参考url:
https://jakevdp.github.io/PythonDataScienceHandbook/index.html
Scikit-Learn为各种常用机器学习算法提供了高效版本,因其干净、统一、管道命令式的API而独具特色,且其在线文档实用、完整。
1、Scikit-Learn的数据表示
Scikit-Learn认为数据表示最好的方法就是用数据表的形式。
1、数据表
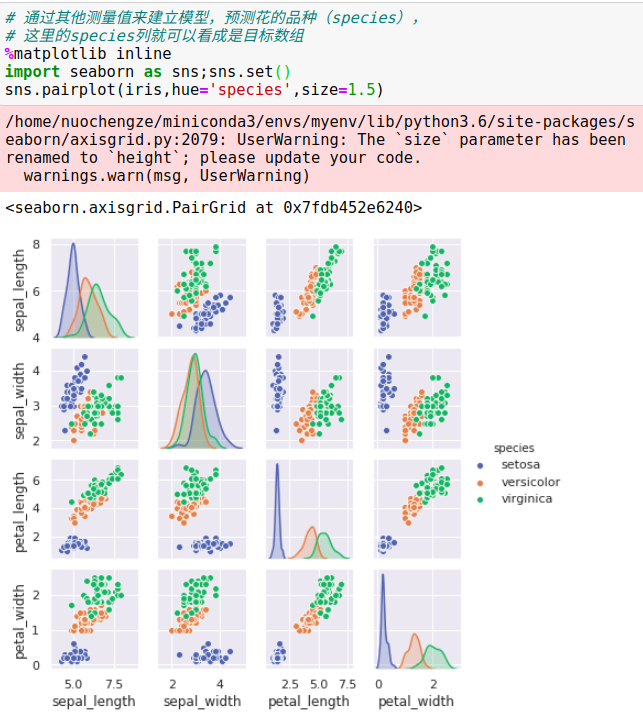
基本的数据表就是二维网格数据,其中的每一行表示数据集中的每个样本,而列表示构成每个样本的相关特征。

其中的每行数据表示每朵被观察的鸢尾花,行数表示数据集中记录的鸢尾花总数
一般情况下,会将这个矩阵的行称为样本(samples),行数记为n_samples。
其中的每列数据表示每个样本某个特征的量化值
一般情况下,会将矩阵的列称为特征(features),列数记为n_features。
2、特征矩阵
数据表布局通过二维数组或矩阵的形式将信息清晰地表达出来,则把这类矩阵称为特征矩阵。
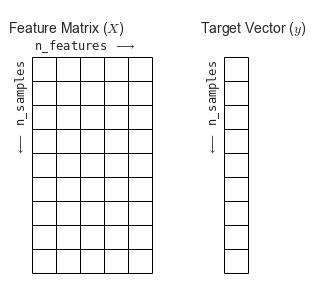
特征矩阵通常被简记为变量X,它是维度为[n_samples,n_features]的二维矩阵,通常可以用NumPy数组或Pandas的DataFrame来表示,不过Scikit-Learn也支持SciPy的稀疏矩阵。
样本(即每一行)通常是值数据集中的每个对象,是任何可以通过一组量化方法进行测量的实体。
特征(即每一列)通常是指每个样本都具有的某种量化观测值,一般情况下为实数,有时为布尔类型或离散值。
3、目标数组
一个标签或目标数组,通常简记为y。
目标数组一般是一维数组,其长度就是样本总数n_samples,通常都用一维的numpy数组或pandas的Series表示。
目标数组可以是连续的数值类型,也可以是离散的类型/标签。
区分目标数组的特征与特征矩阵中的特征列:
目标数组的特征通常是我们希望从数据中预测的量化结果,即y是统计学中的因变量。

特征矩阵和目标数组的布局:
2、Scikit-Learn的评估器API
Scikit-Learn API主要遵照以下设计原则:
统一性:所有对象使用共同接口连接一组方法和统一的文档
内省:所有参数值都是公共属性
限制对象层级:只有算法可以用Python表示,数据集都用标准数据类型(numpy数组、Pandas的DataFrame、SciPy稀疏矩阵)表示,参数名称用标准的Python字符串。
函数组合:许多机器学习任务都可以用一串基本算法实现。
明智的默认值:当模型需要用户设置参数时,Scikit-Learn预先定义适当的默认值。
Scikit-Learn中的所有机器学习算法都是通过评估器API实现的,它为各种机器学习应用提供了统一的接口。
1、API基础知识
Scikit-Learn评估器API的常用步骤如下:
(1)通过从Scikit-Learn中导入适当的评估器类,选择模型类
(2)用合适的数值对模型类进行实例化,配置模型超参数(hyperparameter)
(3)整理数据,通过前面介绍的方法获取特征矩阵和目标数组

