求
- 出于性能考虑,我们去掉了 security group
1.3 硬件网络拓扑
图 4 是我们的物理网络拓扑,最下面是服务器机柜,上面的网络是典型的接入-汇聚-核 心三层架构。
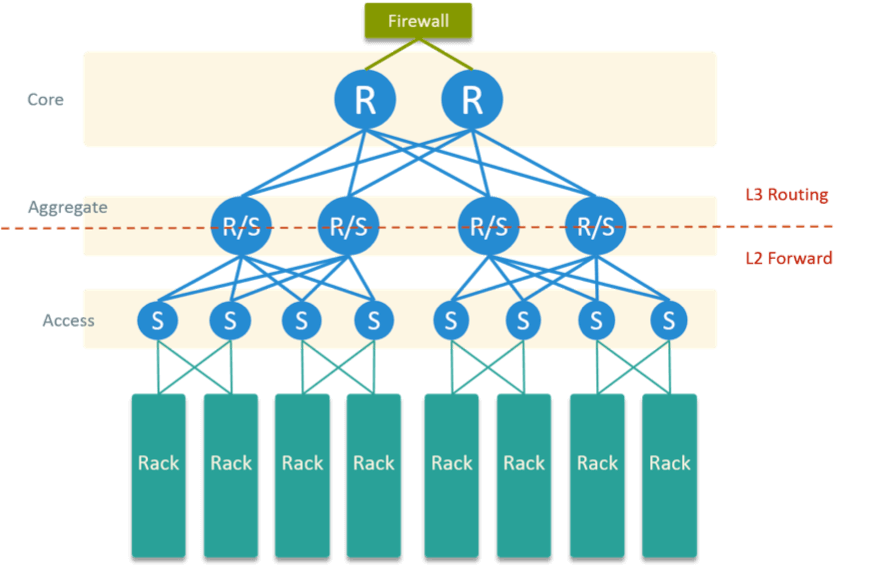
Fig 4. Physical Network Topology in the Datacenter
特点:
- 每个服务器两个物理网卡,直连到两个置顶交换机做物理高可用
- 汇聚层和接入层走二层交换,和核心层走三层路由
- 所有 OpenStack 网关配置在核心层路由器
- 防火墙和核心路由器直连,做一些安全策略
1.4 宿主机内部网络拓扑
再来看宿主机内部的网络拓扑。图 5 是一个计算节点内部的拓扑。
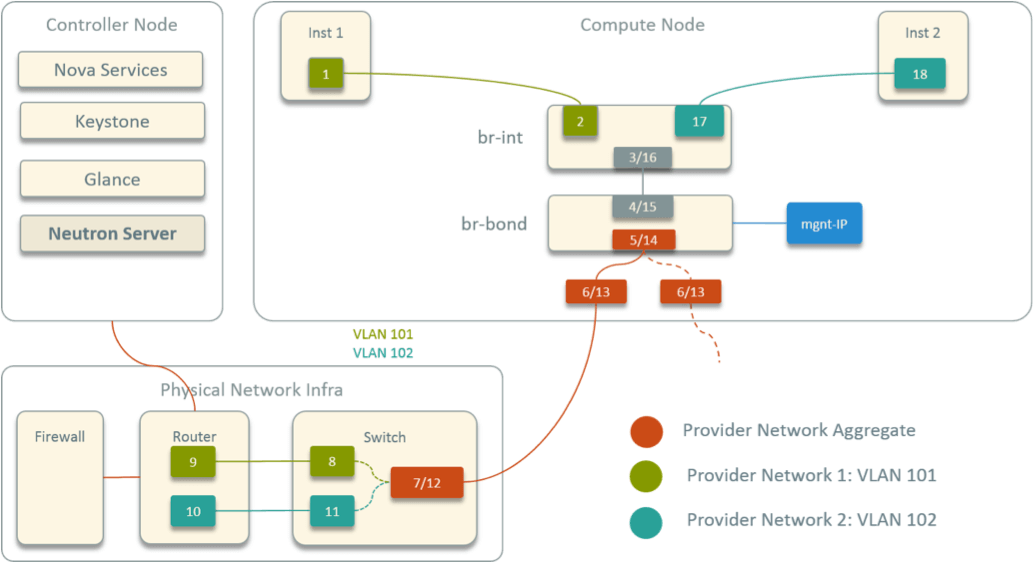
Fig 5. Designed Virtual Network Topology within A Compute Node
特点:
- 首先,在宿主机内有两个 OVS bridge:
br-int和br-bond,两个 bridge 直连 - 有两个物理网卡,通过 OVS 做 bond。宿主机的 IP 配置在
br-bond上作为管理 IP - 所有实例连接到
br-int
图中的两个实例属于不同网段,这些标数字的(虚拟和物理)设备连接起来,就是两个跨 网段的实例之间通信的路径:inst1 出来的包经 br-int 到达 br-bond,再经物理 网卡出宿主机,然后到达交换机,最后到达路由器(网关);路由转发之后,包再经类似路 径回到 inst2,总共是 18 跳。
作为对比,图 6 是原生的 OpenStack provider network 模型。
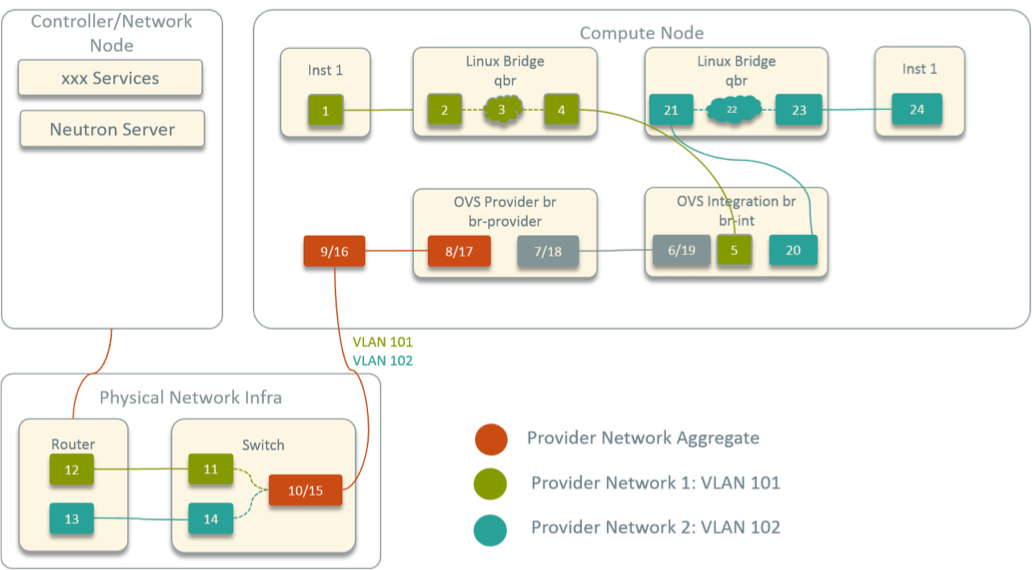
Fig 6. Virtual Network Topology within A Compute Node in Legacy OpenStack
这里最大的区别就是每个实例和 br-int 之间都多出一个 Linux bridge。这是因为原生的 OpenStack 支持通过 security group 对实例做安全策略,而 security group 底层是基于 iptables 的。OVS port 不支持 iptables 规则,而 Linux bridge port 支持,因此 OpenStack 在每个实例和 OVS 之间都插入了一个 Linux Bridge。在这种情况下,inst1 -> inst2 总共是 24 跳,比刚才多出 6 跳。
1.5 小结
最后总结一下我们第一代网络方案。
优点
首先,我们去掉了一些不用的 OpenStack 组件,例如 L3 agent、HDCP agent, Neutron meta agent 等等,简化了系统架构。对于一个刚开始做 OpenStack、经验还不是很丰 富的团队来说,开发和运维成本比较低。
第二,上面已经看到,我们去掉了 Linux Bridge,简化了宿主机内部的网络拓扑,这使得 转发路径更短,实例的网络延迟更低。
第三,网关在硬件设备上,和 OpenStack 的纯软件方案相比,性能更好。
第四,实例的 IP 可路由,给跟踪、监控等外围系统带来很大便利。
缺点
首先,去掉了 security group,没有了主机防火墙的功能,因此安全性变弱。我们通 过硬件防火墙部分地补偿了这一问题。
