对于一个开发或运维人员而言, 当系统出现故障时, 第一步常常就是查看日志. 查看日志经常碰到的一个需求就是按关键字去搜索, 在日常开发机子上的 IDE 上, 都集成了强大的搜索功能, 但因为系统通常部署在 Linux 系统上, 一般只有命令行界面, 在其上应该怎么去搜索呢? 恐怕有些同学就不是那么清楚了.
有些人会用 ftp 之类的把日志下载下来本地再搜索, 如果是小一点的文件还好, 但日志文件往往都比较大, 因此这样的方式无疑是极为低效的.
下面就介绍一种相对快捷的方式, 也不需要用到特别高级的命令, 仅需要 tail 和 grep 两个命令结合起来即可, 能达到这样一个效果:
- 能按关键字搜索;
- 在显示关键字所在行时还能高亮关键字;
- 能把关键字所在行的上下文, 比如上下 10 行的内容也一起显示出来.
下面是一个效果示意图:
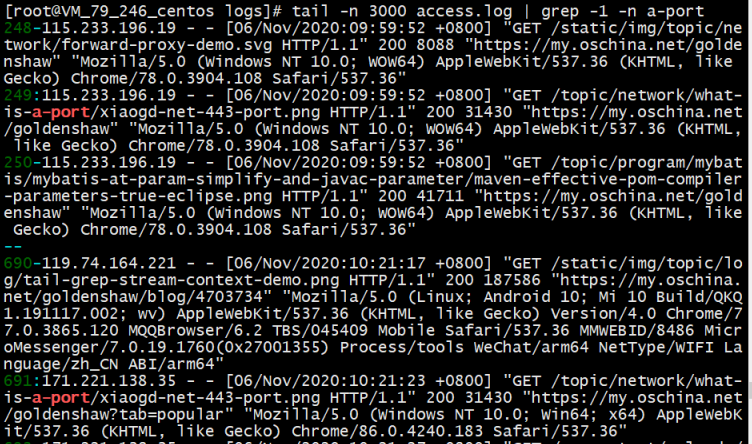
在这里, 我用我云主机的 nginx access log 做了个示范, 我搜索一篇文章 url 的关键字 "a-port", 然后显示出搜索的结果及上下文, 可以看到关键字被标红显示, 上下文也有显示, 多个搜索结果间以蓝色的短横间隔开来.
下面具体说说怎么实现这样的搜索, 先具体讲讲各个命令及参数, 再说说怎么结合起来, 最后还给出一个脚本化的高级用法.
tail 命令
首先是 tail 命令. 因为查看日志通常从后面最新的日志去看, tail 命令就是从后往前找.
比如下述命令会显示 access.log 的最后 10 行的内容:
tail access.log
tail 指定行数
默认情况下, tail 只会显示最后的 10 行, 对于一个日志很多的应用来说, 这可能是不够的, 为此我们需要搜索更多的行.
如果想实时查看日志, 可以参考之前的这篇文章使用 tail -f 实时观测服务器日志输出
tail 可以结合 -n 参数指定一个行数, 比如下述命令会显示最后的 30 行的日志:
tail -n 30 access.log
注: 如果不太能记住参数, 还可以使用
-n的完整命令参数--lines:tail --lines 30 access.log
grep 命令
tail 仅能打印显示日志, 很多时候这是不够的, 日志通常非常多, 而且很多是没有用, 我们还需要能过滤, 或者说搜索筛选日志的内容, 这时就可以使用 grep 命令.
grep 命令的基本用法是这样的. 假如你有一个文件 index.html, 你想在其中搜索一个关键词 official, 你可以这样用:
grep official index.html
结果如下:

它会把关键字所在行给你显示出来, 并高亮关键字.
关于高亮问题, 如果缺省没有高亮, 则可以自行加入
--color选项, 像这样:grep --color official index.html
注意, 通常不要直接用 grep 命令去搜索整个日志文件, 因为日志文件通常很大, 而且 grep 也是从开头开始搜索的, 因此可能搜索出一大堆你不感兴趣的历史记录.
