简介
hadoop解决问题:
海量数据的存储(HDFS)
海量数据的分析(MapReduce)
资源管理调度(YARN)
受Google三篇论文启发:GFS、MapReduce、BigTable
Hadoop功能:
擅长海量离线日志分析
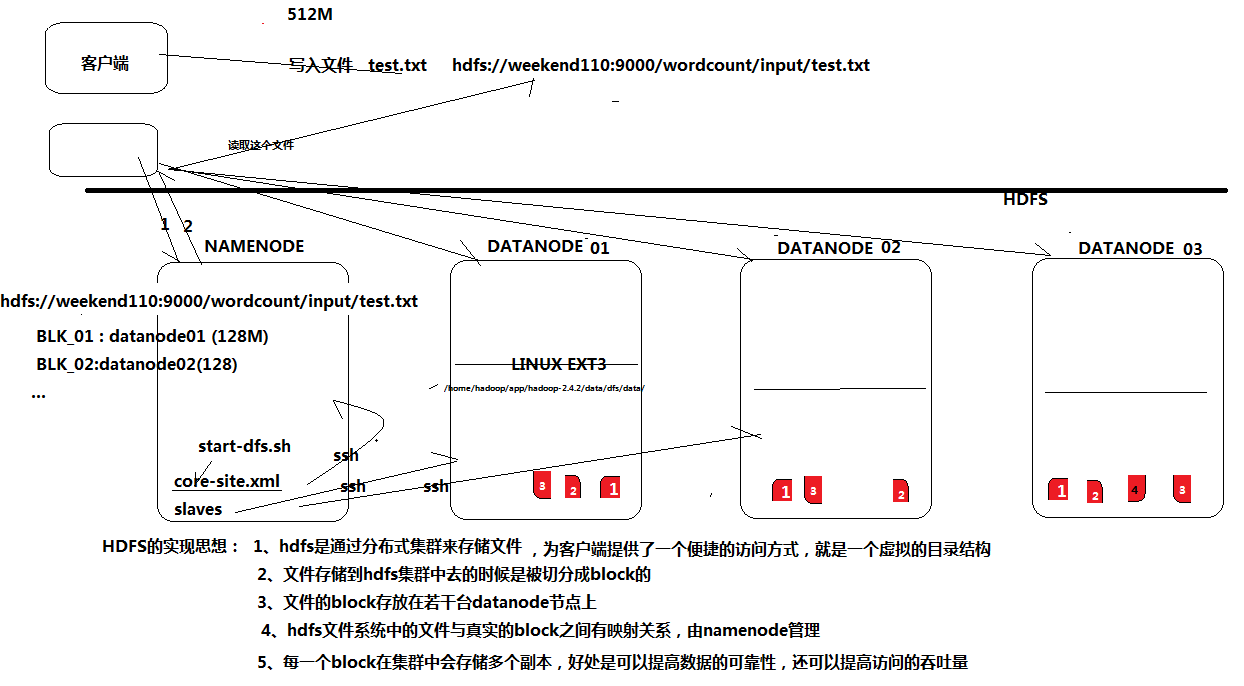
Hadoop如何解决海量数据的存储?
若干被称为Datanodes的节点,存储文件时,将文件切割成很多块,每块分散分布到其他机器上,负债分散均衡,并且每块都会有副本分散保存来防止数据丢失。文件路径映射关系管理就是Namenode负责的。
hadoop解决问题:
海量数据的存储(HDFS)
海量数据的分析(MapReduce)
资源管理调度(YARN)
Hadoop如何解决海量数据的存储?
