原创,专业,图文 hadoop-HA集群搭建,启动DataNode,检测启动状态,执行HDFS命令,启动YARN,HD - 集群,搭建,启动,DataNode,检测,状态,执行,HDFS,命令,YARN,权限,配置,客户端, 今日头条,最新,最好,最优秀,最靠谱,最有用,最好看,最有效,最热,排行榜,最牛,怎么办,怎么弄,解决方案,解决方法,怎么处理,如何处理,如何解决
|
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
详细配置可参考:
对yarn-site.xml文件的修改,涉及下表中的属性:
|
属性名 |
属性值 |
涉及范围 |
|
|
|
HA模式可不配置,但由于其它配置项可能有引用它,建议保持值为0.0.0.0,如果没有被引用到,则可不配置。 |
|
yarn.nodemanager.hostname |
0.0.0.0 |
|
|
yarn.nodemanager.aux-services |
mapreduce_shuffle |
|
|
以下为HA相关的配置,包括自动切换(可仅可在ResourceManager节点上配置) |
||
|
yarn.resourcemanager.ha.enabled |
true |
启用HA |
|
yarn.resourcemanager.cluster-id |
yarn-cluster |
可不同于HDFS的 |
|
yarn.resourcemanager.ha.rm-ids |
rm1,rm2 |
注意NodeManager要和ResourceManager一样配置 |
|
yarn.resourcemanager.hostname.rm1 |
hadoop1 |
|
|
yarn.resourcemanager.hostname.rm2 |
hadoop2 |
|
|
yarn.resourcemanager.webapp.address.rm1 |
hadoop1:8088 |
在浏览器上访问:http://hadoop1:8088,可以看到yarn的信息 |
|
yarn.resourcemanager.webapp.address.rm2 |
hadoop2:8088 |
在浏览器上访问:http://hadoop2:8088,可以看到yarn的信息 |
|
yarn.resourcemanager.zk-address |
hadoop11:2181,hadoop12:2182,hadoop13:2181 |
|
|
yarn.resourcemanager.ha.automatic-failover.enable |
true |
可不配置,因为当yarn.resourcemanager.ha.enabled为true时,它的默认值即为true |
|
以下为NodeManager配置 |
||
|
yarn.nodemanager.vmem-pmem-ratio |
|
每使用1MB物理内存,最多可用的虚拟内存数,默认值为2.1,在运行spark-sql时如果遇到“Yarn application has already exited with state FINISHED”,则应当检查NodeManager的日志,以查看是否该配置偏小原因 |
|
yarn.nodemanager.resource.cpu-vcores |
|
NodeManager总的可用虚拟CPU个数,默认值为8 |
|
yarn.nodemanager.resource.memory-mb |
|
该节点上YARN可使用的物理内存总量,默认是8192(MB) |
|
yarn.nodemanager.pmem-check-enabled |
|
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true |
|
yarn.nodemanager.vmem-check-enabled |
|
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true |
|
以下为ResourceManager配置 |
||
|
yarn.scheduler.minimum-allocation-mb |
|
单个容器可申请的最小内存 |
|
yarn.scheduler.maximum-allocation-mb |
|
单个容器可申请的最大内存 |
实际部署的时候一个参考配置:
|
<?xml version="1.0"?>
<configuration> <!--启用HA--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property>
<!--指定RM的cluster id--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property>
<!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property>
<!--分别指定RM的地址--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop2:8088</value> </property> <!--指定zk集群地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop11:2181,hadoop12:2182,hadoop13:2181</value> </property>
<!-- yarn中的nodemanager是否要提供一些辅助的服务 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
</configuration> |
yarn.nodemanager.hostname如果配置成具体的IP,则会导致每个NodeManager的配置不同。详细配置可参考:
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml。
Yarn HA的配置可以参考:
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html。
在hadoop1上配置完成后执行:
scp -r /home/toto/software/hadoop-2.8.0/etc/hadoop/* root@hadoop2:/home/tuzq/software/hadoop-2.8.0/etc/hadoop
scp -r /home/toto/software/hadoop-2.8.0/etc/hadoop/* root@hadoop3:/home/tuzq/software/hadoop-2.8.0/etc/hadoop
scp -r /home/toto/software/hadoop-2.8.0/etc/hadoop/* root@hadoop4:/home/tuzq/software/hadoop-2.8.0/etc/hadoop
scp -r /home/toto/software/hadoop-2.8.0/etc/hadoop/* root@hadoop5:/home/tuzq/software/hadoop-2.8.0/etc/hadoop
Zookeeper -> JournalNode -> 格式化NameNode -> 初始化JournalNode
-> 创建命名空间(zkfc) -> NameNode -> DataNode -> ResourceManager -> NodeManager。
但请注意首次启动NameNode之前,得先做format,也请注意备NameNode的启动方法。
在启动HDFS之前,需要先完成对NameNode的格式化。
mkdir -p /home/tuzq/software/hadoop-2.8.0/tmp/dfs/name
./zkServer.sh start
注意在启动其它之前先启动zookeeper。
在其中一个namenode(hadoop1)上执行:
cd $HADOOP_HOME
bin/hdfs zkfc -formatZK (第二次不用执行了)