第二,网络资源交付过程还没有完全自动化,并且存在较大的运维风险。 provider network 模型要求网关配置在硬件设备上,在我们的方案中就是核心路由 器上。因此,每次在 OpenStack 里创建或删除网络时,都需要手动去核心交换机上做配置 。虽然说这种操作频率还是很低的,但操作核心路由器风险很大,核心发生故障会影响整张 网络。
2 基于 SDN 的大二层网络
以上就是我们在云计算时代的第一代网络方案,设计上比较简单直接,相应地,功能也比较 少。随着网络规模的扩大和近几年我们内部微服务化的推进,这套方案遇到了一些问题。
2.1 面临的新问题
首先来自硬件。做数据中心网络的同学比较清楚,三层网络架构的可扩展性比较差, 而且我们所有的 OpenStack 网关都配置在核心上,使得核心成为潜在的性能瓶颈,而核心 挂了会影响整张网络。
第二,很大的 VLAN 网络内部的泛洪,以及 VLAN 最多只有 4096 个的限制。
第三,宿主机网卡比较旧,都是 1Gbps,也很容易达到瓶颈。
另外我们也有一些新的需求:
首先,携程在这期间收购了一些公司,会有将这些收购来的公司的网络与携程的网络打通的 需求。在网络层面,我们想把它们当作租户对待,因此有多租户和 VPC 的需求。
另外,我们想让网络配置和网络资源交付更加自动化,减少运维成本与运维风险。
2.2 解决方案: OpenStack + SDN
针对以上问题和需求,数据中心网络团队和我们 cloud 网络团队一起设计了第二代网络方 案:一套基于软件+硬件、OpenStack+SDN 的方案,从二层网络演进到大二层网络。
硬件拓扑
在硬件拓扑上,从传统三层网络模型换成了近几年比较流行的 Spine-Leaf 架构,如图 7 所示。
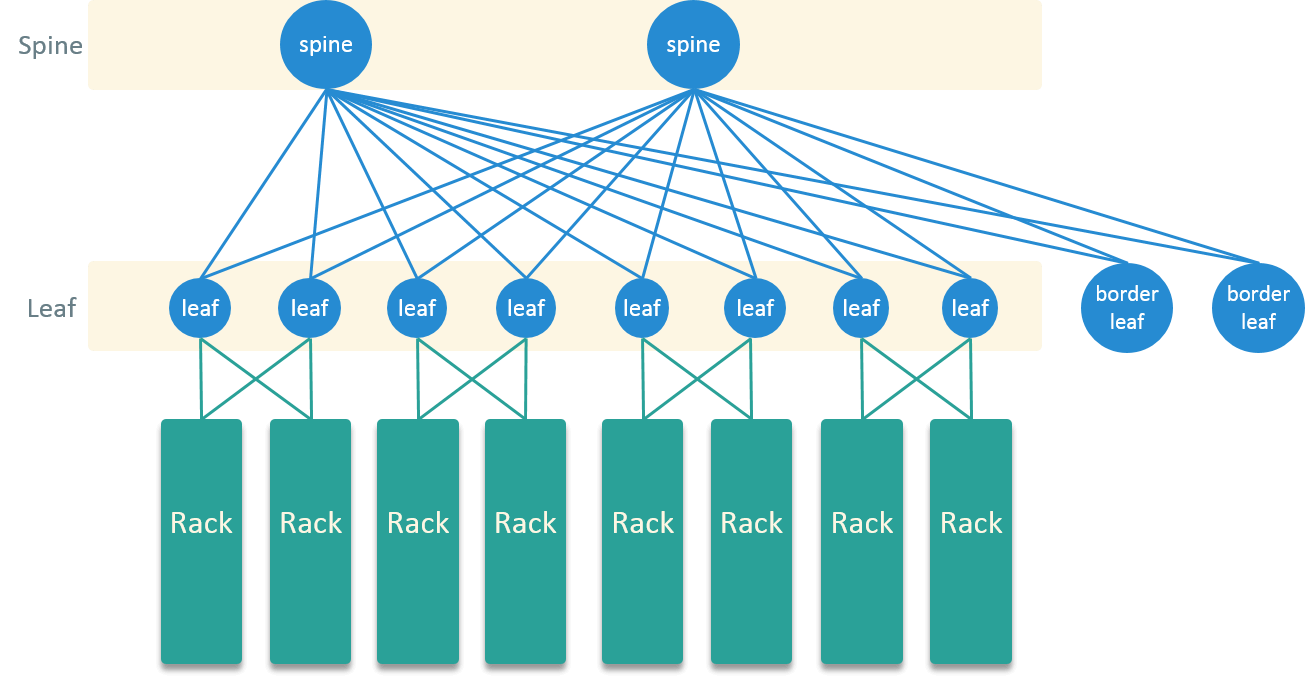
Fig 7. Spine-Leaf Topology in the New Datacenter
Spine-Leaf 是 full-mesh 连接,它可以带来如下几个好处:
第一,转发路径更短。以图 7 的 Spine-Leaf(两级 Clos 架构)为例,任何两台服务器经 过三跳(Leaf1 -> Spine -> Leaf2)就可以到达,延迟更低,并且可保障(可以按跳数精 确计算出来)。
第二,水平可扩展性更好,任何一层有带宽或性能瓶颈,只需新加一台设备,然后跟另一层 的所有设备直连。
第三,所有设备都是 active 的,一个设备挂掉之后,影响面比三层模型里挂掉一个设备小 得多。
宿主机方面,我们升级到了 10G 和 25G 的网卡。
SDN: 控制平面和数据平面
数据平面基于 VxLAN,控制平面基于 MP-BGP EVPN 协议,在设备之间同步控制平面信息。 网关是分布式的,每个 leaf 节点都是网关。VxLAN 和 MP-BGP EVPN 都是 RFC 标准协议, 更多信息参考 [2]。
VxLAN 的封装和解封装都在 leaf 完成,leaf 以下是 VLAN 网络,以上是 VxLAN 网络。
另外,这套方案在物理上支持真正的租户隔离。
SDN: 组件和实现
开发集中在以下几个方面。
首先是自研了一个 SDN 控制器,称作携程网络控制器(Ctrip Network Controller) ,缩写 CNC。CNC 是一个集中式控制器,管理网络内所有 spine 和 leaf 节点,通过 neutron plugin 与 OpenStack Neutron 集成,能够动态向交换机下发配置。
Neutron 的主要改造:
- 添加了 ML2 和 L3 两个 plugin 与 CNC 集成