若干被称为Datanodes的节点,存储文件时,将文件切割成很多块,每块分散分布到其他机器上,负债分散衡,并且每块都会有副本分散保存来防止数据丢失。文件路径映射关系管理就是Namenode负责的。
NAT模式讲解:
VMware产生一个虚拟网关,centos虚拟机里面也有网卡,而这个网卡就连接在虚拟网关上。Windows主机上有一个真实的物理网卡,Windows网卡会连接到宿舍的网关上。
VMware会给Windows生成一个虚拟网卡,名叫VMnet8。centos和vmnet8就是通过虚拟网关连接在一起的,所以他们必须处在同意网段。
实际物理网卡和vmnet8是没什么关系,不考虑他们的ip网段。
安装流程
网络配置
vmare中的网络适配器选择:自定义->VMnet8(NAT模式)
vmware中的虚拟网络编辑器->VMnet8,然后设置网络和默认网关。
修改静态IP
方法一:图形界面
进入Linux图形界面->右键点击右上方的两个小电脑->点击edit connections->选中当前网络,再添加相关网络信即可
方法二:网卡配置文件
在一张图中IPADDR=中 等于号前和后加入了空格,是错误的,很难发现的。
输入命令:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
IPADDR="192.168.80.31"
NETMASK="255.255.255.0"
GATEWAY="192.168.80.1"
改完配置文件不会自动生效,必须重启Linux服务器(reboot)
或者重启network服务sudo service netwok restart
注意:也可以不要引号,建议不要用引号
DEVICE=eth0
BOOTPROTO=static
IPV6INIT=yes
NM_CONTROLLED=yes
ONBOOT=yes
TYPE="Ethernet
IPADDR=192.168.80.31
NETMASK=255.255.255.0
GATEWAY=192.168.80.1
修改主机名:
也就是修改Linux命令终端中括号里的@后的名字
进入root用户下,输入:vi /etc/sysconfig/network
在里面的HOSTNAME=slave1的等号=后添加想修改的名字保存就行。
然后再重启主机或者输入:sudo hostname slave1
然后重新登陆系统就行。
修改主机和IP的映射关系:
真实集群里面每台主机都必须有一个规划好的名字或者编号,
vi /etc/hosts
192.168.80.31 name
sudo vi /etc/sysconfig/network
防火墙
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭防火墙开机启动
chkconfig iptables off
远程登陆
jdk版本必须和centos是一样的64位版本
通过secureCRT来将文件传送到centos里面,再进行安装
进入secureFX输入用户名、密码、端口22就行了
拖动文件即可进行文件传输
注意要提前关闭防火墙
关掉图形界面,终端输入命令:init 3
切换用户:su
命令行进入配置文件,关掉图形界面或者选择用户模式。vi /etc/inittab
或者:
sudo vi /etc/inittab
在最后一行中将启动级别改成3
id:3:initdefault
权限修改
让普通用户具备sudo执行权限:
切换到root用户下
然后:vi /etc/sudoers
加入一行:
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
这样就给hadoop用户和root一样的权限了
如果遇到警告:输入wq!即可
jdk安装
创建文件夹
在Hadoop用户主目录下建一个文件夹,专门用来放置Hadoop安装的软件
mkdir /home/hadoop/app
解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
或者tar -zxvf jdk-7u55-linux-i586.tar.gz -C app/
#安装完成后输入:java -version
如果出现3行具体Java版本等信息则说明安装成功,此时必须将Java的路径添加到环境变量里面。
注意-C是大写的字母
添加环境变量
vi /etc/profile或者sudo vi /etc/profile
在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
刷新配置
source /etc/profile
确保java环境安装好
[root@weekend110-1 hadoop-2.4.1]# echo ${JAVA_HOME}
/home/hadoop/app/jdk1.7.0_65
[root@weekend110-1 hadoop-2.4.1]# java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (rhel-2.4.3.3.el6-x86_64 u45-b15)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)
安装hadoop
bin:可执行脚本,普通操作
etc:配置文件
include:本地库文件
lib:本地库
libexec:
sbin:系统相关的执行脚本,启动和停止的
share:架包
配置hadoop文件
第一个:配置文件hadoop-env.sh