10.4. 启动所有JournalNode(hadoop1,hadoop2,hadoop3上执行)
NameNode将元数据操作日志记录在JournalNode上,主备NameNode通过记录在JouralNode上的日志完成元数据同步。
在所有JournalNode上执行:
cd $HADOOP_HOME
sbin/hadoop-daemon.sh start journalnode

执行完成之后执行下面的命令进行查看:
[root@hadoop2 hadoop-2.8.0]# jps
3314 Jps
3267 JournalNode
[root@hadoop2 hadoop-2.8.0]#
注意,在执行“hdfs namenode -format”之前,必须先启动好JournalNode,而format又必须在启动namenode之前。
10.5初始化namenode
进入hadoop1接着执行下面的命令(初始化namenode,如果之前已经初始化过了,此时不需要再次重新初始化namenode):
hdfs namenode -format (第二次不用执行了)
如果是非HA转HA才需要这一步,在其中一个JournalNode(在hadoop1)上执行:
bin/hdfs namenode -initializeSharedEdits (第二次不用执行了):

此命令默认是交互式的,加上参数-force转成非交互式。
在所有JournalNode创建如下目录(第二次不用执行了):
mkdir -p /home/tuzq/software/hadoop-2.8.0/journal/mycluster/current
10.7. 启动主NameNode
下面进入的是hadoop1这台机器。关于启动hadoop2上的namenode在下面的博文中有介绍。
1) 进入$HADOOP_HOME目录
2) 启动主NameNode:
sbin/hadoop-daemon.sh start namenode

启动时,遇到如下所示的错误,则表示NameNode不能免密码登录自己。如果之前使用IP可以免密码登录自己,则原因一般是因为没有使用主机名登录过自己,因此解决办法是使用主机名SSH一下
10.8. 启动备NameNode
进入hadoop2,执行以下命令
bin/hdfs namenode -bootstrapStandby

出现:Re-format的都选择N
sbin/hadoop-daemon.sh start namenode

如果没有执行第1步,直接启动会遇到如下错误:
No valid image files found
或者在该NameNode日志会发现如下错误:
2016-04-08 14:08:39,745 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
java.io.IOException: NameNode is not formatted.
在所有NameNode(即hadoop1和hadoop2上都执行命令)上启动主备切换进程:
sbin/hadoop-daemon.sh start zkfc

只有启动了DFSZKFailoverController进程,HDFS才能自动切换主备。
注:zkfc是zookeeper failover controller的缩写。
在各个DataNode上分别执行(即hadoop3,hadoop4,hadoop5上):
sbin/hadoop-daemon.sh start datanode

如果有发现DataNode进程并没有起来,可以试试删除logs目录下的DataNode日志,再得启看看。
1) 使用JDK提供的jps命令,查看相应的进程是否已启动
2) 检查$HADOOP_HOME/logs目录下的log和out文件,看看是否有异常信息。
启动后nn1和nn2都处于备机状态,将nn1切换为主机(下面的命令在hadoop1上执行):
bin/hdfs haadmin -transitionToActive nn1

执行jps命令(注:jps是jdk中的一个命令,不是jre中的命令),可看到DataNode进程:
|
$ jps 18669 DataNode 24542 Jps |
执行jps命令,可看到NameNode进程:
|
$ jps 18669 NameNode 24542 Jps |
执行HDFS命令,以进一步检验是否已经安装成功和配置好。关于HDFS命令的用法,直接运行命令hdfs或hdfs dfs,即可看到相关的用法说明。
hdfs dfsadmin -report
注意如果core-site.xml中的配置项fs.default.name的值为file:///,则会报:
report: FileSystem file:/// is not an HDFS file system
Usage: hdfs dfsadmin [-report] [-live] [-dead] [-decommissioning]
解决这个问题,只需要将fs.default.name的值设置为和fs.defaultFS相同的值。
10.12.2启动hdfs和yarn(在hadoop1,hadoop2上分别执行)
进入hadoop1机器,执行命令:
[root@hadoop1sbin]# sbin/start-dfs.sh

cd $HADOOP_HOME
# sbin/start-yarn.sh (注意:hadoop1和hadoop2都启动)

在浏览器上访问:http://hadoop1:50070/,界面如下:

上面显示的是主的,是active状态。
再在浏览器上访问:http://hadoop2:50070/

通过上面,发现hadoop2是一种备用状态。
访问yarn(访问地址可以在yarn-site.xml中查找到),访问之后的效果如下http://hadoop1:8088/cluster:

如查看NameNode1和NameNode2分别是主还是备:
|
$ hdfs haadmin -getServiceState nn1 standby $ hdfs haadmin -getServiceState nn2 active |
10.12.3. hdfs dfs ls
注意:下面的命令只有在启动了yarn之后才会可用
“hdfs dfs -ls”带一个参数,如果参数以“hdfs://URI”打头表示访问HDFS,否则相当于ls。其中URI为NameNode的IP或主机名,可以包含端口号,即hdfs-site.xml中“dfs.namenode.rpc-address”指定的值。
“hdfs dfs -ls”要求默认端口为8020,如果配置成9000,则需要指定端口号,否则不用指定端口,这一点类似于浏览器访问一个URL。示例:
|
> hdfs dfs -ls hdfs://hadoop1:8020/ |