后面将介绍如何结合 tail 和 grep 命令以缩小搜索范围.
带有空格的关键字
如果关键字有多个单词并带有空格, 可以使用 '' 单引号引起来, 例如:
grep 'english version' index.html
grep 显示上下文
有时, 我们不但要找出关键子所在行, 而且还想显示所在行上下的一些行.
这在查找异常信息时非常常见, 一方面异常栈会打印成非常多行, 另外我们通常需要前前后后都看一下到底发生了什么.
这时可以使用 grep 的 -NUM 参数来实现, 如下:
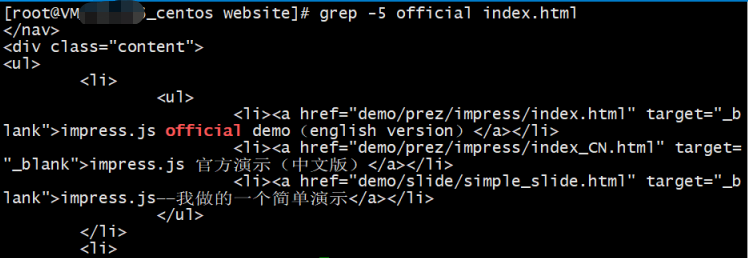
grep -5 official index.html
或者是使用 -C
grep -C 5 official index.html
它表示, 不但要找出 official 关键字所在行, 还要把所在行前后的 5 行都显示出来.
- 后接的数字 5 就表示前后 5 行, 如果是 -10 就表示前后 10 行
结果如下:
grep 显示行号
为了更清晰地呈现, 还可以选择显示行号, 用 -n 参数, 如下:
grep -5 -n official index.html
结果如下图:
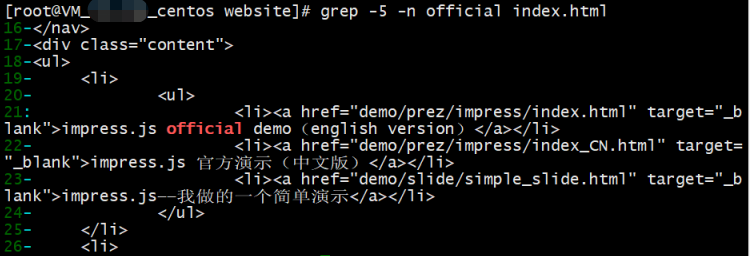
可以看到, official 关键字在 21 行, 行头的行号还特别以冒号":" 标出; 此外, 关键行的前 5 行(16~20)和后 5 行(22~26)也一并显示了出来.
如果我们是在跟踪一个异常, 这些上下文的信息可能会提供很多帮助.
管道符的使用
现在已经介绍完了 tail 和 grep 命令, 但还有一个问题, 如果直接在日志文件中去 grep 的话, 因为文件通常特别大, 而且很多历史数据可能不是我们想要的, 因此最好的方式是先用 tail 得到后面的那些行, 然后把 tail 出来的结果再交给 grep 命令去过滤, 而管道符可以实现这个目的, 管道符在命令行中就是一个"竖杠": |.
它可以把两个命令结合起来, 把请一个命令的输出当作后一个命令的输入.
用管道符 | 结合 tail 和 grep 命令
用管道符结合 tail 和 grep 命令可以这样去写:
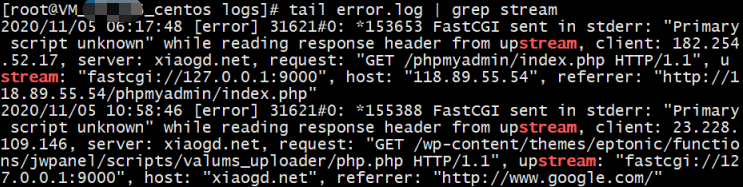
tail error.log | grep stream
注意: grep 之前的竖杠 |.
