目前市面上各种中间件层出不穷,我们在做具体的选型时难免会纠结,在这里阐述点粗浅的看法,其实每个中间件在其设计上,都有其独有的特点或优化点,这些恰好应该是我们所关注的,这样才能做到物尽其用,将其特性发挥到最大;同时还要了解它们各自的劣势,这主要为了避坑。各种中间件就像是积木,我们能做的,就是选择合适形状的积木,搭出需要的房子。
不得不说Kafka这块积木,既能做消息中间件削峰解耦,又能做实时流处理,数据业务两手抓,真可谓上得厅堂,下得厨房。所以Kafka系列的第一篇,想先从它的应用场景分别出发,说说是哪些技术和原理支撑了它的技术特性。
Kafka核心思想概括
所有的消息以“有序日志“的方式存储,生产者将消息发布到末端(可理解为追加),消费者从某个逻辑位按序读取。
【场景一】消息中间件
在选择消息中间件时,我们的主要关注点有:性能、消息的可靠性,顺序性。
1.性能
关于Kafka的高性能,主要是因为它在实现上利用了操作系统一些底层的优化技术,尽管作为写业务代码的程序员,这些底层知识也是需要了解的。
【优化一】零拷贝
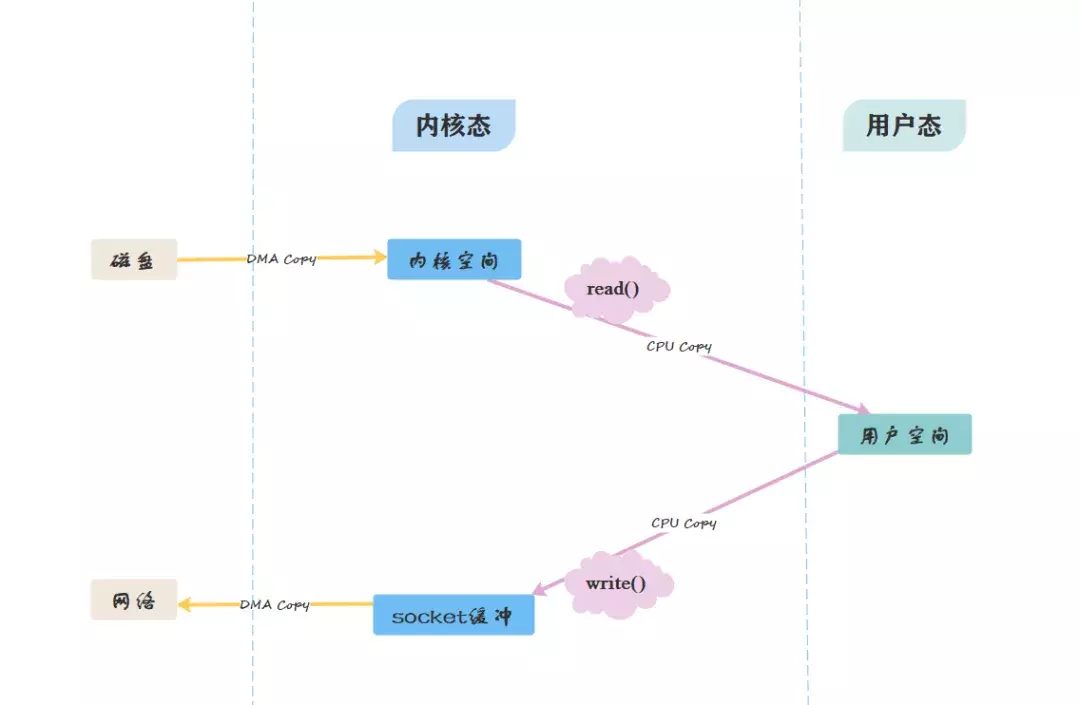
这是Kafka在消费者端的优化,我们通过两张图来比较一下传统方式与零拷贝方式的区别:
- 传统方式:
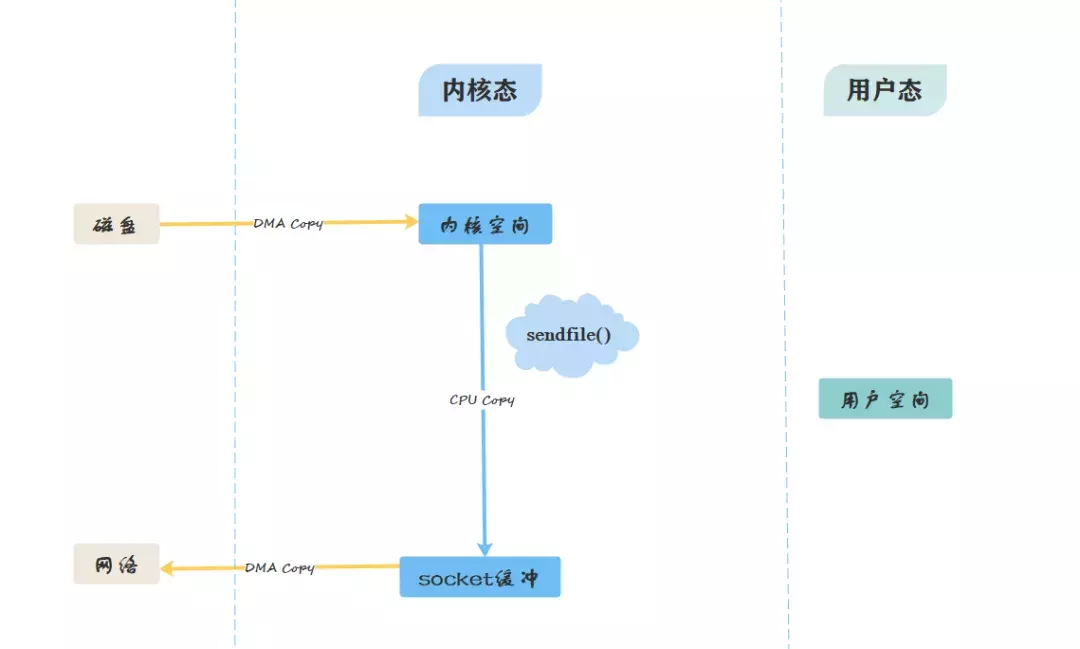