8020后面的斜杠/是和必须的,否则被当作文件。如果不指定端口号8020,则使用默认的8020,“hadoop1:8020”由hdfs-site.xml中“dfs.namenode.rpc-address”指定。
不难看出“hdfs dfs -ls”可以操作不同的HDFS集群,只需要指定不同的URI。
如果想通过hdfs协议查看文件列表或者文件,可以使用如下方式:

文件上传后,被存储在DataNode的data目录下(由DataNode的hdfs-site.xml中的属性“dfs.datanode.data.dir”指定),

如:$HADOOP_HOME/data/data/current/BP-472842913-192.168.106.91-1497065109036/current/finalized/subdir0/subdir0/blk_1073741825
文件名中的“blk”是block,即块的意思,默认情况下blk_1073741825即为文件的一个完整块,Hadoop未对它进额外处理。
上传文件命令,示例:
|
> hdfs dfs -put /etc/SuSE-release hdfs://192.168.106.91/ |
删除文件命令,示例:
|
> hdfs dfs -rm hdfs://192.168.106.91/SuSE-release Deleted hdfs://192.168.106.91/SuSE-release |
当有NameNode机器损坏时,必然存在新NameNode来替代。把配置修改成指向新NameNode,然后以备机形式启动新NameNode,这样新的NameNode即加入到Cluster中:
|
1) bin/hdfs namenode -bootstrapStandby 2) sbin/hadoop-daemon.sh start namenode |
10.12.7. HDFS只允许有一主一备两个NameNode
如果试图配置三个NameNode,如:
|
dfs.ha.namenodes.test nm1,nm2,nm3
The prefix for a given nameservice, contains a comma-separated list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE).
|
则运行“hdfs namenode -bootstrapStandby”时会报如下错误,表示在同一NameSpace内不能超过2个NameNode:
|
16/04/11 09:51:57 ERROR namenode.NameNode: Failed to start namenode. java.io.IOException: java.lang.IllegalArgumentException: Expected exactly 2 NameNodes in namespace 'test'. Instead, got only 3 (NN ids were 'nm1','nm2','nm3' at org.apache.hadoop.hdfs.server.namenode.ha.BootstrapStandby.run(BootstrapStandby.java:425) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1454) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1554) Caused by: java.lang.IllegalArgumentException: Expected exactly 2 NameNodes in namespace 'test'. Instead, got only 3 (NN ids were 'nm1','nm2','nm3' at com.google.common.base.Preconditions.checkArgument(Preconditions.java:115) |
10.12.8. 存储均衡start-balancer.sh
示例:start-balancer.sh –t 10%
10%表示机器与机器之间磁盘使用率偏差小于10%时认为均衡,否则做均衡搬动。“start-balancer.sh”调用“hdfs start balancer”来做均衡,可以调用stop-balancer.sh停止均衡。
均衡过程非常慢,但是均衡过程中,仍能够正常访问HDFS,包括往HDFS上传文件。
|
[VM2016@hadoop-030 /data4/hadoop/sbin]$ hdfs balancer # 可以改为调用start-balancer.sh 16/04/08 14:26:55 INFO balancer.Balancer: namenodes = [hdfs://test] // test为HDFS的cluster名 16/04/08 14:26:55 INFO balancer.Balancer: parameters = Balancer.Parameters[BalancingPolicy.Node, threshold=10.0, max idle iteration = 5, number of nodes to be excluded = 0, number of nodes to be included = 0] Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.231:50010 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.229:50010 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.213:50010 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.208:50010 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.232:50010 16/04/08 14:26:56 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.207:50010 16/04/08 14:26:56 INFO balancer.Balancer: 5 over-utilized: [192.168.1.231:50010:DISK, 192.168.1.229:50010:DISK, 192.168.1.213:50010:DISK, 192.168.1.208:50010:DISK, 192.168.1.232:50010:DISK] 16/04/08 14:26:56 INFO balancer.Balancer: 1 underutilized(未充分利用的): [192.168.1.207:50010:DISK] # 数据将移向该节点 16/04/08 14:26:56 INFO balancer.Balancer: Need to move 816.01 GB to make the cluster balanced. # 需要移动816.01G数据达到平衡 16/04/08 14:26:56 INFO balancer.Balancer: Decided to move 10 GB bytes from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK # 从192.168.1.231移动10G数据到192.168.1.207 16/04/08 14:26:56 INFO balancer.Balancer: Will move 10 GB in this iteration
16/04/08 14:32:58 INFO balancer.Dispatcher: Successfully moved blk_1073749366_8542 with size=77829046 from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 16/04/08 14:32:59 INFO balancer.Dispatcher: Successfully moved blk_1073749386_8562 with size=77829046 from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.231:50010 16/04/08 14:33:34 INFO balancer.Dispatcher: Successfully moved blk_1073749378_8554 with size=77829046 from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.231:50010 16/04/08 14:34:38 INFO balancer.Dispatcher: Successfully moved blk_1073749371_8547 with size=134217728 from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 16/04/08 14:34:54 INFO balancer.Dispatcher: Successfully moved blk_1073749395_8571 with size=134217728 from 192.168.1.231:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.231:50010 Apr 8, 2016 2:35:01 PM 0 478.67 MB 816.01 GB 10 GB 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.213:50010 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.229:50010 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.232:50010 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.231:50010 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.208:50010 16/04/08 14:35:10 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.1.207:50010 16/04/08 14:35:10 INFO balancer.Balancer: 5 over-utilized: [192.168.1.213:50010:DISK, 192.168.1.229:50010:DISK, 192.168.1.232:50010:DISK, 192.168.1.231:50010:DISK, 192.168.1.208:50010:DISK] 16/04/08 14:35:10 INFO balancer.Balancer: 1 underutilized(未充分利用的): [192.168.1.207:50010:DISK] 16/04/08 14:35:10 INFO balancer.Balancer: Need to move 815.45 GB to make the cluster balanced. 16/04/08 14:35:10 INFO balancer.Balancer: Decided to move 10 GB bytes from 192.168.1.213:50010:DISK to 192.168.1.207:50010:DISK 16/04/08 14:35:10 INFO balancer.Balancer: Will move 10 GB in this iteration
16/04/08 14:41:18 INFO balancer.Dispatcher: Successfully moved blk_1073760371_19547 with size=77829046 from 192.168.1.213:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 16/04/08 14:41:19 INFO balancer.Dispatcher: Successfully moved blk_1073760385_19561 with size=77829046 from 192.168.1.213:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 16/04/08 14:41:22 INFO balancer.Dispatcher: Successfully moved blk_1073760393_19569 with size=77829046 from 192.168.1.213:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 16/04/08 14:41:23 INFO balancer.Dispatcher: Successfully moved blk_1073760363_19539 with size=77829046 from 192.168.1.213:50010:DISK to 192.168.1.207:50010:DISK through 192.168.1.213:50010 |
找一台已有JournalNode节点,修改它的hdfs-site.xml,将新增的Journal包含进来,如在
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster
的基础上新增hadoop6和hadoop7两个JournalNode:
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485;hadoop6:8485;hadoop7:8485/mycluster
然后将安装目录和数据目录(hdfs-site.xml中的dfs.journalnode.edits.dir指定的目录)都复制到新的节点。
如果不复制JournalNode的数据目录,则新节点上的JournalNode会报错“Journal Storage Directory /data/journal/test not formatted”,将来的版本可能会实现自动同步。
接下来,就可以在新节点上启动好JournalNode(不需要做什么初始化),并重启下NameNode。注意观察JournalNode日志,查看是否启动成功,当日志显示为以下这样的INFO级别日志则表示启动成功:
2016-04-26 10:31:11,160 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /data/journal/test/current/edits_inprogress_0000000000000194269 -> /data/journal/test/current/edits_0000000000000194269-0000000000000194270
11. 启动YARN
1) 进入$HADOOP_HOME/sbin目录
2) 在主备两台都执行:start-yarn.sh,即开始启动YARN
若启动成功,则在Master节点执行jps,可以看到ResourceManager:
|
> jps 24689 NameNode 30156 Jps 28861 ResourceManager |
在Slaves节点执行jps,可以看到NodeManager:
|
$ jps 14019 NodeManager 23257 DataNode 15115 Jps |
如果只需要单独启动指定节点上的ResourceManager,这样:
sbin/yarn-daemon.sh start resourcemanager
对于NodeManager,则是这样:
sbin/yarn-daemon.sh start nodemanager
列举YARN集群中的所有NodeManager,如(注意参数间的空格,直接执行yarn可以看到使用帮助):
[root@hadoop1sbin]# yarn node –list

