Redis的主从复制模式下, 一旦主节点由于故障不能提供服务, 需要人工将从节点晋升为主节点, 同时还要通知应用方更新主节点地址, 对于很多应用场景这种故障处理的方式是无法接受的。 可喜的是Redis从2.8开始正式
提供了Redis Sentinel(哨兵) 架构来解决这个问题。
总结:
Redis主从复制的缺点:没有办法对master进行动态选举,需要使用Sentinel机制完成动态选举
1. 哨兵模式介绍
-
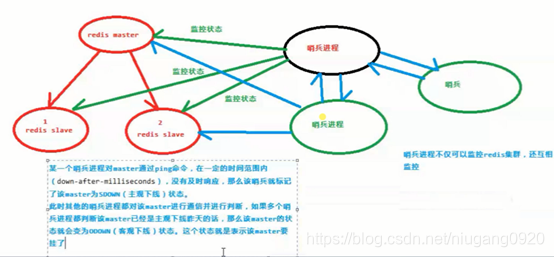
Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态
-
在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用(HA)
-
其已经被集成在redis2.6+的版本中,Redis的哨兵模式到了2.8版本之后就稳定了下来。
2.哨兵进程的作用
-
监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
-
提醒(Notification):当被监控的某个Redis节点出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作。
-
它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master;
-
当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用现在的Master替换失效Master。
-
Master和Slave服务器切换后,Master的redis.conf、Slave的redis.conf和sentinel.conf的配置文件的内容都会发生相应的改变,即,Master主服务器的redis.conf配置文件中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
3.哨兵进程的工作方式
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值,则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)。
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有
Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。 - 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
- 在一般情况下, 每个Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
4.安装和部署
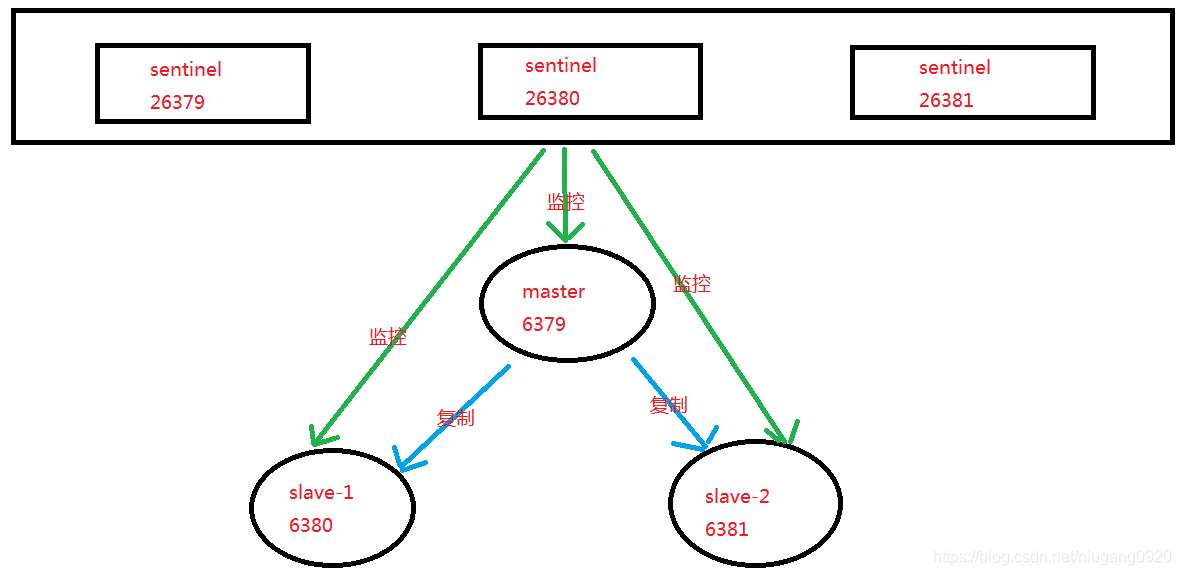
4.1部署拓扑结构
4.2启动主节点
配置
redis-6379.conf主要修改参数
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
启动
./redis-server redis-6379.conf
确认是否启动成功
方式1:
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379 ping
PONG
方式2:
[root@localhost bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(empty list or set)