- 设计了新的 port 状态机,因为原来的 port 只对 underlay 进行了建模,我们现在有 underlay 和 overlay 两个平面
- 添加了一下新的 API,用于和 CNC 交互
- 扩展了一些表结构等等
图 8 就是我们对 neutron port 状态的一个监控。如果一个 IP(port)不通,我们很容易 从它的状态看出问题是出在 underlay 还是 overlay。
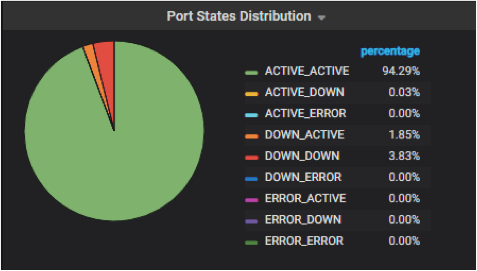
Fig 8. Monitoring Panel for Neutron Port States
2.3 软件+硬件网络拓扑
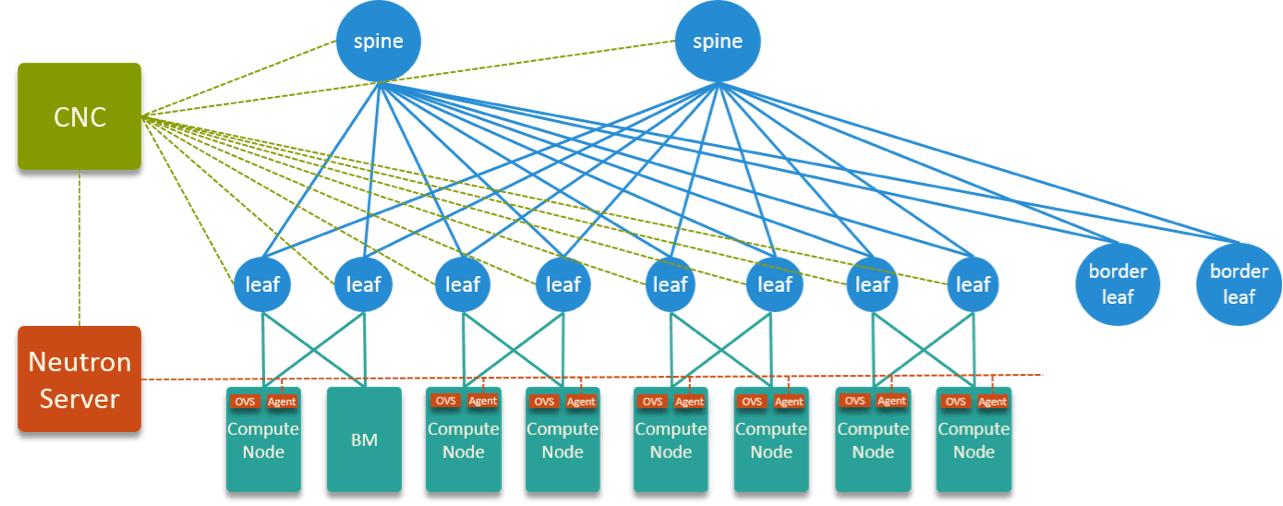
Fig 9. HW + SW Topology of the Designed SDN Solution
图 9 是我们软件+硬件的网络拓扑:
- 以 leaf 为边界,leaf 以下是 underlay,走 VLAN;上面 overlay,走 VxLAN
- underlay 由 neutron、OVS 和 neutron OVS agent 控制;overlay 是 CNC 控制
- Neutron 和 CNC 之间通过 plugin 集成
2.4 创建实例涉及的网络配置流程
这里简单来看一下创建一个实例后,它的网络是怎么通的。图 10 中黑色的线是 OpenStack 原有的逻辑,蓝色的是我们新加的。
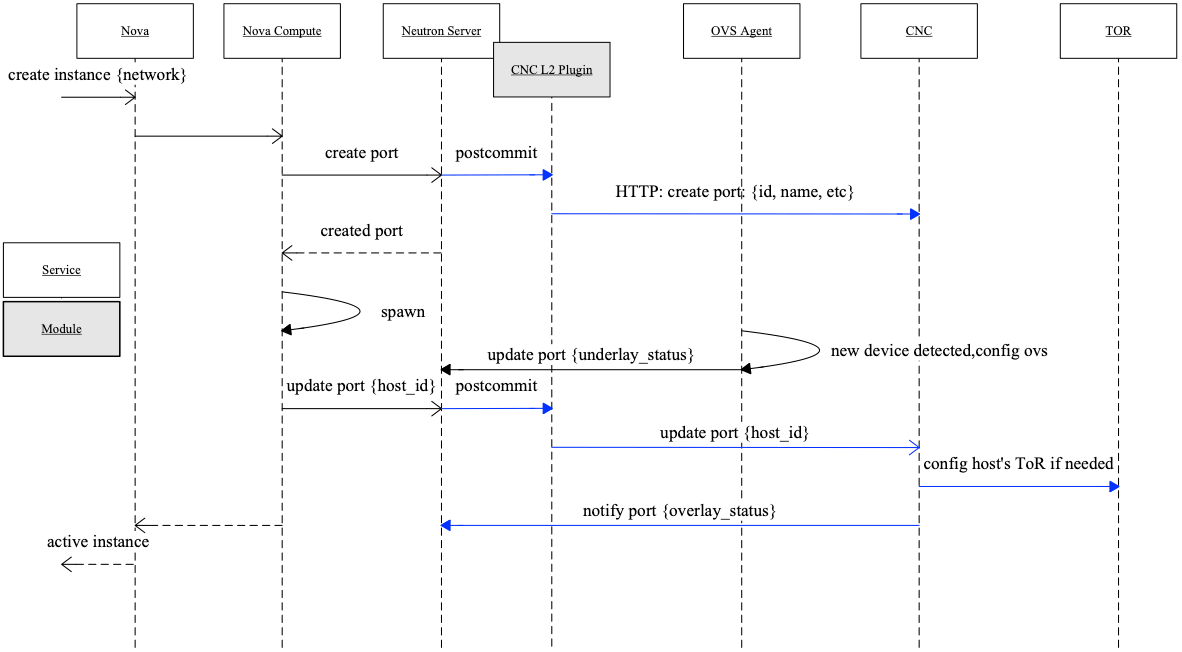
Fig 10. Flow of Spawn An Instance
- 控制节点:从 nova 发起一个创建实例请求,指定从哪个网络分配 IP 给这个实例。 nova 调度器将任务调度到某台计算节点
- 计算节点:nova compute 开始创建实例,其中一步是向 neutron 发起一个 create port 请求,简单认为就是申请一个 IP 地址
- Neutron Server: neutron 创建一个 port,然后经 create port 的 postcommit 方法 到达 CNC ML2 plugin;plugin 进一步将 port 信息同步给 CNC,CNC 将其存储到自己 的 DB
- 计算节点:port 信息从 neutron server 返回给 nova-compute
- 计算节点:nova-compute 拿到 port 信息,为实例创建虚拟网卡,配置 IP 地址等参数 ,并将其 attach 到 OVS
- 计算节点:ovs agent 检测到新的 device 后,就会为这个 device 配置 OVS,添加 flow 等,这时候 underlay 就通了,它会将 underlay 状态上报给 neutron server
- 计算节点:nova-compute 做完网络配置后,会发送一个 update port 消息给 neutron server,其中带着
host_id信息,表示这个 port 现在在哪台计算节点上 - Neutron Server: 请求会通过 postcommit 发给 CNC
- CNC:CNC 根据
host_id找到这台计算节点所连接的 leaf 的端口,然后向这些端口 动态下发配置,这时候 overlay 就通了,最后将 overlay 状态上报给 neutron server
在我们的系统里看,这时 port 就是一个 ACTIVE_ACTIVE 的状态,表示 underlay 和 overlay 配置都是正常的,网络应该是通的。