(4)调用模型实例的fit()方法对数据进行拟合
(5)对新数据应用模型:
a、在有监督学习模型中,通常使用predict()方法预测新数据的标签。
b、在无监督学习模型中,通常使用transform()或predict()方法转换或推断数据的性质。
2、有监督学习示例:简单线性回归
创建线性回归样本数据
(1)选择模型类
在Scikit-Learn中,每个模型类都是一个Python类。
线性模型可以参考sklearn.linear_model模块中的文档

(2)选择模型超参数
选择模型超参数时考虑一下问题:
a、是否拟合偏移量(即直线的截距)
b、是否对模型进行归一化处理
c、是否对特征进行预处理以提高模型灵活性
d、是否在模型中使用某种正则化类型
e、打算使用多少模型组件
超参数为在模型拟合数据之前必须被确定的参数。
在Scikit-Learn中,通常在模型初始化阶段选择超参数。
对模型进行实例化其实仅仅是存储了超参数的值,还没有将模型应用到数据上。
Scikit-Learn的API对选择模型和将模型应用到数据区别得很清晰。

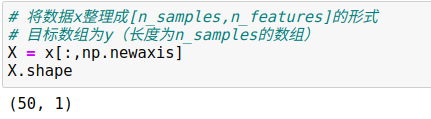
(3)将数据整理成特征矩阵和目标数组
(4)用模型拟合数据

fit()命令会在模型内部进行大量运算,运算结果将存储在模型属性中,供用户使用。
在Scikit-Learn中,所有通过fit()方法获得的模型参数都带一条下划线。

