正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合。
Go语言通过regexp标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对Go语言版本的不会太陌生,但是它们之间也有一些小的差异,因为Go实现的是RE2标准,除了C,详细的语法描述参考:http://code.google.com/p/re2/wiki/Syntax
其实字符串处理我们可以使用strings包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果strings包能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都会比正则好。
一、正则匹配规则图
参考官网: https://studygolang.com/pkgdoc
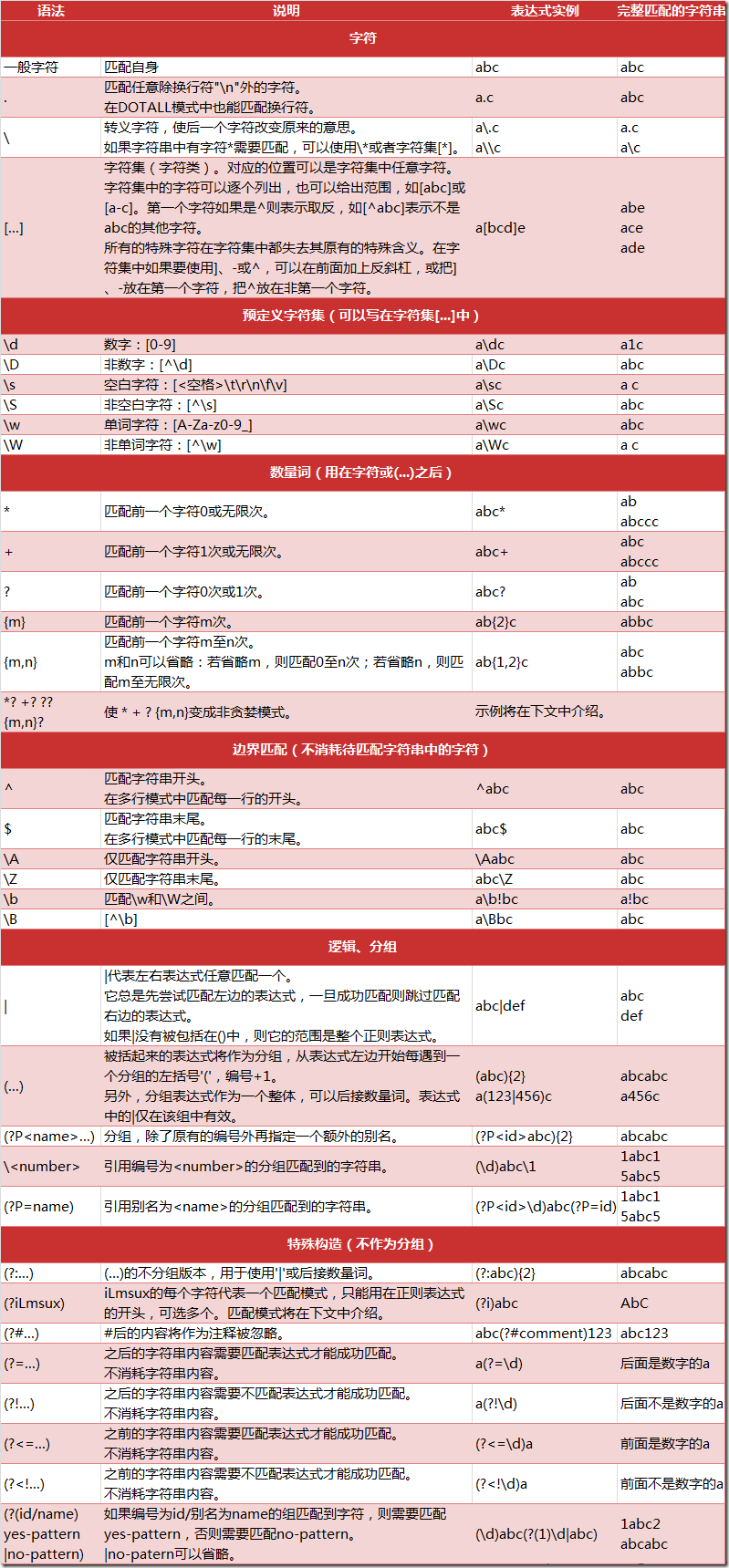
二、正则表达式
示例1: . 匹配任意类型
package main
import (
"fmt"
"regexp"
)
func main() {
buf := "abc azc a7c aac 888 a9c tac"
//1) 解释规则, 它会解析正则表达式,如果成功返回解释器
reg1 := regexp.MustCompile(`a.c`)
if reg1 == nil {
fmt.Println("regexp err")
return
}
//2) 根据规则提取关键信息
result1 := reg1.FindAllStringSubmatch(buf, -1)
fmt.Println("result1 = ", result1)
}
#执行结果:
result1 = [[abc] [azc] [a7c] [aac] [a9c]]
2、匹配a[0-9]c之间的数值
示例2:
package main
import (
"fmt"
"regexp"
)
func main() {
buf := "abc azc a7c aac 888 a9c tac"
//1) 解释规则, 它会解析正则表达式,如果成功返回解释器
reg1 := regexp.MustCompile(`a[0-9]c`)
if reg1 == nil { //解释失败,返回nil
fmt.Println("regexp err")
return
}
//2) 根据规则提取关键信息
result1 := reg1.FindAllStringSubmatch(buf, -1)
fmt.Println("result1 = ", result1)
}
执行结果:
result1 = [[a7c] [a9c]]
3、d 匹配a[0-9]c之间的数值
示例3:
package main
import (
"fmt"
"regexp"
)
func main() {
buf := "abc azc a7c aac 888 a9c tac"
//1) 解释规则, 它会解析正则表达式,如果成功返回解释器
reg1 := regexp.MustCompile(`adc`)
if reg1 == nil { //解释失败,返回nil
fmt.Println("regexp err")
return
}
//2) 根据规则提取关键信息
result1 := reg1.FindAllStringSubmatch(buf, -1)
fmt.Println("result1 = ", result1)
}
执行结果:
result1 = [[a7c] [a9c]]
4、 +匹配前一个字符的1次或多次
示例:
package main
import (
"fmt"
"regexp"
)
func main() {
buf := "43.14 567 agsdg 1.23 7. 8.9 1sdljgl 6.66 7.8 "
//解释正则表达式, +匹配前一个字符的1次或多次
reg := regexp.MustCompile(`d+.d+`)
if reg == nil {
fmt.Println("MustCompile err")
return
}
//提取关键信息
//result := reg.FindAllString(buf, -1)