4.2启动从节点
配置
从节点1 redis-6380.conf 主要修改参数
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 127.0.0.1 6379
从节点2 redis-6381.conf 主要修改参数
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 127.0.0.1 6379
启动
./redis-server redis-6380.conf
启动打印日志:
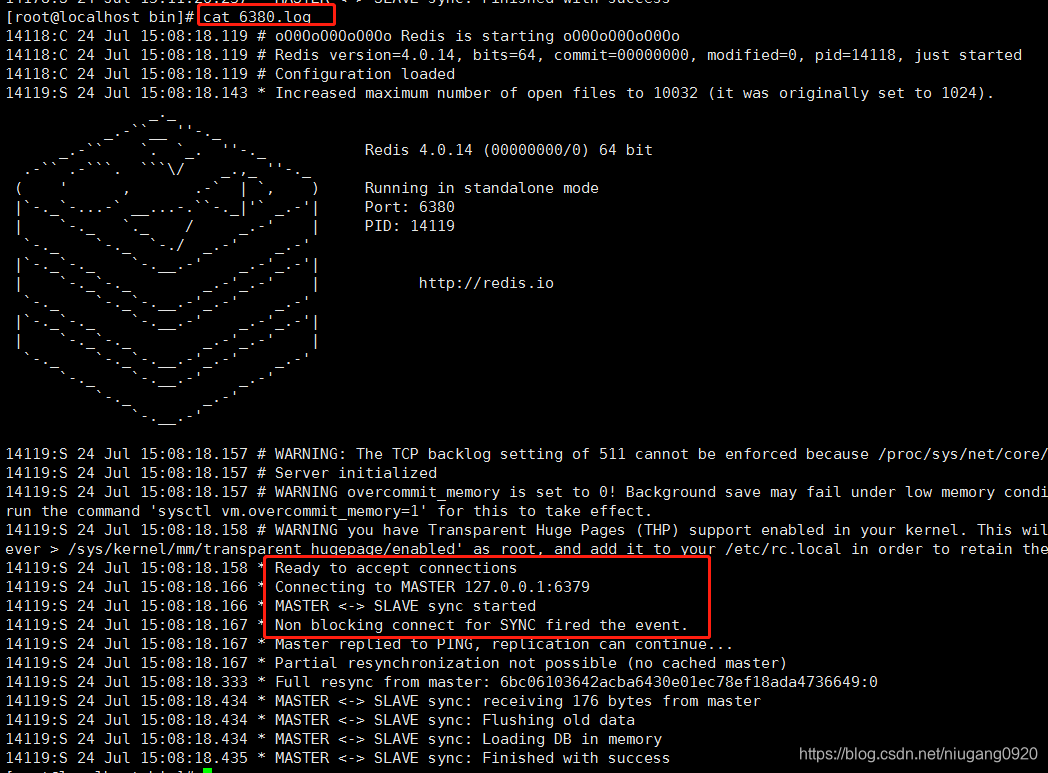
./redis-server redis-6381.conf
启动打印日志:
确认主从关系
[root@localhost bin]# ./redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master ##当前节点角色
connected_slaves:2 ##从节点连接个数
slave0:ip=127.0.0.1,port=6380,state=online,offset=392,lag=1 ##从节点连接信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=392,lag=2 ##从节点连接信息
master_replid:6bc06103642acba6430e01ec78ef18ada4736649
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:392
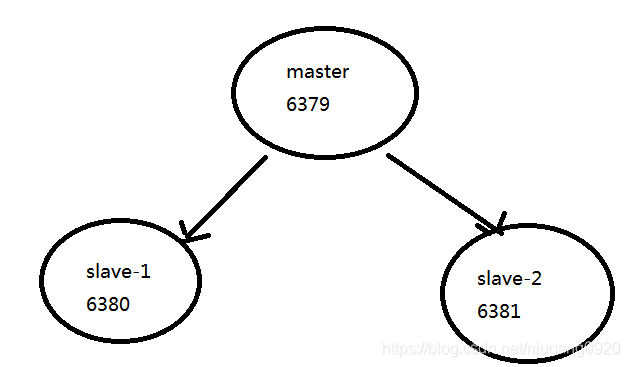
此时拓扑:
4.3部署Sentinel节点
3个Sentinel节点的部署方法是完全一致的(端口不同)
配置
主要修改参数 修改端口 ,修改主节点连接信息,其他使用默认就行了,具体参数后面会介绍
port 26379
sentinel monitor mymaster 127.0.0.1 6379 1
Sentinel节点的默认端口是26379
启动
./redis-sentinel sentinel-26379.conf
方法二, 使用redis-server命令加--sentinel参数:
redis-server sentinel-26379.conf --sentinel
日志
确认
Sentinel节点本质上是一个特殊的Redis节点, 所以也可以通过info命令 来查询它的相关信息 。
[root@localhost bin]# redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=1
其他两个配置是一样的。
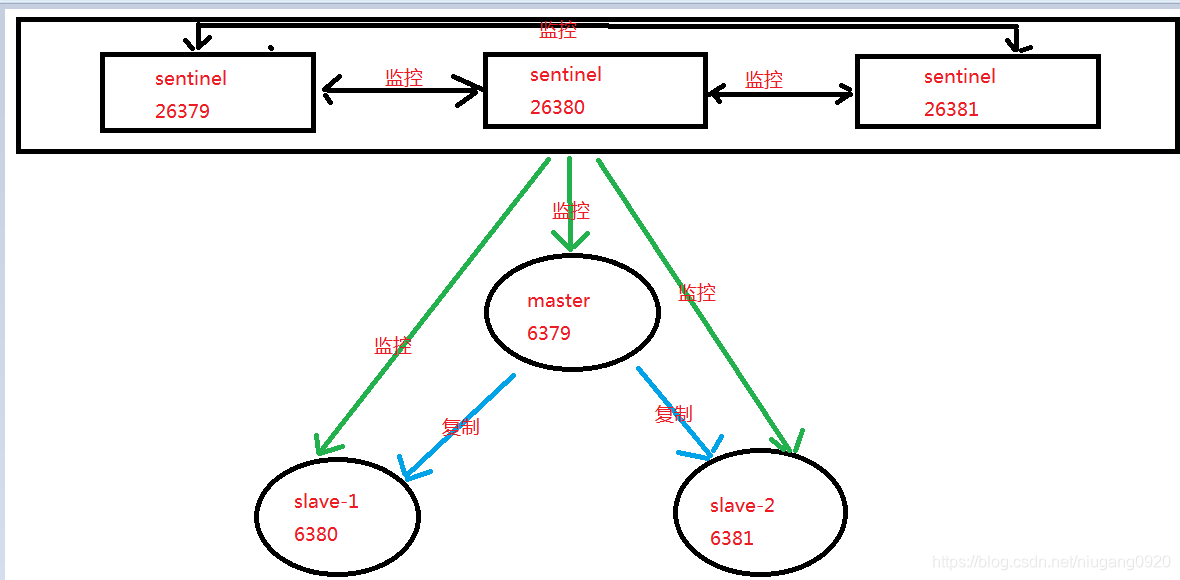
最终拓扑
4.4宕机测试
现在在master节点上执行,如下操作,演示通过redis sentinel 进行故障转移和新master的选出
[root@localhost bin]# ./redis-cli shutdown
执行完上述操作后,三个哨兵打印的日志如下:
14549:X 24 Jul 15:44:44.568 # +vote-for-leader e31085285266ff86372eeeb4970c9a8de0471025 1
14549:X 24 Jul 15:44:44.604 # +sdown master mymaster 127.0.0.1 6379
14549:X 24 Jul 15:44:44.604 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