2.5 小结
总结一下我们这套方案。
硬件
首先,我们从三层网络架构演进到 Spine-Leaf 两级架构。Spine-Leaf 的 full-mesh 使得 服务器之间延迟更低、容错性更好、更易水平扩展。另外,Spine-Leaf 还支持分布式网 关,缓解了集中式网关的性能瓶颈和单点问题。
软件
自研 SDN 控制器并与 OpenStack 集成,实现了网络的动态配置。
这套方案同时支持虚拟机和应用物理机部署系统,限于篇幅这里只介绍了虚拟机。
多租户
有硬多租户(hard-multitenancy)支持能力。
3 容器和混合云网络
以上方案最开始还是针对虚拟机和应用物理机设计的。到了 2017 年,我们开始在私有云和 公有云上落地容器平台,将一部分应用从虚拟机或应用物理机迁移到容器。
容器平台(K8S、Mesos 等)有不同于虚拟机平台的一些特点,例如:
- 实例的规模很大,单个集群 10k~100k 个容器是很常见的
- 很高的发布频率,实例会频繁地创建和销毁
- 实例创建和销毁时间很短,比传统的虚拟机低至少一个数量级
- 容器的失败是很常见,总会因为各种各样的原因导致容器挂掉。容器编排引擎在设计的 时候已经把失败当做预期情况处理,例如将挂掉的容器在本机或其他宿主机再拉起来, 后者就是一次漂移
3.1 私有云的 K8S 网络方案
容器平台的这些特点对网络提出了新的需求。
3.1.1 网络需求
首先,网络服务的 API 必须要快,而且支持较大的并发。
第二,不管是 agent 还是可执行文件,为容器创建和删除网络(虚拟网络及相应配置)也要快。
最后是一个工程问题:新系统要想快速落地,就必须与很多线上系统保持前向兼容。这 给我们网络提出一个需求就是:容器漂移时,IP 要保持不变。因为 OpenStack 时代, 虚拟机迁移 IP 是不变的,所以很多外围系统都认为 IP 是实例生命周期中的一个不变量, 如果我们突然要改成 IP 可变,就会涉及大量的外围系统(例如 SOA)改造,这其中很多不 是我们所能控制的。因此为了实现容器的快速落地,就必须考虑这个需求。而流行的 K8S 网络方案都是无法支持这个功能的,因为在容器平台的设计哲学里,IP 地址已经是一个被 弱化的概念,用户更应该关心的是实例暴露的服务,而不是 IP。
3.1.2 解决方案:扩展现有 SDN 方案,接入 Mesos/K8S
在私有云中,我们最终决定对现有的为虚拟机和应用物理机设计的 SDN 方案进行扩展,将 容器网络也统一由 Neutron/CNC 管理。具体来说,会复用已有的网络基础设施,包括 Neutron、CNC、OVS、Neutron-OVS-Agent 等待,然后开发一个针对 Neutron 的 CNI 插件 (对于 K8S)。
一些核心改动或优化如下。
Neutron 改动
首先是增加了一些新的 API。比如,原来的 neutron 是按 network id 分配 IP,我们给 network 添加了 label 属性,相同 label 的 network 我们认为是无差别的。这样,CNI 申 请 IP 的时候,只需要说“我需要一个 ‘prod-env’ 网段的 IP”,neutron 就会从打了“ prod-env” label 的 network 中任选一个还没用完的,从中分一个 IP。这样既将外部系统 与 OpenStack 细节解耦,又提高了可扩展性,因为一个 label 可以对应任意多个 network 。
另外做了一些性能优化,例如增加批量分配 IP 接口、API 异步化、数据库操作优化等待。