查看指定NodeManager的状态(通过上面查出来的结果进行查询),如:
|
[root@hadoop1 hadoop]# yarn node -status hadoop5:59894 Node Report : Node-Id : hadoop5:59894 Rack : /default-rack Node-State : RUNNING Node-Http-Address : hadoop5:8042 Last-Health-Update : 星期六 10/六月/17 12:30:38:20CST Health-Report : Containers : 0 Memory-Used : 0MB Memory-Capacity : 8192MB CPU-Used : 0 vcores CPU-Capacity : 8 vcores Node-Labels : Resource Utilization by Node : PMem:733 MB, VMem:733 MB, VCores:0.0 Resource Utilization by Containers : PMem:0 MB, VMem:0 MB, VCores:0.0
[root@hadoop1 hadoop]# |
11.2.3. yarn rmadmin -getServiceState rm1
查看rm1的主备状态,即查看它是主(active)还是备(standby)。

11.2.4. yarn rmadmin -transitionToStandby rm1
将rm1从主切为备。
更多的yarn命令可以参考:
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YarnCommands.html。
在安装目录的share/hadoop/mapreduce子目录下,有现存的示例程序:
|
hadoop@VM-40-171-sles10-64:~/hadoop> ls share/hadoop/mapreduce hadoop-mapreduce-client-app-2.7.2.jar hadoop-mapreduce-client-jobclient-2.7.2-tests.jar hadoop-mapreduce-client-common-2.7.2.jar hadoop-mapreduce-client-shuffle-2.7.2.jar hadoop-mapreduce-client-core-2.7.2.jar hadoop-mapreduce-examples-2.7.2.jar hadoop-mapreduce-client-hs-2.7.2.jar lib hadoop-mapreduce-client-hs-plugins-2.7.2.jar lib-examples hadoop-mapreduce-client-jobclient-2.7.2.jar sources |
跑一个示例程序试试:
|
hdfs dfs -put /etc/hosts hdfs://test/in/ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://test/in/ hdfs://test/out/ |
运行过程中,使用java的jps命令,可以看到yarn启动了名为YarnChild的进程。
wordcount运行完成后,结果会保存在out目录下,保存结果的文件名类似于“part-r-00000”。另外,跑这个示例程序有两个需求注意的点:
1) in目录下要有文本文件,或in即为被统计的文本文件,可以为HDFS上的文件或目录,也可以为本地文件或目录
2) out目录不能存在,程序会自动去创建它,如果已经存在则会报错。
包hadoop-mapreduce-examples-2.7.2.jar中含有多个示例程序,不带参数运行,即可看到用法:
|
> hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount Usage: wordcount
> hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar An example program must be given as the first argument. Valid program names are: aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files. aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files. bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi. dbcount: An example job that count the pageview counts from a database. distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi. grep: A map/reduce program that counts the matches of a regex in the input. join: A job that effects a join over sorted, equally partitioned datasets multifilewc: A job that counts words from several files. pentomino: A map/reduce tile laying program to find solutions to pentomino problems. pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method. randomtextwriter: A map/reduce program that writes 10GB of random textual data per node. randomwriter: A map/reduce program that writes 10GB of random data per node. secondarysort: An example defining a secondary sort to the reduce. sort: A map/reduce program that sorts the data written by the random writer. sudoku: A sudoku solver. teragen: Generate data for the terasort terasort: Run the terasort teravalidate: Checking results of terasort wordcount: A map/reduce program that counts the words in the input files. wordmean: A map/reduce program that counts the average length of the words in the input files. wordmedian: A map/reduce program that counts the median length of the words in the input files. wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files. |
修改日志级别为DEBBUG,并打屏:
export HADOOP_ROOT_LOGGER=DEBUG,console13. HDFS权限配置
|
dfs.permissions.enabled = true dfs.permissions.superusergroup = supergroup dfs.cluster.administrators = ACL-for-admins dfs.namenode.acls.enabled = true dfs.web.ugi = webuser,webgroup |
|
fs.permissions.umask-mode = 022 hadoop.security.authentication = simple 安全验证规则,可为simple或kerberos |
|
// g++ -g -o x x.cpp -L$JAVA_HOME/lib/amd64/jli -ljli -L$JAVA_HOME/jre/lib/amd64/server -ljvm -I$HADOOP_HOME/include $HADOOP_HOME/lib/native/libhdfs.a -lpthread -ldl #include "hdfs.h" #include #include #include
int main(int argc, char **argv) { #if 0 hdfsFS fs = hdfsConnect("default", 0); // HA方式 const char* writePath = "hdfs://mycluster/tmp/testfile.txt"; hdfsFile writeFile = hdfsOpenFile(fs, writePath, O_WRONLY |O_CREAT, 0, 0, 0); if(!writeFile) { fprintf(stderr, "Failed to open %s for writing! ", writePath); exit(-1); } const char* buffer = "Hello, World! "; tSize num_written_bytes = hdfsWrite(fs, writeFile, (void*)buffer, strlen(buffer)+1); if (hdfsFlush(fs, writeFile)) { fprintf(stderr, "Failed to 'flush' %s ", writePath); exit(-1); } hdfsCloseFile(fs, writeFile); #else struct hdfsBuilder* bld = hdfsNewBuilder(); hdfsBuilderSetNameNode(bld, "default"); // HA方式 hdfsFS fs = hdfsBuilderConnect(bld); if (NULL == fs) { fprintf(stderr, "Failed to connect hdfs "); exit(-1); } int num_entries = 0; hdfsFileInfo* entries; if (argc < 2) entries = hdfsListDirectory(fs, "/", &num_entries); else entries = hdfsListDirectory(fs, argv[1], &num_entries); fprintf(stdout, "num_entries: %d ", num_entries); for (int i=0; i<num_entries; ++i) </num_entries; ++i)<> { fprintf(stdout, "%s ", entries[i].mName); } hdfsFreeFileInfo(entries, num_entries); hdfsDisconnect(fs); //hdfsFreeBuilder(bld); #endif return 0; } |