14549:X 24 Jul 15:44:44.604 # Next failover delay: I will not start a failover before Wed Jul 24 15:50:45 2019
14549:X 24 Jul 15:44:45.093 # +config-update-from sentinel e31085285266ff86372eeeb4970c9a8de0471025 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
14549:X 24 Jul 15:44:45.093 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
14549:X 24 Jul 15:44:45.093 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
14549:X 24 Jul 15:44:45.093 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
14549:X 24 Jul 15:45:15.127 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
意思就是选择6381为新的master
如下日志是在,6379执行shutdown前后在6381节点上执行的操作:
127.0.0.1:6381> info replication
# Replication
role:slave ###6379节点正常是,6381为从节点
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:166451
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6bc06103642acba6430e01ec78ef18ada4736649
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:166451
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:253
repl_backlog_histlen:166199
127.0.0.1:6381> info replication
# Replication
role:master ###执行shutdwon后成为新的master节点
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=217098,lag=1
master_replid:e39de2323e3ab0ff0eff1347ad1c65e2bd3fd917
master_replid2:6bc06103642acba6430e01ec78ef18ada4736649
master_repl_offset:217098
second_repl_offset:172878
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:253
repl_backlog_histlen:216846
5.Sentinel配置说明
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
一个是事件的类型,
一个是事件的描述。
如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
微信公众号