还有就是 backport 一些新 feature 到 neutron,我们的 OpenStack 已经不随社区一起升 级了,都是按需 backport。例如,其中一个对运维和 trouble shooting 非常友好的功能 是 Graceful OVS agent restart。
K8S CNI for Neutron 插件
开发了一个 CNI plugin 对接 neutron。CNI 插件的功能比较常规:
- 为容器创建 veth pairt,并 attach 到 OVS
- 为容器配置 MAC、IP、路由等信息
但有两个特殊之处:
- 向 neutron(global IPAM)申请分配和释放 IP,而不是宿主机的本地服务分配(local IPAM)
- 将 port 信息更新到 neutron server
基础网络服务升级
另外进行了一些基础架构的升级,比如 OVS 在过去几年的使用过程中发现老版本的几个 bug,后来发现这几个问题在社区也是有记录的:
vswitchdCPU 100% [3]- 流量镜像丢包 [4]
注意到最新的 LTS 版本已经解决了这些问题,因此我们将 OVS 升级到了最新的 LTS。 大家如果有遇到类似问题,可以参考 [3, 4]。
3.1.3 容器漂移
创建一个容器后,容器网络配置的流程和图 10 类似,Nova 和 K8S 只需做如下的组件对应:
nova->kube masternova-compute -> kubeletnova network driver -> CNI
其流程不再详细介绍。这里重点介绍一下容器漂移时 IP 是如何保持不变的。
如图 11 所示,保持 IP 不变的关键是:CNI 插件能够根据容器的 labels 推导出 port name,然后拿 name 去 neutron 里获取 port 详细信息。port name 是唯一的,这个是我 们改过的,原生的 OpenStack 并不唯一。
第二个宿主机的 CNI plugin 会根据 name 找到 port 信息,配置完成后,会将新的 host_id 更新到 netron server;neutron 通知到 CNC,CNC 去原来的交换机上删除配置 ,并向新的交换机下发配置。
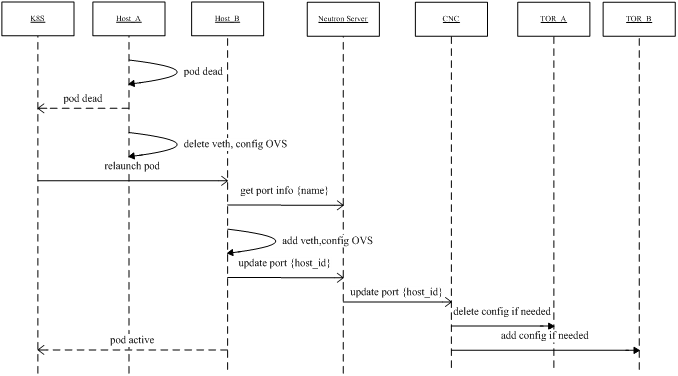
Fig 11. Pod drifting with the same IP within a K8S cluster
3.1.4 小结
简单总结一下:
- 在保持基础设施不变的情况下,我们快速地将容器平台的网络接入到已有系统
- 一个 IPAM 同时管理了虚拟机、应用物理机和容器的网络
目前这套新方案的部署规模:
- 4 个可用区
- 最大的可用区有超过 500 个节点(VM/BM/Container 宿主机),其中主要是 K8S 节点
- 单个 K8S 节点最多会有 500+ pod(测试环境的超分比较高)
- 最大的可用区有 2+ 万个实例,其中主要是容器实例
3.1.5 进一步演进方向
以上就是到目前为止我们私有云上的网络方案演讲,下面这张图是我们希望将来能达到的一 个架构。
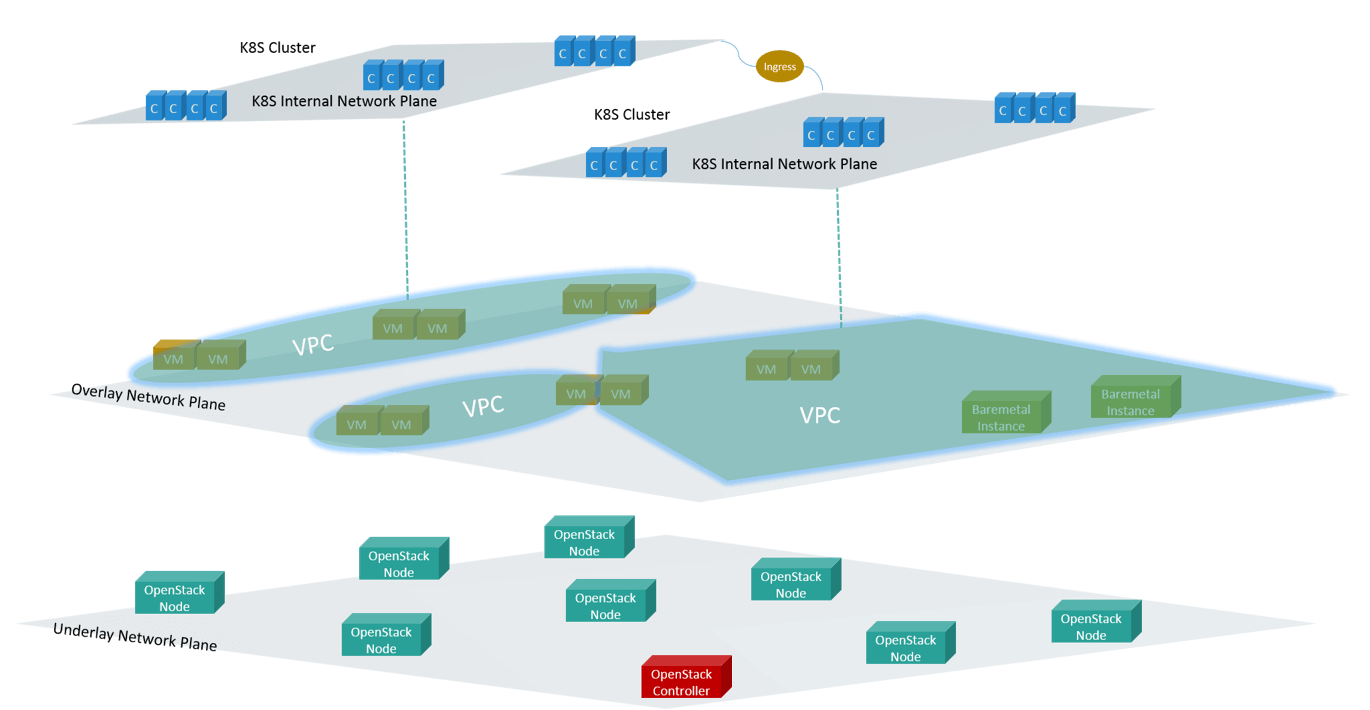
Fig 12. Layered view of the future network architecture