运行之前需要设置好CLASSPATH,如果设置不当,可能会遇到不少困难,比如期望操作HDFS上的文件和目录,却变成了本地的文件和目录,如者诸于“java.net.UnknownHostException”类的错误等。
为避免出现错误,强烈建议使用命令“hadoop classpath --glob”取得正确的CLASSPATH值。
另外还需要设置好libjli.so和libjvm.so两个库的LD_LIBRARY_PATH,如:
|
export LD_LIBRARY_PATH=$JAVA_HOME/lib/amd64/jli:$JAVA_HOME/jre/lib/amd64/server:$LD_LIBRARY_PATH |
15.1. 执行“hdfs dfs -ls”时报ConnectException
原因可能是指定的端口号9000不对,该端口号由hdfs-site.xml中的属性“dfs.namenode.rpc-address”指定,即为NameNode的RPC服务端口号。
文件上传后,被存储在DataNode的data(由DataNode的hdfs-site.xml中的属性“dfs.datanode.data.dir”指定)目录下,如:
$HADOOP_HOME/data/current/BP-139798373-192.168.106.91-1397735615751/current/finalized/blk_1073741825
文件名中的“blk”是block,即块的意思,默认情况下blk_1073741825即为文件的一个完整块,Hadoop未对它进额外处理。
|
hdfs dfs -ls hdfs://192.168.106.91:9000 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 14/04/17 12:04:02 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/tuzq/software/hadoop-2.8.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c ', or link it with '-z noexecstack'. 14/04/17 12:04:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/04/17 12:04:03 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring. 14/04/17 12:04:03 WARN conf.Configuration: mapred-site.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring. ls: Call From VM-40-171-sles10-64/192.168.106.91 to VM-40-171-sles10-64:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused |
15.2. Initialization failed for Block pool
可能是因为对NameNode做format之前,没有清空DataNode的data目录。
|
“Incompatible clusterIDs”的错误原因是在执行“hdfs namenode -format”之前,没有清空DataNode节点的data目录。
网上一些文章和帖子说是tmp目录,它本身也是没问题的,但Hadoop 2.7.2是data目录,实际上这个信息已经由日志的“/home/tuzq/software/hadoop-2.8.0/data”指出,所以不能死死的参照网上的解决办法,遇到问题时多仔细观察。
从上述描述不难看出,解决办法就是清空所有DataNode的data目录,但注意不要将data目录本身给删除了。 data目录由core-site.xml文件中的属性“dfs.datanode.data.dir”指定。
2014-04-17 19:30:33,075 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /home/tuzq/software/hadoop-2.8.0/data/in_use.lock acquired by nodename 28326@localhost 2014-04-17 19:30:33,078 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool (Datanode Uuid unassigned) service to /192.168.106.91:9001 java.io.IOException: Incompatible clusterIDs in /home/tuzq/software/hadoop-2.8.0/data: namenode clusterID = CID-50401d89-a33e-47bf-9d14-914d8f1c4862; datanode clusterID = CID-153d6fcb-d037-4156-b63a-10d6be224091 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:472) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:225) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:249) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:929) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:900) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:274) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:220) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:815) at java.lang.Thread.run(Thread.java:744) 2014-04-17 19:30:33,081 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool (Datanode Uuid unassigned) service to /192.168.106.91:9001 2014-04-17 19:30:33,184 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN java.lang.Exception: trace at org.apache.hadoop.hdfs.server.datanode.BPOfferService.getBlockPoolId(BPOfferService.java:143) at org.apache.hadoop.hdfs.server.datanode.BlockPoolManager.remove(BlockPoolManager.java:91) at org.apache.hadoop.hdfs.server.datanode.DataNode.shutdownBlockPool(DataNode.java:859) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.shutdownActor(BPOfferService.java:350) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.cleanUp(BPServiceActor.java:619) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:837) at java.lang.Thread.run(Thread.java:744) 2014-04-17 19:30:33,184 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool (Datanode Uuid unassigned) 2014-04-17 19:30:33,184 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN java.lang.Exception: trace at org.apache.hadoop.hdfs.server.datanode.BPOfferService.getBlockPoolId(BPOfferService.java:143) at org.apache.hadoop.hdfs.server.datanode.DataNode.shutdownBlockPool(DataNode.java:861) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.shutdownActor(BPOfferService.java:350) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.cleanUp(BPServiceActor.java:619) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:837) at java.lang.Thread.run(Thread.java:744) 2014-04-17 19:30:35,185 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Exiting Datanode 2014-04-17 19:30:35,187 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 0 2014-04-17 19:30:35,189 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down DataNode at localhost/127.0.0.1 ************************************************************/ |