上述命令会把 tail 出来的最后 10 行的内容交给 grep 去搜索过滤, 并找出其中含有 stream 关键字的行, 结果如下:
结合前面所讲, 如果想在更大范围搜索并显示关键字的上下文, 最终可以这样去写:
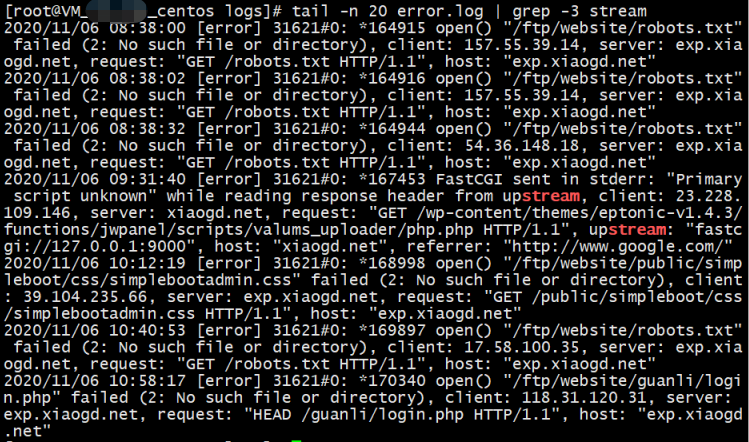
tail -n 20 error.log | grep -3 stream
以上命令在最后 20 行中去搜索 stream 关键字并显示关键字所在行及上下各 3 行的内容, 结果如下:
高级用法
有了以上命令, 要搜索异常信息就简单了不少, 而且更容易观察, 不过还是有一个问题, 就是整个命令还是太长了些, 如果想进一步简化, 则可以考虑将整个命令做成一个脚本, 并将部分参数值参数化, 这就带有一定的编程的味道了, 好在这对于我们程序员来说, 不算太难的事, 甚至是我们的日常, 下面说说怎么去实现.
先说下效果, 我们会编写一个脚本叫 search.sh
当然这个名字你可以自己去取
然后这样去用:
./search.sh stream 20 3
然后其效果就像执行下述命令一样:
tail -n 20 error.log | grep -3 stream
如果不打算传入行数及上下文的数目, 而使用脚本中定义的缺省值, 整个命令还可以简化成:
./search.sh stream
仅需要传入要搜索的关键字即可, 其它参数保持缺省.
自定义命令
就以搜索我本机上的 nginx 的 error.log 为例吧, 首先创建一个脚本文件 search.sh
touch search.sh
文件的内容如下:
#!/bin/bash
cd /usr/local/nginx/logs
tail -n 20 error.log | grep --color -3 stream
注意: 放入脚本文件时, 如果没有高亮, 需要自行加上
--color选项
逻辑也比较简单, 就是先进入 error.log 所在文件夹, 然后执行查找.
有了 cd 命令, 就可以直接把脚本放在远程登录后的用户目录下, 比如 /root 下, 这样进去了就可以直接执行, 连进入文件夹的动作也省略了.
另外, 如果不想用
cd命令, 也可以在 tail 中写上完整路径名.
当然, 现在脚本还是比较死的, 搜索的关键字被写死了. 不过目前来说, 我们先测试其它方面, 先把文件改成可执行的:
chmod 755 search.sh
然后可以先执行一遍看看是否 ok, 如果 ok 了, 再下一步准备把关键字参数化.
./search.sh
参数传递
现在需要把搜索的关键字给参数化, 不然执行脚本时, 始终只能搜索 'stream' 这个关键字, 这显然不是我们希望的.
如果是用我们熟悉的语言, 比如 java, javascript, 写一个可以接收参数的函数是很简单的, 其实对于 bash 这种脚本语言来说, 主要的问题是我们不熟悉其语法, 这个只要稍微查下它的手册或是在网上搜索下即不难知道.
过程就不提了, 具体而言是这样的:
#!/bin/bash
cd /usr/local/nginx/logs
tail -n 20 error.log | grep --color -3 $1
就是把 stream 这个写死的关键字变成一个变量 1,自然1,自然 符号就是 bash 跟定义变量有关的.
自然, 你应该能猜到, 如果想传递更多的参数, 就用 2,2,3, 以此类推.