首先会有 underlay 和 overlay 两个平面。underlay 部署各种基础设施,包括 Openstack 控制器、计算节点、SDN 控制器等,以及各种需要运行在 underlay 的物理设备; 在 overlay 创建 VPC,在 VPC 里部署虚拟机、应用物理机实例等。
在 VPC 内创建 K8S 集群,单个 K8S 集群只会属于一个 VPC,所有跨 K8S 集群的访问都走 服务接口,例如 Ingress,现在我们还没有做到这一步,因为涉及到很多老环境的软件和硬 件改造。
3.2 公有云上的 K8S
接下来看一下我们在公有云上的网络。
3.2.1 需求
随着携程国际化战略的开展,我们需要具备在海外部署应用的能力。自建数据中心肯定是来 不及的,因此我们选择在公有云上购买虚拟机或 baremetal 机器,并搭建和维护自己的 K8S 集群(非厂商托管方案,例如 AWS EKS [10])。 在外层,我们通过 CDOS API 封装不同厂商的差异,给应用部门提供统一的接口。这样,我 们的私有云演进到了混合云的阶段。
网络方面主要涉及两方面工作:一是 K8S 的网络方案,这个可能会因厂商而已,因为不同 厂商提供的网络模型和功能可能不同;二是打通私有云和公有云。
3.2.2 AWS 上的 K8S 网络方案
以 AWS 为例来看下我们在公有云上的 K8S 网络方案。
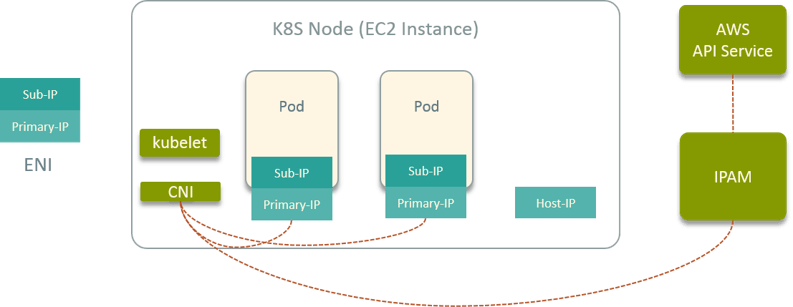
Fig 13. K8S network solution on public cloud vendor (AWS)
首先,起 EC2 实例作为 K8S node,我们自己开发一个 CNI 插件,动态向 EC2 插拔 ENI, 并把 ENI 作为网卡给容器使用。这一部分借鉴了 Lyft 和 Netflix 在 AWS 上经验 [5, 6]。
在 VPC 内,有一个全局的 IPAM,管理整个 K8S 集群的网络资源,角色和私有云中的 neutron 类似。它会调用 AWS API 实现网络资源的申请、释放和管理。
另外,我们的 CNI 还支持 attach/detach floating IP 到容器。还有就是和私有云一样, 容器漂移的时候 IP 保持不变。
3.2.3 全球 VPC 拓扑
图 14 是我们现在在全球的 VPC 分布示意图。
在上海和南通有我们的私有云 VPC;在海外,例如首尔、莫斯科、法兰克福、加州(美 西)、香港、墨尔本等地方有公有云上的 VPC,这里画的不全,实际不止这几个 region。
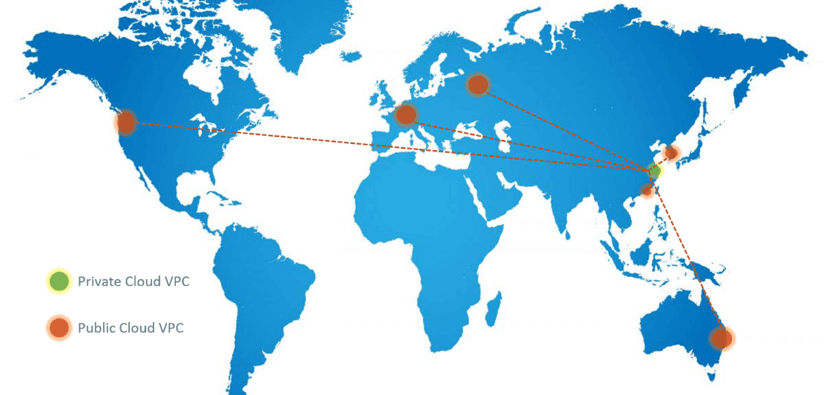
Fig 14. VPCs distributed over the globe
这些 VPC 使用的网段是经过规划的,目前不会跟内网网段重合。因此通过专线打通后,IP 可以做到可路由。
4 Cloud Native 方案探索
以上就是我们在私有云和混合云场景下的网络方案演进。目前的方案可以支持 业务未来一段的发展,但也有一些新的挑战。
首先,中心式的 IPAM 逐渐成为性能瓶颈。做过 OpenStack 的同学应该很清楚,neutron 不 是为性能设计的,而是为发布频率很低、性能要求不高的虚拟机设计的。没有优化过的话, 一次 neutron API 调用百毫秒级是很正常的,高负载的时候更慢。另外,中心式的 IPAM 也不符合容器网络的设计哲学。Cloud native 方案都倾向于 local IPAM(去中心化),即 每个 node 上有一个 IPAM,自己管理本节点的网络资源分配,calico、flannel 等流行的 网络方案都是这样的。
第二,现在我们的 IP 在整张网络都是可漂移的,因此故障范围特别大。
