1.单个国家的编码
- ASCII:美国,占1个字节,只支持英文
- GB2312:中国,占2个字节,支持6700+汉字,兼容ASCII
- GBK:GB2312的升级版,支持21000+汉字,还收录了藏文、蒙文、维吾尔文等主要的的少数名族文字,同样GBK兼容ASCII编码,英文字符用1个字节来表示,汉字用两个字节来标识。
- Shift-JIS :日本字符
- ks_c_5601-1987:韩国编码
- TIS-620: 泰国编码
ascii编码(美国):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
Shift_JIS编码(日本):
私 0b10001110 0b10000100
は 0b10000010 0b11001101
ks_c_5601-1987编码(韩国):
나 0b10110011 0b10101010
는 0b10110100 0b11000010
TIS-620编码(泰国):
ฉัน 0b10101001 0b11010001 0b10111001
...
2.全球编码
(1)Unicode
(Universal Multiple-Octet Coded Character Set)2-4字节 已经收录136690个字符,并还在一直不断扩张中。
- UCS-2:两个字节编码,一共16个比特位,最多可以表示65536个字符;
- UCS-4:四个字节编码(实际上只用了31位,最高为必须为0)
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
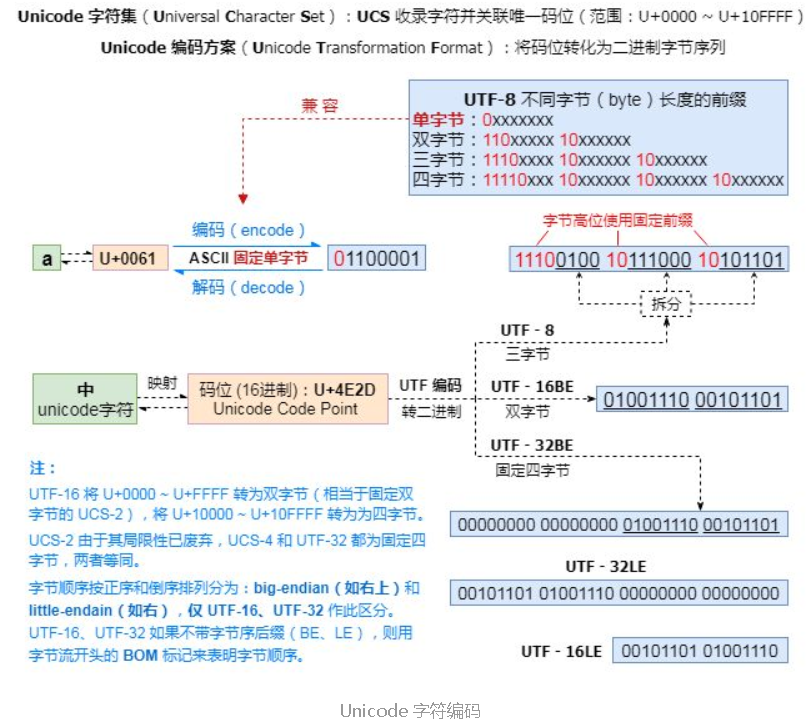
(2)UTF
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
UTF 是为unicode编码设计的一种在存储和传输时节省空间的编码方案。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示了。
这里的Unicode就像英语一样,做为国与国之间交流世界通用的标准。每个国家有自己的语言,他们把标准的英文文档翻译成自己国家的文字,这是实现方式,就像utf-8。
3.python编码
(1)本地默认编码和系统默认编码
a.本地默认编码:只跟操作系统相关,linux中是utf-8,windows中是gbk。(操作系统的编码)
- 在编写python3程序时,若使用了open()函数,而不给它传入"encoding"这个参数,那么会自动使用本地默认编码。
- 查看本地默认编码方式:打开cmd,在命令行输入chcp
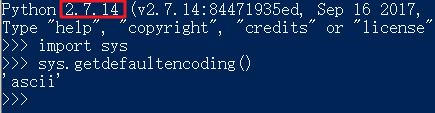
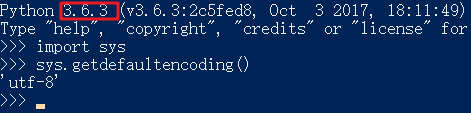
b.系统默认编码:实际是有python2和3的差异的,python2是ASCII,python3是utf-8。(不要把系统认为是操作系统,这里可以理解成python3的编译器本身。)
- 在python3编译器读取.py文件时,若没有头文件编码声明,则默认使用"utf-8"来对.py文件进行解码。并且在调用encode()这个函数时,不传参的话默认是"utf-8"
- 头文件的"coding=gbk"编码的含义:python编译器在读取该.py文件时候,应该用什么格式将它"解码",只和读取有关,所以当确定代码编辑时候用什么格式编码的,才能将相应的编码格式写入头文件。(写了它之后,并不会更改本地、系统默认编码。)
(2)执行过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode;
- 把代码字符串按照语法规则进行解释;
- 所有的变量字符都会以unicode编码声明。
(3)python2 和python3的区别
| python2 | python3 | |
|
系统默认编码 |
ASCII
|
utf-8
|
| 字符串相关数据类型 |
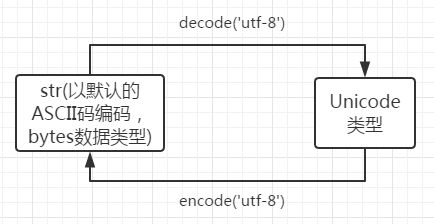
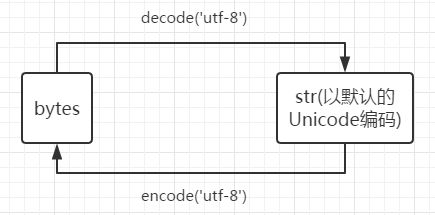
(1)str=bytes(字节数组) (2)unicode:str解码为unicode;unicode编码为str (3)相互转换
|
(1)str=unicode编码 (2)bytes=utf-8:utf-8解码为unicode (3)相互转换
|
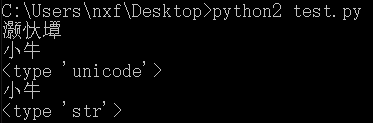
| 编码 | # coding=utf-8
s = "小牛"
print(s)
s1 = s.decode('utf-8')
print(s1)
print(type(s1))
s2 = s1.encode("GBK") # 把unicode编码成gbk
print(s2) # encode之后编码成了str
print(type(s2)) # 可以正常显示
|
想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
s = "小牛"
print(s,type(s))
s1 = s.encode("gbk")
print(s1,type(s1))
s = "小牛"
print(s,type(s))
s1 = s.encode("utf-8")
print(s1,type(s1))
|
| 解码 |
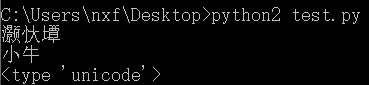
# coding=utf-8
s = "小牛"
print(s)
s1 = s.decode('utf-8')
print(s1)
print(type(s1))
|
s = "小牛"
print(s,type(s))
s1 = s.encode("utf-8")
print(s1,type(s1))
s2 = s1.decode("utf-8")
print(s2,type(s2))
|




举例:将text转换为utf-8,事先不知道text的类型
def convert_to_unicode(text):
"""Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
