在发表本篇随笔的时候,距离上一次发已经有一个多月了,很多朋友私信我为什么不持续更新了,在这里先跟大家说声抱歉。因为年底的工作较为繁重,实在分不出精力,更重要的也是在思考后面进阶的部分要按怎样的顺序写,对于初学者来说更友好,更容易理解,希望我的文章能帮到更多的喜欢python,想要学习python的人,前面的文章我也会及时更新知识点和排版,2018年希望喜欢我文章的人能继续支持,谢谢大家!
1、 继承
1.1 继承的实现
对一个程序员来说,如果他的代码中出现大量重复的代码,那么很快就会面临被开除了。函数可以有效的避免代码的重复,而继承,也能在最大程度解决这一问题,如果两个类有很多相同的属性,就可以通过继承来实现。
继承指的是类与类之间的关系,在Python中,继承分为单继承和多继承,即可以同时继承一个或多个类,被继承的类称为基类或超类,继承其他类的类称为子类或派生类。继承的方式很简单,通过“class+子类(父类)”的方式来实现,如下:
1 class parent_class_1: 2 pass #创建父类1 3 class parent_class_2: 4 pass #创建父类2 5 class sub1_class(parent_class_1): 6 pass #创建子类sub_class,继承父类parent_class_1(单继承) 7 class sub2_class(parent_class_1,parent_class_2): 8 pass #创建子类sub_class,通过“,”来分割,继承多个父类
在使用多继承的时候,如果继承的所有父类中,都有相同的方法名,即父类1中有write()方法,父类2中也有一个write()方法,当一个类同时继承这两个类,如果子类调用调用write()方法,该调用哪个父类的write()方法?此时会遵循一个原则,先继承的类中的方法会重写后继承的类中的方法(使其不可访问),所以注意继承父类的顺序是很重要的。多继承的方法也是不建议多使用的。
通过__base__方法和__bases__方法来查看继承的父类是哪一个。
__base__:从左到右查看子类第一个继承的父类,只返回第一个父类;
__bases__:查看子类继承的所有类,返回继承的所有父类。
1 print(sub1_class.__base__) #查看sub1_class继承的第一个父类 2 3 print(sub2_class.__bases__) #查看sub2_class 都继承了哪些父类
运行结果:
1 <class '__main__.parent_class_1'> 2 3 (<class '__main__.parent_class_1'>, <class'__main__.parent_class_2'>)
继承,就像是继承家产一样,父亲有的东西,继承过来自己就也有了,所以,当一个类继承了某一个父类的话,那么这个子类就可以调用继承的父类中的所有属性。可以看下如下这个简单的例子:
1 class parent_class: #创建父类 2 money = 1000000000 #定义一个类属性:money 3 def cost(self): #定义一个方法:cost() 4 print("如果你继承了,我的钱你都可以花") 5 class sub_class(parent_class): #创建子类,继承parent_class这个父类 6 pass #类代码逻辑为空 7 print(sub_class.money) #通过子类,调用父类的属性 8 sub_class.cost(sub_class) #通过子类,调用父类的方法 9 运行结果: 10 1000000000
11 如果你继承了,我的钱你都可以花
在上面这个例子中,在创建父类parent_class的时候,定义了一个类属性和类方法,而在创建子类sub_class的时候,类里面没有写任何逻辑代码,仅仅是在创建子类的时候继承了父类,那么也就意味着,这个子类就可以调用父类中的所有属性和方法。
1..2 继承的基本原理和继承顺序
在Python中,对于定义的每一个类,Python内部都会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表。