15.4. Inconsistent checkpoint fields
|
SecondaryNameNode中的“Inconsistent checkpoint fields”错误原因,可能是因为没有设置好SecondaryNameNode上core-site.xml文件中的“hadoop.tmp.dir”。
2014-04-17 11:42:18,189 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Log Size Trigger :1000000 txns 2014-04-17 11:43:18,365 ERROR org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Exception in doCheckpoint java.io.IOException: Inconsistent checkpoint fields. LV = -56 namespaceID = 1384221685 cTime = 0 ; clusterId = CID-319b9698-c88d-4fe2-8cb2-c4f440f690d4 ; blockpoolId = BP-1627258458-192.168.106.91-1397735061985. Expecting respectively: -56; 476845826; 0; CID-50401d89-a33e-47bf-9d14-914d8f1c4862; BP-2131387753-192.168.106.91-1397730036484. at org.apache.hadoop.hdfs.server.namenode.CheckpointSignature.validateStorageInfo(CheckpointSignature.java:135) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.doCheckpoint(SecondaryNameNode.java:518) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.doWork(SecondaryNameNode.java:383) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode$1.run(SecondaryNameNode.java:349) at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:415) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.run(SecondaryNameNode.java:345) at java.lang.Thread.run(Thread.java:744)
另外,也请配置好SecondaryNameNode上hdfs-site.xml中的“dfs.datanode.data.dir”为合适的值: hadoop.tmp.dir /home/tuzq/software/current/tmp A base for other temporary directories. |
15.5. fs.defaultFS is file:///
在core-site.xml中,当只填写了fs.defaultFS,而fs.default.name为默认的file:///时,会报此错误。解决方法是设置成相同的值。
15.6. a shared edits dir must not be specified if HA is not enabled
该错误可能是因为hdfs-site.xml中没有配置dfs.nameservices或dfs.ha.namenodes.mycluster。
15.7. /tmp/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
只需按日志中提示的,创建好相应的目录。
15.8. The auxService:mapreduce_shuffle does not exist
问题原因是没有配置yarn-site.xml中的“yarn.nodemanager.aux-services”,将它的值配置为mapreduce_shuffle,然后重启yarn问题即解决。记住所有yarn节点都需要修改,包括ResourceManager和NodeManager,如果NodeManager上的没有修改,仍然会报这个错误。
15.9. org.apache.hadoop.ipc.Client: Retrying connect to server
该问题,有可能是因为NodeManager中的yarn-site.xml和ResourceManager上的不一致,比如NodeManager没有配置yarn.resourcemanager.ha.rm-ids。
15.10. mapreduce.Job: Running job: job_1445931397013_0001
Hadoop提交mapreduce任务时,卡在mapreduce.Job: Running job: job_1445931397013_0001处。
问题原因可能是因为yarn的NodeManager没起来,可以用jdk的jps确认下。
该问题也有可能是因为NodeManager中的yarn-site.xml和ResourceManager上的不一致,比如NodeManager没有配置yarn.resourcemanager.ha.rm-ids。
15.11. Could not format one or more JournalNodes
执行“./hdfs namenode -format”时报“Could not format one or more JournalNodes”。
可能是hdfs-site.xml中的dfs.namenode.shared.edits.dir配置错误,比如重复了,如:
qjournal://hadoop-168-254:8485;hadoop-168-254:8485;hadoop-168-253:8485;hadoop-168-252:8485;hadoop-168-251:8485/mycluster
修复后,重启JournalNode,问题可能就解决了。
15.12. org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Already in standby state
遇到这个错误,可能是yarn-site.xml中的yarn.resourcemanager.webapp.address配置错误,比如配置成了两个yarn.resourcemanager.webapp.address.rm1,实际应当是yarn.resourcemanager.webapp.address.rm1和yarn.resourcemanager.webapp.address.rm2。
15.13. No valid image files found
如果是备NameNode,执行下“hdfs namenode -bootstrapStandby”再启动。
2015-12-01 15:24:39,535 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.io.FileNotFoundException: No valid image files found
at org.apache.hadoop.hdfs.server.namenode.FSImageTransactionalStorageInspector.getLatestImages(FSImageTransactionalStorageInspector.java:165)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:623)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:294)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:975)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:681)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:584)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:644)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:811)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:795)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1488)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1554)
2015-12-01 15:24:39,536 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