result := reg.FindAllStringSubmatch(buf, -1)
fmt.Println("result = ", result)
}
执行结果:
result = [[43.14] [1.23] [8.9] [6.66] [7.8]]
5、过滤带标签或不带标签的
package main
import (
"fmt"
"regexp"
)
func main() {
//`` 原生字符串
buf := `
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<title>Go语言标准库文档中文版 | Go语言中文网 | Golang中文社区 | Golang中国</title>
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1.0, user-scalable=no">
<meta http-equiv="X-UA-Compatible" content="IE=edge, chrome=1">
<meta charset="utf-8">
<link rel="shortcut icon" href="/static/img/go.ico">
<link rel="apple-touch-icon" type="image/png" href="/static/img/logo2.png">
<meta name="author" content="polaris <polaris@studygolang.com>">
<meta name="keywords" content="中文, 文档, 标准库, Go语言,Golang,Go社区,Go中文社区,Golang中文社区,Go语言社区,Go语言学习,学习Go语言,Go语言学习园地,Golang 中国,Golang中国,Golang China, Go语言论坛, Go语言中文网">
<meta name="description" content="Go语言文档中文版,Go语言中文网,中国 Golang 社区,Go语言学习园地,致力于构建完善的 Golang 中文社区,Go语言爱好者的学习家园。分享 Go 语言知识,交流使用经验">
</head>
<div>和爱好</div>
<div>哈哈
你在吗
不在
</div>
<div>测试</div>
<div>你过来啊</div>
<frameset cols="15,85">
<frame src="/static/pkgdoc/i.html">
<frame name="main" src="/static/pkgdoc/main.html" tppabs="main.html" >
<noframes>
</noframes>
</frameset>
</html>
`
//解释正则表达式, +匹配前一个字符的1次或多次
//reg := regexp.MustCompile(`<div>(.*)</div>`)
reg := regexp.MustCompile(`<div>(?s:(.*?))</div>`)
if reg == nil {
fmt.Println("MustCompile err")
return
}
//提取关键信息
result := reg.FindAllStringSubmatch(buf, -1)
//fmt.Println("result = ", result)
//过滤<></>
for _, text := range result {
//过滤带标签的
//fmt.Println("text[0] = ", text[0]) //带<></>
//过滤不带标签的
fmt.Println("text[1] = ", text[1]) //不带<></>
}
}
#执行结果:
过滤带标签的
text[0] = <div>和爱好</div> text[0] = <div>哈哈 你在吗 不在 </div> text[0] = <div>测试</div> text[0] = <div>你过来啊</div>
//过滤不带标签的
text[1] = 和爱好 text[1] = 哈哈 你在吗 不在 text[1] = 测试 text[1] = 你过来啊