Python如果继承了多个类,那么在继承的顺序上,遵循两种方式:深度优先和广度优先,如下图:
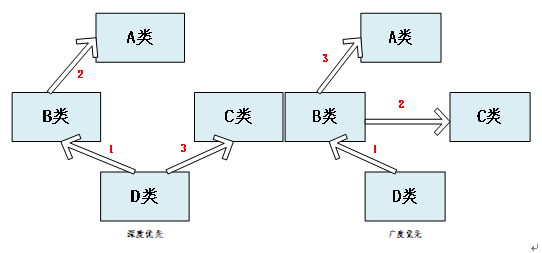
当类是经典类的时候,多继承的情况下,会按照深度优先的方式查找
当类是新式类的时候,多继承的情况下,会按照广度优先的方式查找
在Python3中,创建的类都是新式类,所以都会按照广度有限的方式进行查找什么是广式类呢?可以理解为:横向优先检索。如下:
1 class A: 2 def test(self): 3 print("A") 4 class B(A): 5 def test(self): 6 print("B") 7 class C(A): 8 def test(self): 9 print("C") 10 class D(C,B): 11 pass 12 #__mro__方法,打印出类继承的线性顺序列表 13 print(D.__mro__) 14 D.__mro__运行结果: 15 (<class '__main__.D'>, <class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>)
在继承顺序上,Python内部会在mro列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止,mro线性列表包含以下两个原则:
1)子类优于父类,即如果在D类定义了test函数,那么它会优先调用自己类内部的test方法
2)继承多个父类会根据它们在列表中的顺序被子类继承,即如果是class D(B,C)那么继承顺序就会变为D->B->C->A
1.3 派生
子类也叫做派生类,在继承了父类的所有属性和方法后,也允许添加、修改或重新定义自己内部的属性和方法,如果新定义的属性或方法与继承来的父类中的属性和方法重名时,在调用时会优先调用自己内部的属性或方法,对父类中的代码不会有任何的影响。
1 class Dog: 2 def jump(self): 3 print("我是父类:我非常爱跳") 4 class Tidy(Dog): 5 pass 6 s_1 = Tidy() 7 s_1.jump() 8 运行结果: 9 我是父类:我非常爱跳
在这段代码中,创建了一个父类Dog,并定义了一个方法jump(),接下来创建了一个子类(派生类)来继承Dog类,子类内部没有写任何逻辑代码,通过实例s_1调用父类中的方法jump()。运行结果如上所示。
如果在子类中也定义了一个方法名是jump()的方法呢?调用时该运行哪一个?
1 class Dog: 2 def jump(self): 3 print("我是父类:非常爱跳") 4 class Tidy(Dog): 5 def jump(self): 6 print("我是子类:非常爱跳") 7 s_1 = Tidy() 8 s_1.jump() 9 运行结果: 10 我是子类:非常爱跳
实例s_1是类Tidy()的实例化对象,当调用类的属性或方法时,会优先在所属类的内部查找,如果找不到,才会去继承的父类中查找,运行结果如上所示。
内建的isinstance()函数和issubclass()函数的使用
isinstance(x, A_tuple):判断一个对象是否是某一个数据类型,返回一个布尔值。传入两个值,第一个值是需要判断的对象,第二个值是数据类型。如判断实例s_1是不是属于类Dog:isinstance(s_1,Dog)
issubclass(x, A_tuple):判断一个类是不是另一个类的子类,返回布尔值,传入两个值,第一个值子类的类名,第二个值是父类的类名。如判断Tidy是不是Dog的子类:issubclass(Tidy,Dog)
下面再来一个稍微复杂一点的。
1 class Foo: 2 def f1(self): 3 print("Foo.f1") 4 def f2(self): 5 print("Foo.f2") 6 self.f1() 7 class Bar(Foo): 8 def f1(self): 9 print("Bar.f1") 10 s_1 = Bar() 11 s_1.f2()
这段代码,运行结果是什么?为什么是这个结果?
