一、文件下载
文件下载需要以流的传输形式进行下载。
1、流程
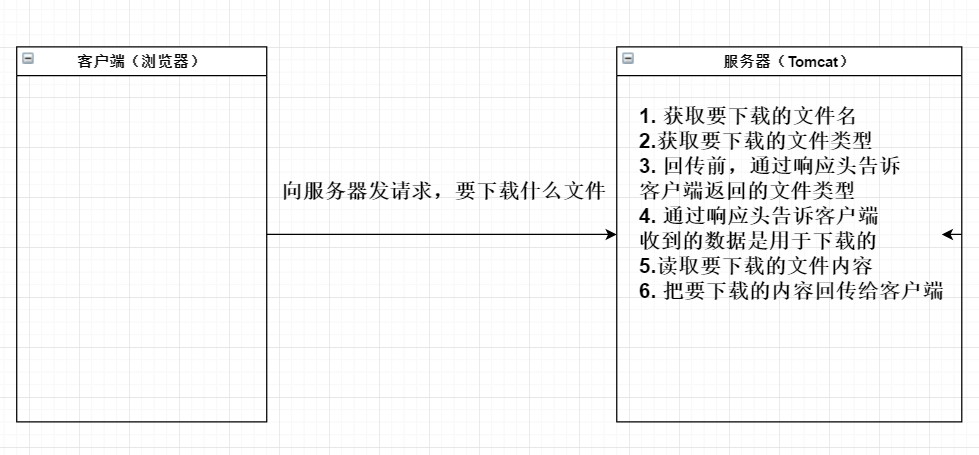
2、下载常用的API
response.getOutputStream(); 获取响应流
servletContext.getResourceAsStream(); 获取文件资源流
servletContext.getMimeType(); 获取文件类型
response.setContentType(); 设置响应类型
response.setHeader(); 设置响应头
注意:
需要设置响应头的值为
response.setHeader("Content-Disposition", "attachment; fileName=1.jpg" )
这个响应头告诉浏览器,这是需要下载的,而 attachment 表示附件,也就是下载的一个文件。fileName 表示下载的文件名;
其中 Content-Disposition 表示设置响应头,表示客户端收到数据怎么处理;
attachment 表示附件,意味着客户端收到数据是用于下载用的
fileName=文件名:fileName=后面是指定的下载的文件名
代码实现:
1 import org.apache.commons.io.IOUtils;
2
3 import javax.servlet.ServletContext;
4 import javax.servlet.ServletException;
5 import javax.servlet.http.HttpServlet;
6 import javax.servlet.http.HttpServletRequest;
7 import javax.servlet.http.HttpServletResponse;
8 import java.io.IOException;
9 import java.io.InputStream;
10 import java.io.OutputStream;
11
12
13 public class DownloadServlet extends HttpServlet {
14
15 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
16
17 //1. 获取要下载的文件名
18 String fileName = "a.jpg";
19
20 //2. 获取要下载的文件类型(使用 servletContext 对象读取)
21 ServletContext servletContext = getServletContext();
22 String mimeType = servletContext.getMimeType(fileName);
23 System.out.println("下载的文件类型:mimeType = " + mimeType);
24
25 //3. 通过响应头告诉客户端的文件类型
26 response.setContentType(mimeType);
27
28 //4. 通过响应头告诉客户端是用于下载的
29 //Content-Disposition 响应头,表示收到的数据怎么处理
30 //attachment 表示附件,表示下载使用
31 // fileName 表示指定下载的文件名
32 response.setHeader("Content-Disposition","attachment;filename=" + fileName);
33
34 //5. 读取要下载的文件内容
35 InputStream inputStream = servletContext.getResourceAsStream("/upload/" + fileName);
36
37 //6. 把要下载的内容回传给客户端
38 OutputStream outputStream = response.getOutputStream();
39 //使用工具类读取输入流中的数据,输出到输出流中,输出给客户端
40 IOUtils.copy(inputStream, outputStream);
41
42 }
43 }
通过上面的代码就可以实现文件下载了,但是只能下载英文的文件,并不支持中文,这是因为在响应头中,不能包含有中文字符,只能包含 ASCII码。
乱码现象:
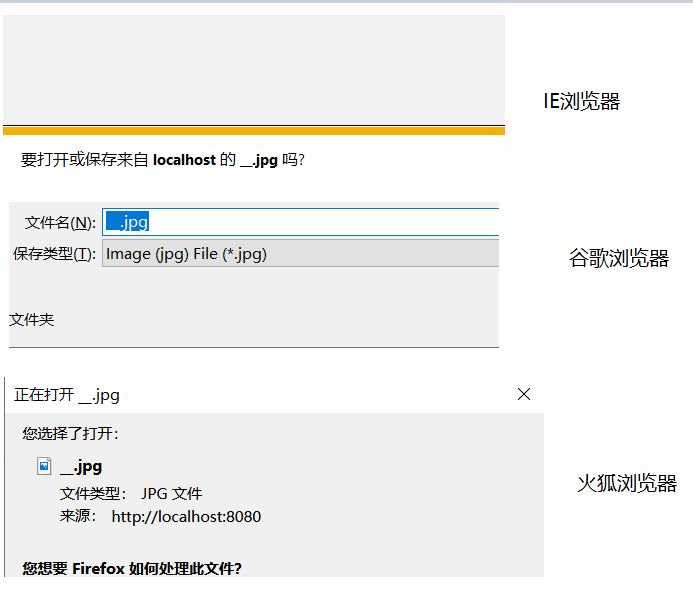
二、使用 URLEncoder 解决 IE和谷歌浏览器的附件的中文问题
如果客户端浏览器是 IE浏览器 或者是 谷歌浏览器,需要使用 URLEncoder 类先对中文进行 UTF 的编码操作。
因为 IE 浏览器和谷歌浏览器收到含有编码后的字符串会以 UTF-8 字符集进行解码显示。
URL编码就是把内容汉字转化为 %xx%xx 的格式(x代表十六进制的数)
示例:
1 // 把中文名进行 UTF-8 编码操作。
2 String str = "attachment; fileName=" + URLEncoder.encode("中文.jpg", "UTF-8");
3 // 然后把编码后的字符串设置到响应头中
4 response.setHeader("Content-Disposition", str)
注意: URLEncoder 是 java.net.URLEncoder 包中的类。
三、使用 Base64 编解码解决获取浏览器的附件的中文问题
如果客户端浏览器是火狐浏览器,那么就需要对中文名进行 BASE64 的编码。
同时还需要把请求头设置为如下格式:
请求头 Content-Disposition: attachment; filename=中文名
编码成为: Content-Disposition: attachment; filename==?charset?B?xxxxx?=
对上面 =?charset?B?xxxxx?= 进行说明:=? 表示编码内容的开始
charset 表示字符集
B 表示 Base64 编码
xxxxxx 表示文件名以 Base 编码后的内容
?= 表示编码内容的结束
BASE64 解编码的实例:
1 import sun.misc.BASE64Decoder;
2 import sun.misc.BASE64Encoder;
3
4 import java.io.IOException;
5
6 public class Base64Test {
7
