1. Stochastic Gradient Descent
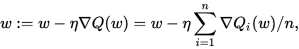
2. SGD With Momentum
Stochastic gradient descent with momentum remembers the update Δ w at each iteration, and determines the next update as a linear combination of the gradient and the previous update:
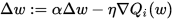
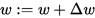

Unlike in classical stochastic gradient descent, it tends to keep traveling in the same direction, preventing oscillations.
3. RMSProp
RMSProp (for Root Mean Square Propagation) is also a method in which the learning rate is adapted for each of the parameters. The idea is to divide the learning rate for a weight by a running average of the magnitudes of recent gradients for that weight. So, first the running average is calculated in terms of means square,
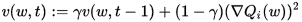
where, 
And the parameters are updated as,
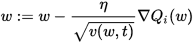
RMSProp has shown excellent adaptation of learning rate in different applications. RMSProp can be seen as a generalization of Rprop and is capable to work with mini-batches as well opposed to only full-batches.
4. The Adam Algorithm
Adam (short for Adaptive Moment Estimation) is an update to the RMSProp optimizer. In this optimization algorithm, running averages of both the gradients and the second moments of the gradients are used. Given parameters 




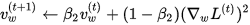
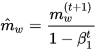
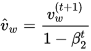

where 


参考链接:Wikipedia。