2015-12-01 15:24:39,539 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
15.14. xceivercount 4097 exceeds the limit of concurrent xcievers 4096
此错误的原因是hdfs-site.xml中的配置项“dfs.datanode.max.xcievers”值4096过小,需要改大一点。该错误会导致hbase报“notservingregionexception”。
16/04/06 14:30:34 ERROR namenode.NameNode: Failed to start namenode.
15.15. java.lang.IllegalArgumentException: Unable to construct journal, qjournal://hadoop-030:8485;hadoop-031:8454;hadoop-032
执行“hdfs namenode -format”遇到上述错误时,是因为hdfs-site.xml中的配置dfs.namenode.shared.edits.dir配置错误,其中的hadoop-032省了“:8454”部分。
15.16. Bad URI 'qjournal://hadoop-030:8485;hadoop-031:8454;hadoop-032:8454': must identify journal in path component
是因为配置hdfs-site.xml中的“dfs.namenode.shared.edits.dir”时,路径少带了cluster名。
15.17. 16/04/06 14:48:19 INFO ipc.Client: Retrying connect to server: hadoop-032/10.143.136.211:8454. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
检查hdfs-site.xml中的“dfs.namenode.shared.edits.dir”值,JournalNode默认端口是8485,不是8454,确认是否有写错。JournalNode端口由hdfs-site.xml中的配置项dfs.journalnode.rpc-address决定。
15.18. Exception in thread "main" org.apache.hadoop.HadoopIllegalArgumentException: Could not get the namenode ID of this node. You may run zkfc on the node other than namenode.
执行“hdfs zkfc -formatZK”遇到上面这个错误,是因为还没有执行“hdfs namenode -format”。NameNode ID是在“hdfs namenode -format”时生成的。
15.19. 2016-04-06 17:08:07,690 INFO org.apache.hadoop.hdfs.server.common.Storage: Storage directory [DISK]file:/data3/datanode/data/ has already been used.
以非root用户启动DataNode,但启动不了,在它的日志文件中发现如下错误信息:
2016-04-06 17:08:07,707 INFO org.apache.hadoop.hdfs.server.common.Storage: Analyzing storage directories for bpid BP-418073539-10.143.136.207-1459927327462
2016-04-06 17:08:07,707 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to analyze storage directories for block pool BP-418073539-10.143.136.207-1459927327462
java.io.IOException: BlockPoolSliceStorage.recoverTransitionRead: attempt to load an used block storage: /data3/datanode/data/current/BP-418073539-10.143.136.207-1459927327462
继续寻找,会发现还存在如何错误提示:
Invalid dfs.datanode.data.dir /data3/datanode/data:
EPERM: Operation not permitted
使用命令“ls -l”检查目录/data3/datanode/data的权限设置,发现owner为root,原因是因为之前使用root启动过DataNode,将owner改过来即可解决此问题。
15.20. 2016-04-06 18:00:26,939 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: hadoop-031/10.143.136.208:8020
DataNode的日志文件不停地记录如下日志,是因为DataNode将作为主NameNode,但实际上10.143.136.208并没有启动,主NameNode不是它。这个并不表示DataNode没有起来,而是因为DataNode会同时和主NameNode和备NameNode建立心跳,当备NameNode没有起来时,有这些日志是正常现象。
2016-04-06 18:00:32,940 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop-031/10.143.136.208:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2016-04-06 17:55:44,555 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Namenode Block pool BP-418073539-10.143.136.207-1459927327462 (Datanode Uuid 2d115d45-fd48-4e86-97b1-e74a1f87e1ca) service to hadoop-030/10.143.136.207:8020 trying to claim ACTIVE state with txid=1
“trying to claim ACTIVE state”出自于hadoop/hdfs/server/datanode/BPOfferService.java中的updateActorStatesFromHeartbeat()。
2016-04-06 17:55:49,893 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop-031/10.143.136.208:8020. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
“Retrying connect to server”出自于hadoop/ipc/Client.java中的handleConnectionTimeout()和handleConnectionFailure()。
15.21. ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state FINISHED!
如果遇到这个错误,请检查NodeManager日志,如果发现有如下所示信息:
WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Container [pid=26665,containerID=container_1461657380500_0020_02_000001] is running beyond virtual memory limits. Current usage: 345.0 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
则表示需要增大yarn-site.xmk的配置项yarn.nodemanager.vmem-pmem-ratio的值,该配置项默认值为2.1。
16/10/13 10:23:19 ERROR client.TransportClient: Failed to send RPC 7614640087981520382 to /10.143.136.231:34800: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
16/10/13 10:23:19 ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map()) to AM was unsuccessful
java.io.IOException: Failed to send RPC 7614640087981520382 to /10.143.136.231:34800: java.nio.channels.ClosedChannelException
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:249)
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:233)
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:680)
at io.netty.util.concurrent.DefaultPromise$LateListeners.run(DefaultPromise.java:845)
at io.netty.util.concurrent.DefaultPromise$LateListenerNotifier.run(DefaultPromise.java:873)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:357)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:745)