(5)预测新数据的标签
模型训练出来后,有监督机器学习将对不属于训练集的新数据进行预测。
在Scikit-Learn中,用predict()方法进行预测。

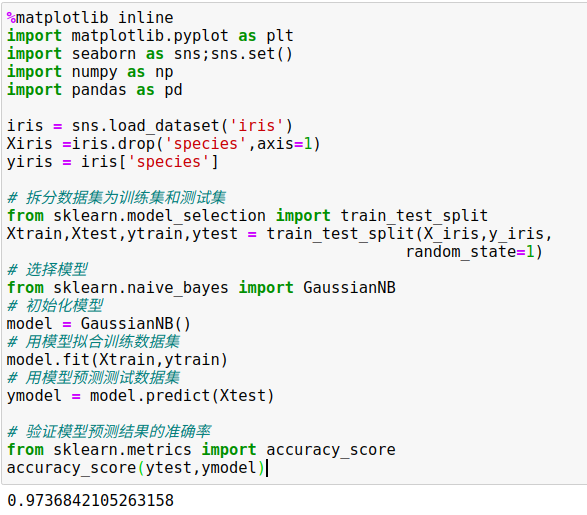
3、有监督学习示例:鸢尾花数据分类
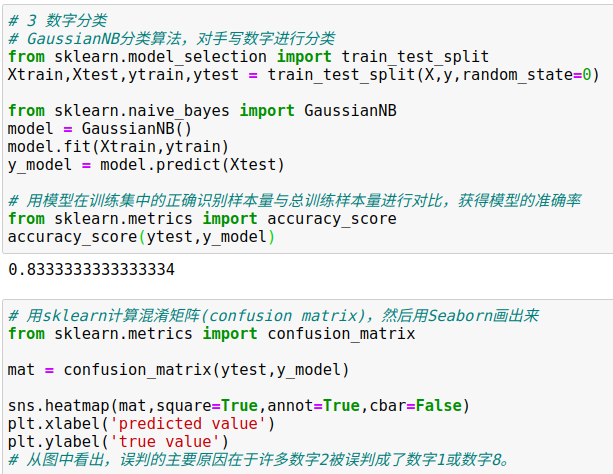
使用高斯朴素贝叶斯(Gaussian naive Bayes)方法,这个方法假设每个特征中属于每一类的观测值都符合高斯分布。
借助train_test_split函数将数据分隔成训练集(training set)和测试集(testing set)。
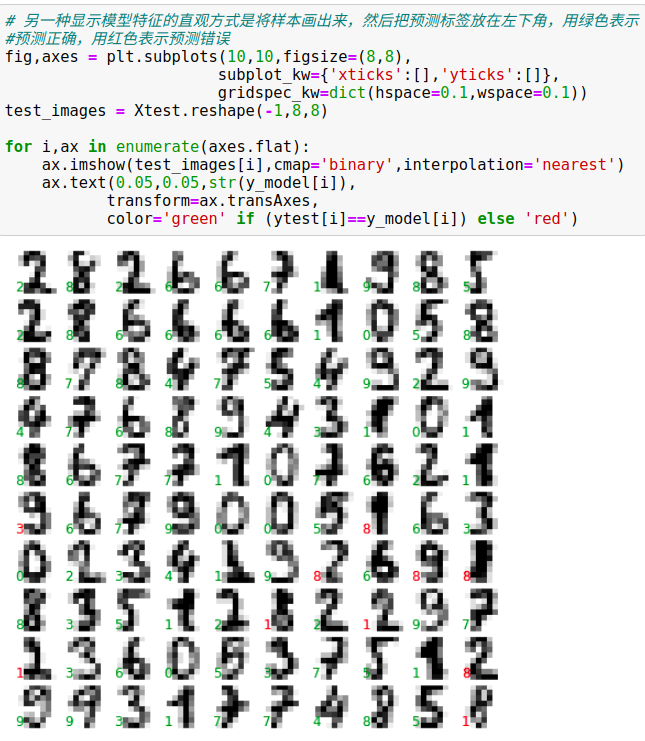
用accuracy_score工具验证模型预测结果的准确率(预测的所有结果中,正确的结果占总预测样本数的比例)
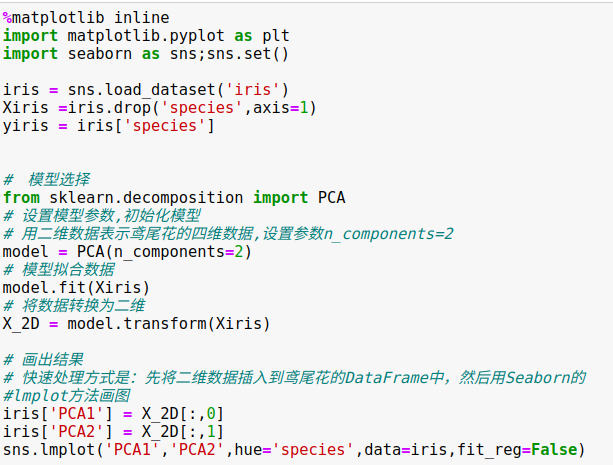