- 零拷贝方式:
- 终极目标:如何让数据不经过用户空间?
- 从图中可看出,零拷贝省略了拷贝到用户缓冲的步骤,通过文件描述符,直接从内核空间将数据复制到网卡接口。
【优化二】顺序写入磁盘
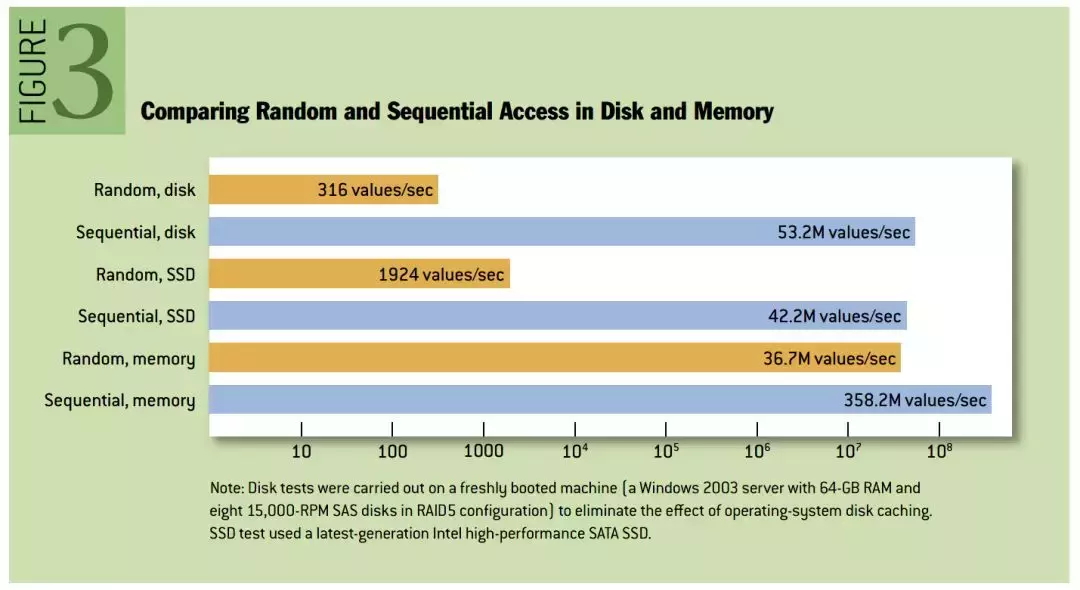
- 写入消息时,采用文件追加的方式,并且不允许修改已经写入的消息,于是写入磁盘的方式是顺序写入。我们通常认为的基于磁盘读写性能较差,指的是基于磁盘的随机读写;事实上,基于磁盘的顺序读写,性能接近于内存的随机读写,以下是性能对比图:
【优化三】内存映射
- 概括:用户空间的一段内存区域映射到内核空间,这样,无论是内核空间或用户空间对这段内存区域的修改,都可以直接映射到另一个区域。
- 优势:如果内核态和用户态存在大量的数据传输,效率是非常高的。
- 为什么会提高效率:概括来讲,传统方式为read()系统调用,进行了两次数据拷贝;内存映射方式为mmap()系统调用,只进行一次数据拷贝
【优化四】批量压缩
- 生产者:批量发送消息集
- 消费者:主动拉取数据,同样采用批量拉取的方式
2.可靠性
Kafka的副本机制是保证其可靠性的核心。
关于副本机制,我将它理解为Leader-Follower机制,就是多个服务器中有相同数据的多个副本,并且划分的粒度是分区。很明显,这样的策略就有下面几个问题必须解决:
- 各副本间如何同步?