第三,容器的高部署密度会给大二层网络的交换机表项带来压力,这里面有一些大二层设计 本身以及硬件的限制。
另外,近年来安全受到越来越高度重视,我们有越来越强的 3-7 层主机防火墙需求。目前 基于 OVS 的方案与主流的 K8S 方案差异很大,导致很多 K8S 原生功能用不了。
针对以上问题和需求,我们进行了一些新方案的调研,包括 Calico,Cilium 等等。Calico 大家应该已经比较熟悉了,这里介绍下 Cilium。
4.1 Cilium Overview
Cilium [7]是近两年新出现的网络方案,它使用了很多内核新技术,因此对内核版本要求比 较高,需要 4.8 以上支持。
Cilium 的核心功能依赖 BPF/eBPF,这是内核里的一个沙盒虚拟机。应用程序可以通过 BPF 动态的向内核注入程序来完成很多高级功能,例如系统调用跟踪、性能分析、网络拦截 等等。Cilium 基于 BPF 做网络的连通和安全,提供 3-7 层的安策略。
Cilium 组件:
- CLI
- 存储安全策略的 repository,一般是 etcd
- 与编排引擎集成的插件:提供了 plugin 与主流的编排系统(K8S、Mesos 等)集成
- Agent,运行在每台宿主机,其中集成了 Local IPAM 功能
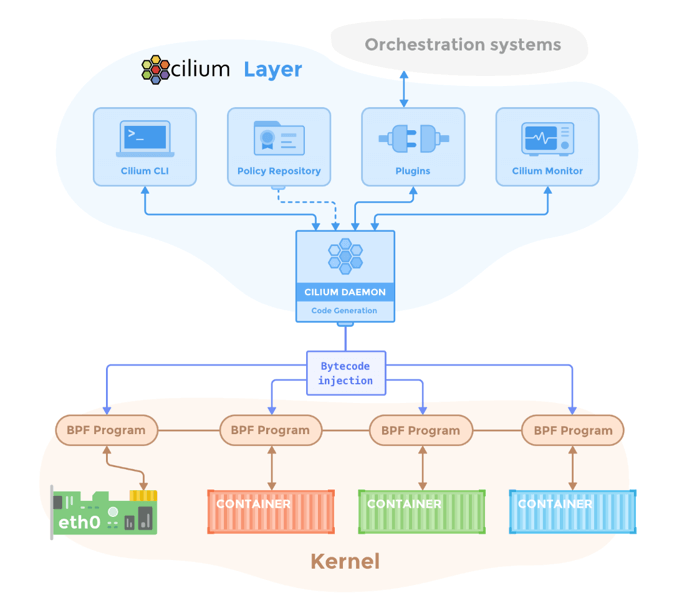
Fig 15. Cilium
4.2 宿主机内部网络通信(Host Networking)
每个网络方案都需要解决两个主要问题:
- 宿主机内部的通信:实例之间,实例和宿主机通信
- 宿主机之间的通信:跨宿主机的实例之间的通信
先来看 Cilium 宿主机内部的网络通信。
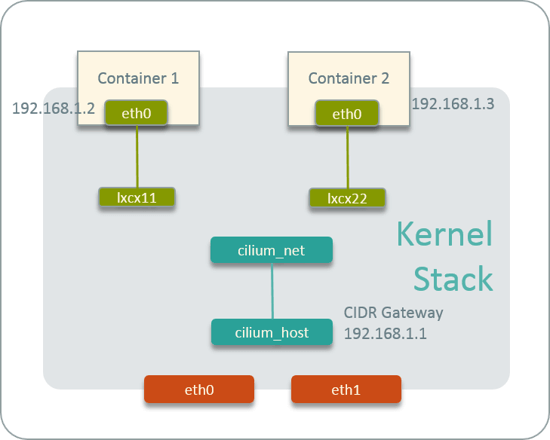
Fig 16. Cilium host-networking
Agent 首先会创建一个 cilium_host <---> cilium_net 的 veth pair,然后将它管理的 CIDR 的第一个 IP 作为网关,配置在 cilium_host 上。对于每个容器,CNI 插件 会承担创建 veth pair、配置 IP、生成 BPF 规则 等工作。
同宿主机内部的容器之间的连通性靠内核协议栈二层转发和 BPF 程序。比如 inst1 到 isnt2,包首先从 eth0 经协议栈到达 lxc11,中间再经过 BPF 规则到达 lxc22, 然后再经协议栈转发到达 inst2 的 eth0。
以传统的网络观念来看,lxc11 到 lxc22 这一跳非常怪,因为没有既没有 OVS 或 Linux bridge 这样的二层转发设备,也没有 iptables 规则或者 ARP 表项,包就神奇的到 达了另一个地方,并且 MAC 地址还被修改了。
类似地,容器和宿主机的通信走宿主机内部的三层路由和 BPF 转发,其中 BPF 程序连接容 器的 veth pair 和它的网关设备,因为容器和宿主机是两个网段。
4.3 跨宿主机网络通信(Multi-Host Networking)
跨宿主机的通信和主流的方案一样,支持两种常见方式:
- VxLAN 隧道
- BGP 直接路由
如果使用 VxLAN 方式,Cilium 会创建一个名为 cilium_vxlan 的 device 作为 VTEP, 负责封装和解封装。这种方案需要评估软件 VxLAN 的性能能否接受,以及是否需要 offload 到硬件加速。一般来说,软件 VxLAN 的方式性能较差,而且实例 IP 不可路由。
