基于Docker搭建大数据集群(六)Hive搭建
前言
之前搭建的都是1.x版本,这次搭建的是hive3.1.2版本的。。还是有一点细节不一样的
Hive现在解析引擎可以选择spark,我是用spark做解析引擎的,存储还是用的HDFS
我是在docker里面搭建的集群,所以都是基于docker操作的
一、安装包准备
二、版本兼容
我使用的相关软件版本
- Hadoop ~ 2.7.7
- Spark ~ 2.4.4
- JDK ~ 1.8.0_221
- Scala ~ 2.12.9
三、环境准备
(1)解压hive压缩包
tar xivf apache-hive-3.1.2-bin -C /opt/hive/
(2)新建一个日志目录
mdkir /opt/hive/iotmp
原因
Hive启动时获取的 ${system:java.io.tmpdir} ${system:user.name}这两个变量获取绝对值有误,需要手动指定真实路径,替换其默认路径
报错截图
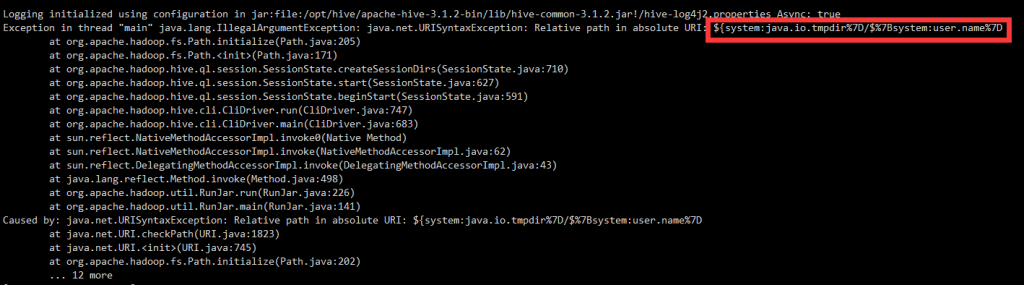
解决措施
将hive-site.xml配置里面所有相关变量全部替换掉
VI编辑器替换命令
:%s/${system:java.io.tmpdir}//opt/hive/iotmp/g
:%s/${system:user.name}/huan/g
(3)在MySQL上新建一个数据库用于存放元数据
create database hive;
(4)环境变量配置
- HIVE_OHME
- HADOOP_HOME
- SPARK_HOME
- JAVA_HOME
四、jar包
1. MySQL驱动
2. 将hive的jline包替换到hadoop的yarn下
mv /opt/hive/apache-hive-3.1.2-bin/lib/jline-2.12.jar /opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/
3.将MySQL驱动放到hive的lib目录下
4.同步jar包到client节点
五、配置
我是用的是远程分布式架构,一个master提供服务,3个client远程连接master
第一步:复制或新建一个hvie-site.xml配置文件
cp hive-default.xml.template hive-site.xml
第二步:修改master节点配置文件
1. 使用mysql替换默认的derby存放元数据
<!--元数据库修改为MySQL-->
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description>
Expects one of [derby, oracle, mysql, mssql, postgres].
Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.
</description>
</property>
<!--MySQL 驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--MySQL URL-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.11.46:13306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<!--MySQL 用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<!--MySQL 密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
<property>
2.设置解析引擎为spark
<property>
<name>hive.execution.engine</name>
<value>spark</value>
<description>
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
</description>
</property>
3. 自动初始化元数据
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.
</description>
</property>
4. 关闭校验
<!--听说是JDK版本使用1.8的问题。。-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.conf.validation</name>
<value>false</value>
<description>Enables type checking for registered Hive configurations</description>
</property>
5. 删除 description 中的 ,这个解析会报错
<property>
<name>hive.txn.xlock.iow</name>
<value>true</value>
<description>
Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks fortransactional tables. This ensures that inserts (w/o overwrite) running concurrently
are not hidden by the INSERT OVERWRITE.
</description>
</property>
第三步:将hive-site.xml发送到client结点
scp hive-site.xml 目的结点IP或目的结点主机名:目的主机保存目录
第四步:修改client节点的hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://cluster-master:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
6. 替换相对路径
:%s/${system:java.io.tmpdir}//opt/hive/iotmp/g
:%s/${system:user.name}/huan/g
六、启动
master节点
启动时会自动初始化元数据,可以查看数据库是否有表生成
./hive --service metastore &
client节点
hive