然后你这样
./search.sh hello
那么脚本文件名后面跟的字符串'hello'就会传递给 $1 这个变量, 于是就相当于执行了:
tail -n 20 error.log | grep --color -3 hello
同理, 可以把 tail 的行数和 grep 的上下文的行数也参数化:
#!/bin/bash
cd /usr/local/nginx/logs
tail -n $2 error.log | grep --color -$3 $1
如此一来, 当执行下述命令时:
./search.sh hello 1000 10
就相当于:
tail -n 1000 error.log | grep --color -10 hello
也即在日志文件的最后 1000 行里搜索, 并显示关键行上下各 10 行的内容.
缺省值及判断逻辑
自然, 很多时候可能只想传递关键字即可, 当把 tail 的行数和 grep 的上下文的行数也参数化后, 每次调用也要传递它们是不方便的, 当如果把它们写死的话, 有时我们可能又需要适当变化, 这个矛盾怎么解决呢? 答案是利用缺省值和逻辑判断.
如果是常用的语言, 如 java, javascript, 写个这种判断相信对你来说是个再简单不过的事, 对于 bash 这种脚本语言, 最大的问题还是我们不熟悉其语法, 那么这个还是跟之前说的那样, 查查手册, 或搜索下, 过程就省略了, 具体来说, 可以这样:
#!/bin/bash
lineCount=1000
if [ $2 ]; then
lineCount=$2
fi
contextCount=10
if [ $3 ]; then
contextCount=$3
fi
cd /usr/local/nginx/logs
tail -n $lineCount error.log | grep --color -$contextCount $1
简单说就是定义两个变量lineCount和contextCount, 分别具有 1000 和 10 两个缺省值, 然后利用 if 判断用户是否输入了第二和第三个参数, 如果有, 就用它们的值取代缺省值, 没有的话就使用缺省值, 这样一来就比较灵活了.
如果只输入了关键字:
./search.sh hi
结果就是这样:
tail -n 1000 error.log | grep --color -10 hi
输入两个参数:
./search.sh hello 300
结果就是这样:
tail -n 300 error.log | grep --color -10 hello
输入三个参数:
./search.sh hey 500 8
结果就是这样:
tail -n 500 error.log | grep --color -8 hey
当然还是有个问题, 当你想只调整第三个参数时, 你还是必须得传入第二个参数, 否则传入的值只会被第二个参数优先获得.
命令输出
最后, 如果你想在执行前回显一下将要执行的命令, 还可以利用 echo 这个命令来实现, 它同样支持变量:
#!/bin/bash
lineCount=1000
if [ $2 ]; then
lineCount=$2
fi
contextCount=10
if [ $3 ]; then
contextCount=$3
fi
cd /usr/local/nginx/logs
echo "========= tail -n $lineCount error.log | grep --color -$contextCount $1"
tail -n $lineCount error.log | grep --color -$contextCount $1
这样一来, 执行前就会先打印出将要执行的命令.
总结
综上所述, 从单个命令到复合命令, 再到脚本化和参数化, 其实是用了编程中的抽象这一手法, 这是我们解决重复性以及解决复杂性的一种重要手段.
当一个命令或几个的复合命令比较繁琐时, 我们就用一个脚本文件去做抽象, 保留不变的东西, 把变化的东西参数化, 外部化, 通过这样的方式, 就简化了执行(调用)的过程, 减少了重复.
毕竟, 如果你经常需要查找日志的话, 输入简单的
./search.sh foo比反复输入如此之长的一串tail -n 1000 error.log | grep --color -10 foo要方便快捷的多.
作为一名程序员, 减少重复是我们的天职, 我们应该是怕重复, 怕麻烦的, 某种意义上, 我们应该是"懒惰"的:
还记得 Perl 语言的发明人 Larry Wall 的话吗: "优秀程序员应该有三大美德:懒惰、急躁和傲慢(laziness, impatience and hubris)"
更多关于抽象及重复的话题, 可以参考之前 计算机科学及重复性管理 专题, 关于使用 tail 结合 grep 查找日志关键字并高亮及显示所在行上下文就介绍到这里.