BGP 方案性能更好,而且 IP 可路由,但需要底层网络支持。这种方案需要在每个 node 上起一个 BGP agent 来和外部网络交换路由,涉及 BGP agent 的选型、AS(自治系 统)的设计等额外工作。如果是内网,一般就是 BGP agent 与硬件网络做 peering;如果 是在 AWS 之类的公有云上,还可以调用厂商提供的 BGP API。
4.4 优劣势比较(Pros & Cons)
最后总结一下 Cilium 方案的优劣势。
Pros
首先,原生支持 K8S L4-L7 安全策略,例如在 yaml 指定期望的安全效果,Cilium 会自动 将其转化为 BPF 规则。
第二,高性能策略下发(控制平面)。Calico/iptables 最大的问题之一就是集群规模大了 之后,新策略生效非常慢。iptables 是链式设计,复杂度是 O(n);而 Cilium 的复杂度 是 O(1) [11],因此性能非常好。
第三,高性能数据平面 (veth pair, IPVLAN)。
第四,原生支持双栈 (IPv4/IPv6)。事实上 Cilium 最开始只支持 IPv6,后面才添加了对 IPv4 的支持,因为他们一开始就是作为下一代技术为超大规模集群设计的。
第五,支持运行在 flannel 之上:flannel 负责网络连通性,Cilium 负责安全策略。如果 你的集群现在是 flannel 模式,迁移到 Cilium 会比较方便。
最后,非常活跃的社区。Cilium 背后是一家公司在支持,一部分核心开发者来自内核社区 ,而且同时也是 eBPF 的开发者。
Cons
首先是内核版本要求比较高,至少 4.8+,最好 4.14+,相信很多公司的内核版本是没有 这么高的。
第二,方案比较新,还没有哪家比较有名或有说服力的大厂在较大规模的生产环境部署了这 种方案,因此不知道里面有没有大坑。
第三,如果要对代码有把控(稍大规模的公司应该都有这种要求),而不仅仅是做一个用户 ,那对内核有一定的要求,例如要熟悉协议栈、包的收发路径、内核协议栈数据结构、 不错的 C 语言功底(BPF 程序是 C 写的)等等,开发和运维成本比基于 iptables 的方案 (例如 Calico)要高。
总体来说,Cilium/eBPF 是近几年出现的最令人激动的项目之一,而且还在快速发展之中。 我推荐大家有机会都上手玩一玩,发现其中的乐趣。
References
- OpenStack Doc: Networking Concepts
- Cisco Data Center Spine-and-Leaf Architecture: Design Overview
- ovs-vswitchd: Fix high cpu utilization when acquire idle lock fails
- openvswitch port mirroring only mirrors egress traffic
- Lyft CNI plugin
- Netflix: run container at scale
- Cilium Project
- Cilium Cheat Sheet
- Cilium Code Walk Through: CNI Create Network
- Amazon EKS - Managed Kubernetes Service
- Cilium: API Aware Networking & Network Security for Microservices using BPF & XDP