配置文件位置:/home/hadoop/app/hadoop-2.6.5/etc/hadoop
命令:vi hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_181
说明:=后面的是jdk所在地址
保存离开::wq
第二个:配置文件core-site.xml
配置文件位置:/home/hadoop/app/hadoop-2.6.5/etc/hadoop
#命令:vi core-site.xml
显示:
<configuration>
</configuration>
在这里面插入代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave2:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
value>/home/hadoop/app/hadoop-2.4.1/data/</value>
</property>
</configuration>
说明:
一个配置项放置
slave2是localhost,即主节点的主机名
hadoop.tmp.dir就是datanode的工作目录文件,是一个临时存储数据的
里面的fs.defaultFS表示:默认的文件系统
hdfs://slave2:9000表示:hdfs表示协议,//后面的表示主节点的地址,并指定端口号9000。
/home/hadoop/app/hadoop-2.6.5为hadoop的工作目录,data/是建的一个文件夹用来放数据
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master : 9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.6.5/data/</value>
</property>
</configuration>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
第四个:mapred-site.xml
先修改名称:mv mapred-site.xml.template mapred-site.xml
然后继续下面:
vi mapred-site.xml
添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<!--指定YARN的老大(resourcemanager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend110</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置环境变量:
输入:sudo vi /etc/profile
在文件
unset i
unset -f pathmunge
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
修改为:
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效:
sudo source /etc/profile
hadoop用户权限修改
进入root用户,执行:visudo
打开文件找到:root ALL=(ALL) ALL,紧贴下面添加:hadoop ALL=(ALL) ALL,保持退出。
如果需要执行时不输入密码,
找到:#%wheel ALL = (ALL) NOPASSWD:ALL,
去掉前面的#号,保持退出
格式化namenode
输入命令:
hdfs namenode -format
执行成功后输入:
start-dfs.sh
查看当前运行进程
执行:jps
一个NameNode,一个jps,一个SecondaryNameNode,若干DataNode
出现这三个表示连接成功了。
浏览器网页登陆
首先修改hosts,将ip和名字添加进hosts。hosts地址:C:WindowsSystem32driversetchosts
然后在浏览器输入:http://name:50070。其中,50070是端口号。
HDFS原理解析
常用命令
hadoop fs用来查看命令
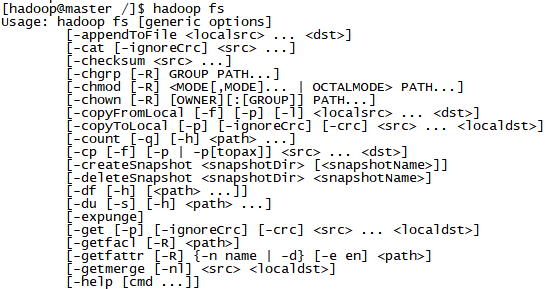
其中:
appedTofile:追加文件
localsrc:本地路径
dst:目标路径
chown:改变所属用户
chmod:修改用户权限
-du(s)//显示目录中所有文件大小
-count[-q]//显示目录中文件数量
-put//本地文件复制到hdfs-copyFromLocal //同put
-moveFromLocal//从本地文件移动到hdfs
-get [-ignoreCrc]//复制文件到本地,可以忽略crc校验
-getmerge//将源目录中的所有文件排序合并到一个文件中
-cat//在终端显示文件内容
-text//在终端显示文件内容
-copyToLocal [-ignoreCrc]//复制到本地
-moveToLocal
-touchz//创建一个空文件
免密ssh登陆
secure shell的缩写为ssh,远程登陆的协议。
登陆方法:ssh ip地址
断开连接:logout
配置ssh免登陆
生成ssh免登陆密钥
进入我的home目录
cd ~/.shh
ssh-keygen -t rsa
执行完这个命令后,会生成两个文件:id_rsa(私钥)、id_rsa.pub(公钥)
ssh-copy-id localhost