前言
在读写分离的情况下,缓存和数据库数据不一致怎么解决? 请看这一篇如何更新缓存保证缓存和数据库双写一致性?
如何解决DB数据库的数据不一致问题? 请看这一篇怎么解决DB读写分离,导致数据不一致问题?
在缓存和数据库数据一致性问题中,推荐 先更新数据库,再删除缓存。如果缓存删除失败可以用MQ消息队列的方式进行重试删除。
为什么会导致不一致
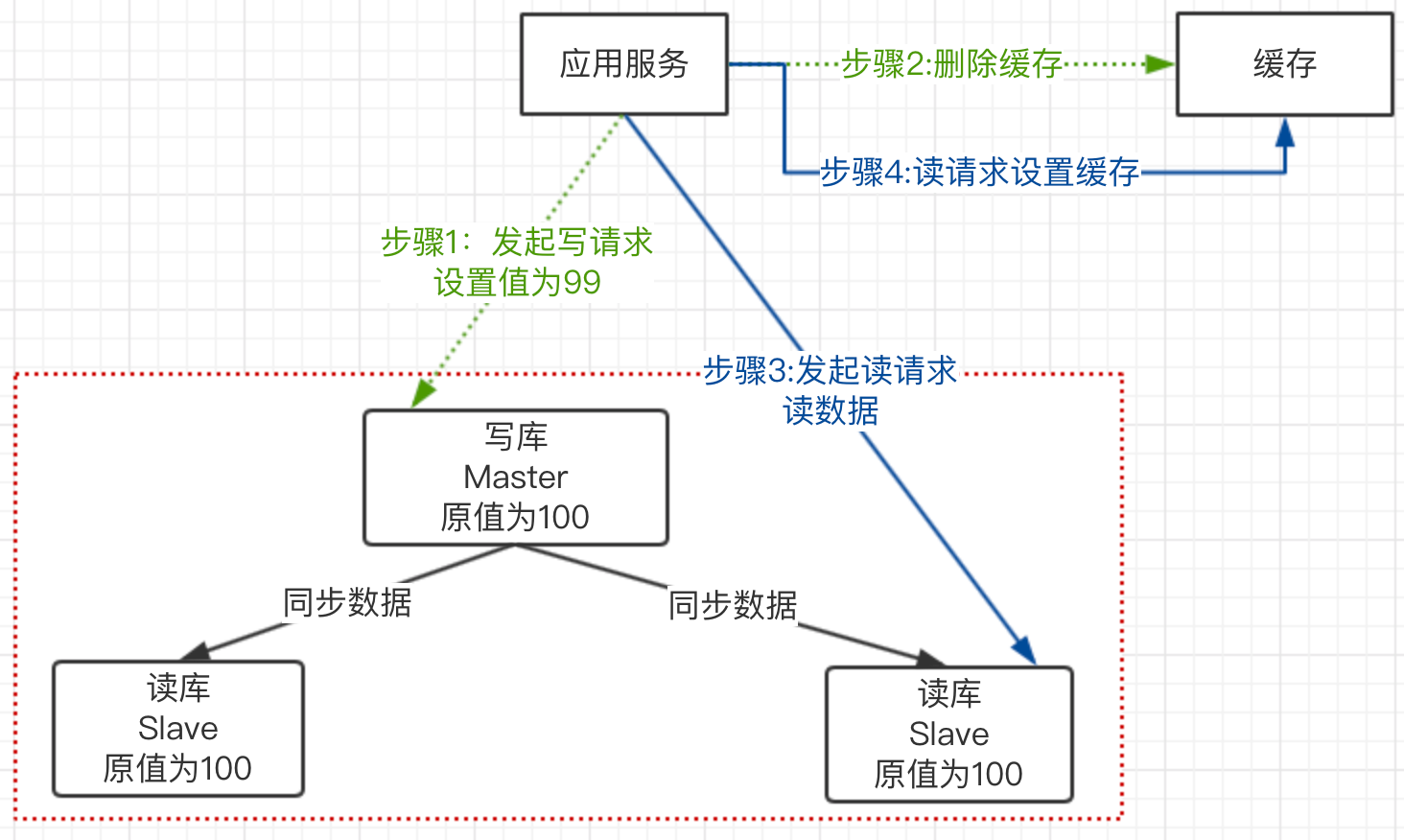
上图流程:
1)应用服务(商品服务)请求A更新库存为99,原值为100
2)但主库同步到从库需要时间,还没有同步完成时,请求B发起读请求
3)读请求B走的是从库,取出来从库里面的旧值100
4)读请求B会把取出来的值,再设置到缓存中,值为100
5)但当从库同步数据完成,从库的数据值为99,这就导致数据库和缓存数据不一致
方案一:后台缓存标记法
怎么解决DB读写分离,导致数据不一致问题?里面提到此方案,这边就不重复介绍了,大家可以去那篇文章中查看。
数据不一致问题是因为读请求走的是从库,把从库的旧值又设置到缓存中了。后台缓存标记方案就解决了此问题,在主从数据库同步窗口时间内,读请求也是走主库。这样就解决了读请求取到的是旧值这个问题。
但这个方案也有缺点,就是有系统性能问题,降低了吞吐量
方案二:延迟消息
其实在真实业务中,尤其互联网项目中,数据短时间的不一致时能够接受的。就像怎么解决DB读写分离,导致数据不一致问题?中提到的本地缓存标记法,保证了本用户数据一致,其他用户可暂时不一致,但最终是一致的这个思路。我们可以设置一个延迟消息,如下图
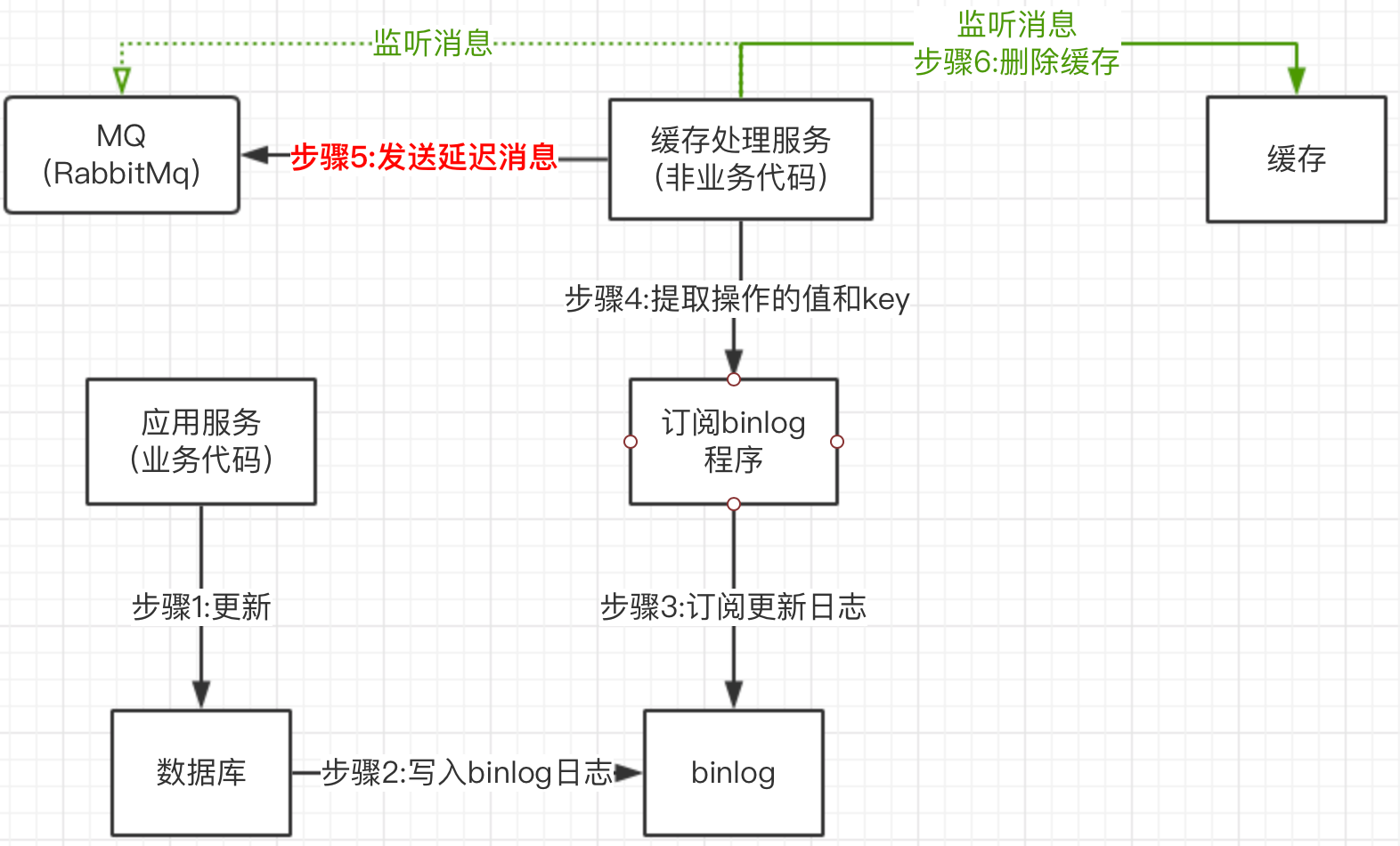
流程:
1)在订阅到binlog更新日志时,先不删除缓存,而是投递一个延迟消息(如:延迟10秒的消息,就是过10秒此消息才会被消费者监听到,从而被消费)
2)延迟消息的延迟时间,设置为主库与从库的数据同步延迟的时间,可自行预估
3)监听到延迟消息,在删除缓存。
这个方案的特点就是读请求会在延迟时间内读取到的是旧值,等到延迟时间一过,取到的就是新值。这个业务在互联网产品中是允许的。
如果要保证本用户(更新数据的用户)一定读到的是新值,这边可以采用本地缓存标记方案,直接从主数据库读取,读取到数据后,可以把新值设置到缓存中,这样就保证了数据一致性。
方案三:更新用户再次发起读请求
在方案二中,其他用户的读请求会有暂时间读取到的是旧值,如何缩短时间?其实是有一个方案,就是让更新用户再次发起读请求,也就是在方案二最后提到的
1)更新用户再次发起读请求,根据本地缓存标记,直接走主数据库,读取的肯定是新值,
2)再把这个新值设置到缓存中。这样就保证了缓存中的是新值,虽然从库还没有不同完成,但缓存中已经是新值了。
3)最后从库同步数据完成,值就达到了一致性
此方案的问题:就是更新操作后,多了一步读请求。
总结:小伙伴可以根据自己的业务需求,选择不同的方案,一定要结合自己的业务,没有什么完美的方案,只是如何取舍而已。