- ISR机制:Leader动态维护一个ISR(In-Sync Replica)列表,
- Leader故障,如何选举新的Leader?
- 要想解决这个问题,就要引出Zookeeper,它是Kafka实现副本机制的前提,关于它的原理且听下回分解,本篇还是从Kafka角度进行分析。在这里我们只需要了解,一些关于Broker、Topics、Partitions的元信息存储在Zookeeper中,Leader发生故障时,从ISR集合中进行选举新的Leader。
request.required.acks来设置数据的可靠性:
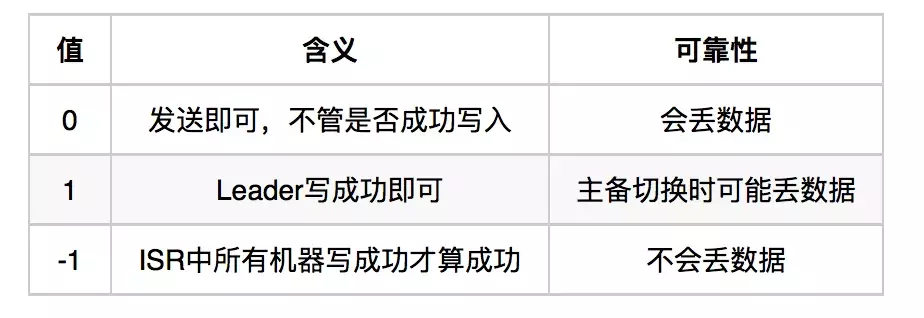
分区机制和副本机制知识点:
3.顺序性
顺序性保证主要依赖于分区机制 + 偏移量。
提到分区,首先就要解释一下相关的概念以及他们之间的关系,个人总结如下几点:
服务器(Broker):指一个独立的服务器
主题(Topic):消息的逻辑分类,可跨Broker
分区(Partition):消息的物理分类,基本的存储单元
这里盗一张图阐述上述概念间的关系
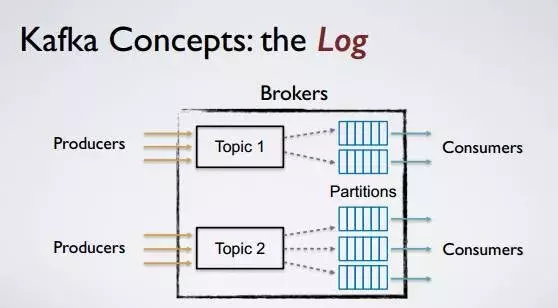
- 为什么分区机制可以保证消息的顺序性?
- Kafka可以保证一个分区内消息是有序且不可变的。
- 生产者:Kafka的消息是一个键值对,我们通过设置键值,指定消息被发送到特定主题的特定分区。
- 可以通过设置key,将同一类型的消息,发到同一个分区,就可以保证消息的有序性。
- 消费者:消费者需要通过保存偏移量,来记录自己消费到哪个位置,在0.10版本前,偏移量保存在zk中,后来保存在 __consumeroffsets topic中。
【场景二】流处理
在0.10版本后,Kafka内置了流处理框架API——Kafka Streams,一个基于Kafka的流式处理类库,它利用了上述,至此,Kafka也就随之发展成为一个囊括消息系统、存储系统、流处理系统的中央式的流处理平台。
与已有的Spark Streaming平台不同的是,Spark Streaming或Flink是一个是一个系统架构,而Kafka Streams属于一个库。Kafka Streams秉承简单的设计原则,优势体现在运维上。同时Kafka Streams保持了上面提到的所有特性。
关于二者适合的应用场景,已有大佬给出了结论,就不强行总结了。
- Kafka Streams:适合”Kafka --> Kafka“场景
- Spark Streaming:适合”Kafka --> 数据库”或“Kafka --> 数据科学模型“场景
参考
- 《Kafka权威指南》
- 《Kafka技术内幕》
- The Pathologies of Big Data
- Apache Kafka:大数据的实时处理时代