1.4 组合
通过组合的方式,也可以避免代码的大量重复,组合指的就是,在一个类中,以另一个类作为它的数据属性。当类被定义后,
1 class Dog: #创建一个小狗的类 2 def jump(self): #定义一个jump()方法 3 print("小狗正在跳") 4 class Tidy: 5 def __init__(self,name): #构造函数 6 self.name = name 7 self.jump = Dog() #通过组合的方式,将Dog类赋值给self.jump属性 8 s_1 = Tidy("AA") 9 s_1.jump.jump() #调用Dog类中的jump()方法
这就是两个类之间的组合,可以通过将类赋值给其他类的一个数据属性,在调用的时候,s1_jump,实质上就是在调用Dog这个类,再通过.jump()方法,实质上也就是—》Dog.jump,这样就不难理解s_1.jump.jump()这条代码了。
组合和继承都能很好、有效的利用已定义好的资源,不用重复去写相同的代码,但是二者的使用场景也有一下不同。继承可以理解成包含的意思,当类之间有很多共同的属性时,就比较适合将这些共有的属性做成一个基类来继承。比如,人都有一个鼻子,两只眼睛..不同的是高矮胖瘦…..;而组合,可以理解为。
1 class School: 2 def __init__(self,name,addr): 3 self.name = name 4 self.addr = addr 5 class Course: 6 def __init__(self,name,period,school): 7 self.name = name 8 self.period = period 9 self.school = school 10 11 s_1 = School("一中","小石路") 12 s_2 = School("二中","中石路") 13 s_3 = School("三中","大石路") 14 15 msg=""" 16 1:一中 17 2:二中 18 3:三中 19 """ 20 21 while True: 22 print(msg) 23 menu = { 24 "1":s_1, 25 "2":s_2, 26 "3":s_3 27 } 28 29 choice = input("请输入你的选择:") 30 school_obj = menu[choice] 31 name = input("请输入课程名") 32 period = input("请输入学期") 33 new_course = Course(name,period,school_obj) 34 print("%s 属于%s"%(new_course.name,new_course.school.name))
1.5 接口继承
在子类中继承父类的方法
继承的最大作用在于可以减少代码的重复利用,子类继承过来父类定义的数据属性和方法后如何调用呢:
1 class Vehicle: 2 def __init__(self,name,type,speed,): 3 self.name = name 4 self.type = type 5 self.speed = speed 6 7 8 class Bus(Vehicle): 9 def __init__(self,name,type,speed,line): 10 Vehicle.__init__(self,name,type,speed) 11 self.line = line 12 def run(self): 13 print("%s路公交车马上就到了"%self.line) 14 s_1 = Bus("公家车","天然气","10km/h",1) 15 s_1.run() 16 运行结果: 17 1路公交车马上就到了!
这样的方法有如下两个缺点:第一:如果父类的名称发生了变化,子类的代码也要相应进行改变。第二:Python是允许多继承的语言,如上所示的方法在多继承中就要重复很多次调用父类的__init__()方法。为了解决这些问题,就引入了super()机制。
1 class Vehicle: 2 def __init__(self,name,type,speed,): 3 self.name = name 4 self.type = type 5 self.speed = speed 6 def run(self): 7 print("我是父类:开动了") 8 9 10 class Bus(Vehicle): 11 def __init__(self,name,type,speed,line): 12 # Vehicle.__init__(self,name,type,speed) 13 super(Bus,self).__init__(name,type,speed) 14 self.line = line 15 def run(self): 16 # Vehicle.run(self) 17 super().run() 18 print("%s路公交车马上就到了"%self.line) 19 s_1 = Bus("公家车","天然气","10km/h",1) 20 21 s_1.run()
从运行结果上来看,普通的这种继承方式和super继承是一样的,但其实两种方式的内部运行机制是不一样的。在super机制里可以保证公共父类仅被执行一次,至于执行的顺序,是按照mro进行的(类名.__mro__)。
两者在运行机制上有什么区别呢?
1 class A: 2 def __init__(self): 3 print("test A") 4 class B(A): 5 def __init__(self): 6 print("test B") 7 A.__init__(self) 8 class C(A): 9 def __init__(self): 10 print("test C") 11 A.__init__(self) 12 class D(C,B): 13 def __init__(self): 14 print("test D") 15 B.__init__(self) 16 C.__init__(self) 17 D() 18 运行结果: 19 test D 20 test B 21 test A 22 test C 23 test A
super
1 class A: 2 def __init__(self): 3 print("test A") 4 class B(A): 5 def __init__(self): 6 print("test B") 7 super(B,self).__init__() 8 class C(A): 9 def __init__(self): 10 print("test C") 11 super(C,self).__init__() 12 class D(C,B): 13 def __init__(self): 14 print("test D") 15 super(D,self).__init__() 16 D() 17 运行结果: 18 test D 19 test C 20 test B 21 test A
super(B,self).__init__()实质上就是调用了super类的初始化函数,产生一个super对象,仅仅是简单的记录了类的类型和具体的实例,super(类名, self).func的调用并不是用于调用当前类的父类的func函数;Python的多继承类是通过mro的方式来保证各个父类的函数被逐一调用,而且保证每个父类函数
只调用一次(如果每个类都使用super);混用super类和非绑定的函数是一个危险行为,这可能导致应该调用的父类函数没有调用或者一个父类函数被调用多次。