hadoop中访问不了8088 相关内容
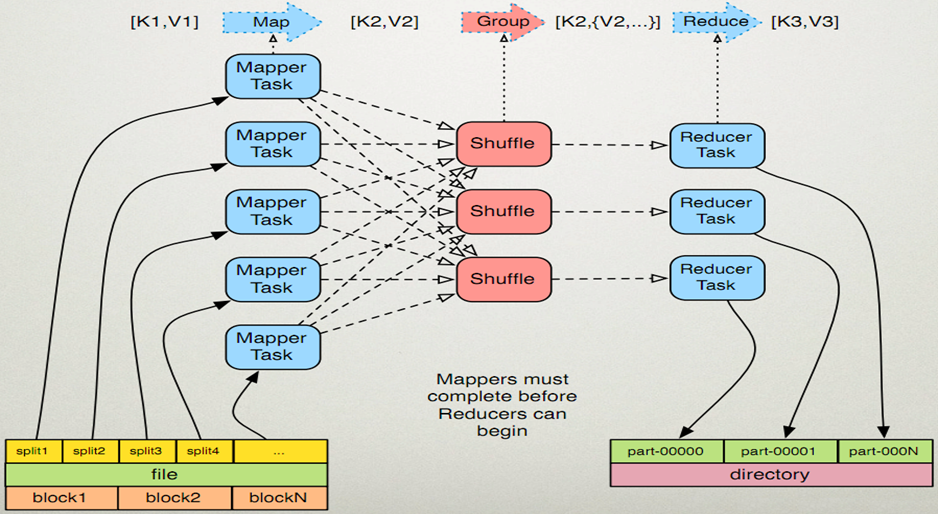

hadoop中访问不了8088 相关内容
hadoop中访问不了8088 相关内容




hadoop中访问不了8088 相关内容