8 public static void main(String[] args) throws IOException {
9 String content = "中国加油!!!";
10
11 //创建一个 BASE64 的编码器
12 BASE64Encoder base64Encoder = new BASE64Encoder();
13 // BASE64 的编码操作
14 String encode = base64Encoder.encode(content.getBytes("UTF-8"));
15 System.out.println("Base64编码后的结果:encode = " + encode);
16
17 //创建一个 BASE64 的编码器
18 BASE64Decoder base64Decoder = new BASE64Decoder();
19 //BASe64 的解码操作
20 byte[] bytes = base64Decoder.decodeBuffer(encode);
21 String content2 = new String(bytes);
22 System.out.println("Base64解码后的结果:content2 = " + content2);
23
24 }
25 }
运行结果:

因为火狐使用的是 BASE 的编解码方式还原响应中的汉字,使用 BASE64Encoder 类进行编码操作:
示例:
1 // 使用下面的格式进行 BASE64 编码
2 String str = "attachment; fileName=" + "=?utf-8?B?" + new BASE64Encoder().encode("中文.jpg".getBytes("utf-8")) + "?=";
3 // 设置到响应头中
4 response.setHeader("Content-Disposition", str);
四、使用请求头 User-Agent 完美解决中文乱码问题
为了解决上面两种不同编解码方式,只需要通过判断请求头中 User-Agent 这个请求头携带过来的浏览器信息即可判断是什么浏览器,然后做出不同的响应。
代码示例:
1 import org.apache.commons.io.IOUtils;
2 import sun.misc.BASE64Encoder;
3
4 import javax.servlet.ServletContext;
5 import javax.servlet.ServletException;
6 import javax.servlet.http.HttpServlet;
7 import javax.servlet.http.HttpServletRequest;
8 import javax.servlet.http.HttpServletResponse;
9 import java.io.IOException;
10 import java.io.InputStream;
11 import java.io.OutputStream;
12 import java.net.URLEncoder;
13
14
15 public class DownloadServlet extends HttpServlet {
16
17 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
18
19 //1. 获取要下载的文件名
20 String fileName = "中国.jpg";
21
22 //2. 获取要下载的文件类型(使用 servletContext 对象读取)
23 ServletContext servletContext = getServletContext();
24 String mimeType = servletContext.getMimeType(fileName);
25 System.out.println("下载的文件类型:mimeType = " + mimeType);
26
27 //3. 通过响应头告诉客户端的文件类型
28 response.setContentType(mimeType);
29
30 //4. 通过响应头告诉客户端是用于下载的
31 //Content-Disposition 响应头,表示收到的数据怎么处理
32 //attachment 表示附件,表示下载使用
33 // fileName 表示指定下载的文件名
34 //response.setHeader("Content-Disposition","attachment;filename=" + fileName);
35 //获取请求头进行判断
36 String header = request.getHeader("User-Agent");
37 //判断是否是火狐浏览器
38 if (header.contains("Firefox")) {
39
40 // 使用下面的格式进行 BASE64 编码后
41 String str = "attachment; fileName=" + "=?utf-8?B?" + new BASE64Encoder().encode("中文.jpg".getBytes("utf-8")) + "?=";
42 // 设置到响应头中
43 response.setHeader("Content-Disposition", str);
44 } else {
45
46 // 把中文名进行 UTF-8 编码操作。
47 String str = "attachment; fileName=" + URLEncoder.encode("中文.jpg", "UTF-8");
48 // 然后把编码后的字符串设置到响应头中
49 response.setHeader("Content-Disposition", str);
50 }
51
52
53 //5. 读取要下载的文件内容
54 InputStream inputStream = servletContext.getResourceAsStream("/upload/" + fileName);
55
56 //6. 把要下载的内容回传给客户端
57 OutputStream outputStream = response.getOutputStream();
58 //使用工具类读取输入流中的数据,输出到输出流中,输出给客户端
59 IOUtils.copy(inputStream, outputStream);
60
61 }
62 }