"""
python3 str=unicode字符串(没有解码,只有字节码才能解码);bytes解码为unicode
python2 str=字节数组(bytes);字符串解码后得到unicode
"""
if six.PY3:
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore")
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
elif six.PY2:
if isinstance(text, str):
return text.decode("utf-8", "ignore")
elif isinstance(text, unicode):
return text
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
else:
raise ValueError("Not running on Python2 or Python 3?")
4.python3编码在windows和linux下的比较
| 代码 | windows系统 | linux系统 |
import sys, locale
s = "小甲"
print(s)
print(type(s))
print(sys.getdefaultencoding())#系统默认编码
print(locale.getdefaultlocale())#本地默认编码
with open("utf1","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk1","w",encoding = "gbk") as f:
f.write(s)
with open("jis1","w",encoding = "shift-jis") as f:
f.write(s)
|
小甲 <classs 'str'> utf-8 ('zh_CN','cp936') utf1:小甲 gbk1:小甲 jis1:彫峛 |
|
#coding=gbk
import sys, locale
s = "小甲"
print(s)
print(type(s))
print(sys.getdefaultencoding())
print(locale.getdefaultlocale())
with open("utf2","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk2","w",encoding = "gbk") as f:
f.write(s)
with open("jis2","w",encoding = "shift-jis") as f:
f.write(s)
|
灏忕敳
<class 'str'>
utf-8
('zn_CN', 'cp936')
Traceback (most recent call last):
File "test.py", line 15, in <module>
f.write(s)
UnicodeEncodeError: 'shift_jis' codec can't encode character 'u704f' in position 0: illegal multibyte sequence
|
灏忕敳
<class 'str'>
utf-8
('en_US', 'UTF-8')
Traceback (most recent call last):
File "2", line 15, in <module>
f.write(s)
UnicodeEncodeError: 'shift_jis' codec can't encode character 'u704f' in position 0: illegal multibyte sequence
|
#coding=shift-jis
import sys, locale
s = "小甲"
print(s)
print(type(s))
print(sys.getdefaultencoding())
print(locale.getdefaultlocale(), "
")
a = s.encode("shift-jis")
print(a)
print(type(a))
b = a.decode("utf-8")
print(b)
print(type(b))
print(a.decode("gbk"))
with open("utf3","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk3","w",encoding = "gbk") as f:
f.write(s)
with open("jis3","w",encoding = "shift-jis") as f:
f.write(s)
|
蟆冗抜
<class 'str'>
utf-8
('zn_CN', 'cp936')
b'xe5xb0x8fxe7x94xb2'
<class 'bytes'>
小甲
<class 'str'>
灏忕敳
|
蟆冗抜
<class 'str'>
utf-8
('en_US', 'UTF-8')
b'xe5xb0x8fxe7x94xb2'
<class 'bytes'>
小甲
<class 'str'>
灏忕敳
|
5.其他技巧
(1)对于如unicode形式的字符串(str类型)
s = 'idpythonu003d215903184u0026indexu003d0u0026stu003d52u0026sid'
转换成真正的unicode需要使用
s.decode('unicode-escape')
举例:
s = 'idu003d215903184u0026indexu003d0u0026stu003d52u0026sid'
print(type(s))
s1 = s.decode('unicode-escape')
print(s1)
print(type(s1))

(2)常见编码错误原因:
- python解释器的默认编码
- pthon源文件文件编码
- terminal使用的编码
- 操作系统的语言设置
参考文献: