本篇为《python数据分析与数据化运营》一书的笔记。
1、会员价值度模型——RFM
RFM模型时根据会员最近一次购买时间R,购买频率F,购买金额M,计算得出RFM得分,通过三个维度来评估客户的订单活跃价值。RFM模型基于一个固定的时间点来做模型分析,因此,今天做的RFM得分跟7天前做的结果可能不一样。
- R:最后一笔订单距离现在的时间差,可以用于 R 的定义。需要强调的是结合客户购买周期来定义 R 的分组问题,例如电视机的购买周期较长(如 300天),分组区间最好大于购买周期,否则客户价值无法体现;
- F:定义时间内,购买数量的多少。需要注意的是这里的数量,不一定是总数,也可以是最小值(价值低的客户)、最大值、中位数(或平均数)、方差等指标,什么指标不重要,重要的是用什么指标反映什么目的。
- M:定义时内,购买金额的多少。指标同 F
RFM 无法解决的问题:RFM 并不是一个统计模型, 更像一个统计描述,故无法预测目标市场中新用户的行为特征——购买动机、用户购买或流失概率、模拟市场占有率。
步骤:(1)设置截止时间节点
(2)得到会员id,订单数据、订单金额的原始数据
(3)从订单时间中找到各会员距离截止时间最近的订单时间;以会员id为维度,统计购买频率,购买金额
(4)R、F、M做数据分区。对于F、M,值越大,标志购买频率越高,购买金额越大;对R,值越小表示距离时间节点越近。
(5)将三个值组合或相加在一起得到总的RFM得分。
#导入库 import pandas as pd import numpy as np #读入数据 data=pd.read_csv(r'E:data analysis estsales.csv') print(data.head()) print(data['AMOUNTINFO'].describe()) #查看描述性统计信息 print(data[data.isnull().any(1)])#查看缺失值 #缺失值占比小,直接去掉 sales_data=data.dropna() #将日期的str类型,变为时间类型 print(sales_data[sales_data.isnull().any(1)]) sales_data['ORDERDATE']=pd.to_datetime(sales_data['ORDERDATE'],format='%Y-%m-%d') print(sales_data.dtypes) #查看数据类型
#计算r、f、m数值 r=sales_data['ORDERDATE'].groupby(sales_data['USERID']).max() f=sales_data['ORDERID'].groupby(sales_data['USERID']).count() m=sales_data['AMOUNTINFO'].groupby(sales_data['USERID']).sum() #计算rfm得分 date=pd.datetime(2017,1,1) #选定一个时间节点,用于计算该时间节点与其他时间的距离 r_interval=(date-r).dt.days #计算天数 r_score=pd.cut(r_interval,5,labels=[5,4,3,2,1]) #计算得分 f_score=pd.cut(f,5,labels=[1,2,3,4,5]) m_score=pd.cut(m,5,labels=[1,2,3,4,5]) #将rfm得分放在一个数据框中 rfm=pd.DataFrame(np.array([r_score,f_score,m_score]).T,columns=['r_score','f_score','m_score'],index=r_score.index) print(rfm.head()) #合并rfm得分 rfm['rfm_comb']=rfm['r_score'].astype(str)+rfm['f_score'].astype(str)+rfm['m_score'].astype(str) print(rfm.head()) #保存rfm得分 rfm.to_csv(r'E:data analysis est fm.csv')
2、会员细分模型
(1)ABC分类法
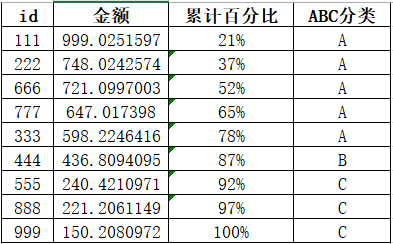
将目标数据倒序排列,然后做累计百分比,A类因素:累计百分比0%~80%,为主要影响因素;B类因素:累计百分比80~90%,为次要影响因素,C类因素:累计百分比90%~100%,为一般影响因素。
例:
(2)聚类法
具体做法见:用K-Means聚类分析做客户分群
3、会员流失预测模型
做会员流失预测模型的关键因素之一是要定义好“流失”,即处在何种状态,具备哪些特征的会员属于流失。
会员流失预测模型的实现方法属于分类算法,常用算法有逻辑回归、支持向量机、随机森林等。代码见:支持向量机、
4、会员特征分析模型
会员特征分析模型适用于两类场景:
一类:没有任何前期经验或特定目标,希望通过整体特征分析了解会员全貌。此时,可以通过一定方法先将用户划分为几类,然后基于类别的特征分析。
常用方法:(1)聚类,将用户分为几个群组,然后再分析不同群组的典型特征和群组间间的差异。
(2) 统计分析,将整体用户做统计分析,包括描述性统计、频数分布等,了解整体数据概况。
另一类:有明确的业务目标,希望能找到达到事件目标的会员特征,用于进一步的会员运营。
常用方法:(1)分类,利用分类规则例如决策树找到符合目标的关键变量以及对应的变量值,进而确定会员特征。代码见:构建决策树
(2)关联,使用关联规则找到不同属性、项目间的关联发生或序列发生关系,然后将会员属性特征(频繁项集)提供给运营。
(3)异常检测,使用非监督式的异常检测方法,从数据中找到异常数据样本,然后将这些数据样本特征提供给运营做进一步确认和审查。
5、营销响应预测模型
营销响应预测模型针对营销活动展开,通常在做会员营销活动之前,通过营销响应预测模型分析找到可能响应活动的会员特征以及整体响应的用户比例、数量和可能带来的销售额。
一般采用分类算法,常用逻辑回归、支持向量机、随机森林等。
步骤:(1)随机选择一定量的会员样本(1000条以上)
(2)针对选择的会员样本通过媒介和渠道发送营销活动信息
(3)收集营销活动数据
(4)通过上述步骤收集到所需样本集后,通过分类模型做营销响应预测
营销响应预测模型的结果一般包括两个方向:
(1)基于模型找到最可能产生购买转化行为的会员规则特征。
(2)基于模型预测可能产生的订单转化数量、转化率,以及转化客户的客单价大体计算出此次发送会员能得到的营销收入。