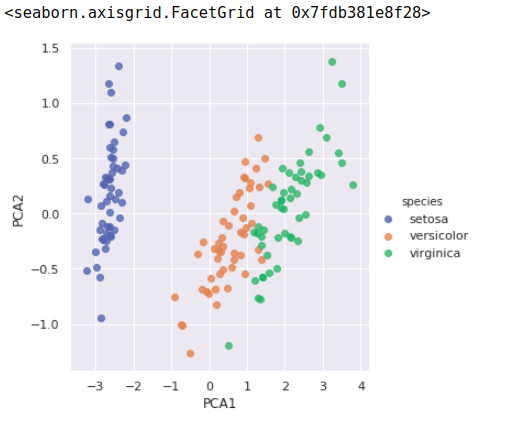
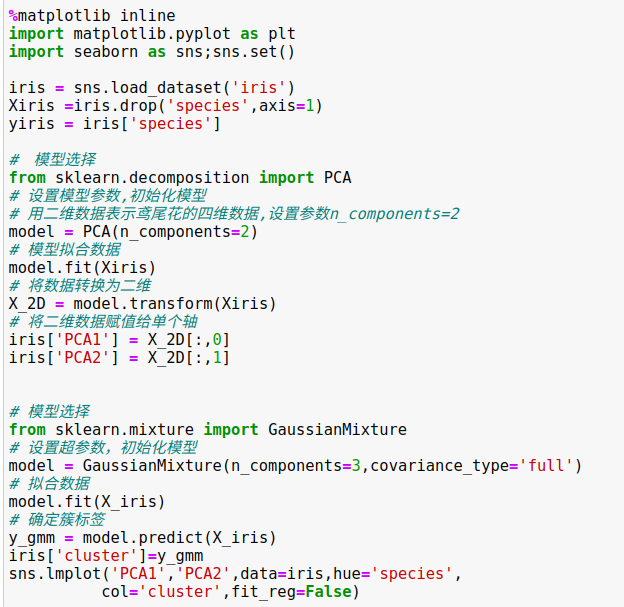
4、无监督学习示例:鸢尾花数据降维
鸢尾花数据集由四个维度构成,即每个样本都有四个维度
降维的任务是要找到一个可以保留数据本质特征的低维矩阵来表示高维数据。
使用主成分分析(principal component analysis,PCA)方法降维,这是一种快速线性降维技术。
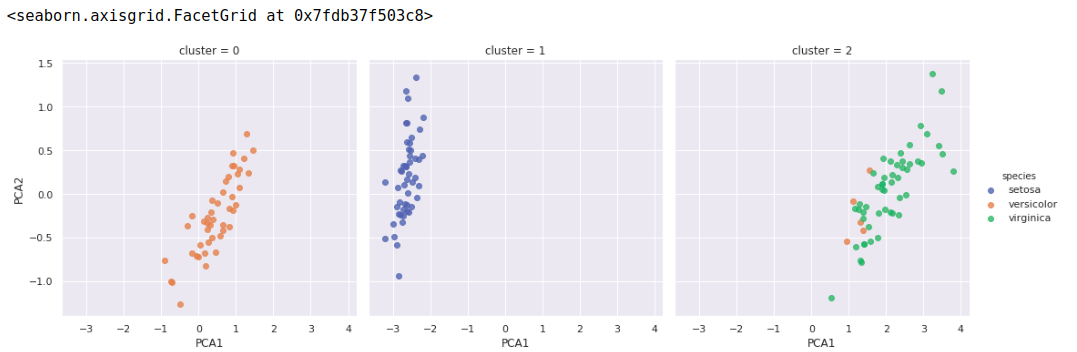
5、五监督学习示例:鸢尾花数据聚类
聚类算法是要对没有任何标签的数据集进行分组。
聚类方法高斯混合模型(Gaussian mixture model,GMM),试图将数据构造成若干服从高斯分布的概率密度函数簇。
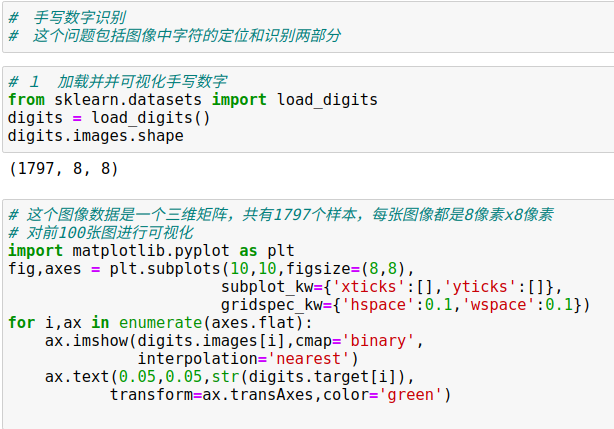
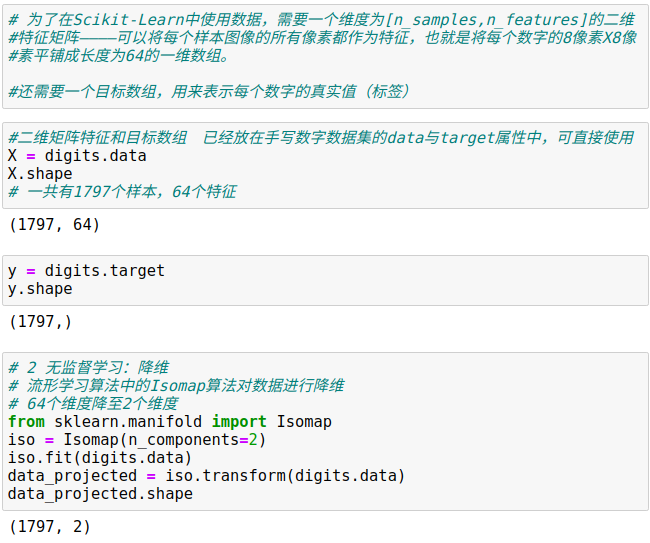
3、应用:手写数字探索