引用GitHub 上 ltadpoles的前端面试
目录
HTTP相关
浏览器相关
其他
HTTP相关
1. HTTP有什么特点
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由
Content-Type加以标记 - 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接 (深入-持久连接、管线化)
- 无状态:HTTP协议是无状态协议(
Cookie的出现)
2. http和https协议有什么区别
http: 是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(
TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少
https: 是以安全为目标的HTTP通道,简单讲是
HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全
3. http状态码有那些?分别代表是什么意思
常用 http 状态码:
200OK服务器成功处理了请求301/302Moved Permanently(重定向)请求的URL已移走404Not Found(页面丢失)未找到资源403服务器拒绝请求408(请求超时) 服务器等候请求时发生超时501Internal Server Error服务器遇到一个错误,使其无法对请求提供服务502(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应504(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求
更多 参考 这里
4. 什么是HTTP持久化和管线化
出现背景:
HTTP最初的版本中,每进行一次HTTP通信,就要断开一次TCP连接(无连接)
为解决上述问题,HTTP/1.1 增加了持久连接(HTTP Persistent Connections )的方法,其特点是,只要一方未明确提出断开连接,则另一方保持 TCP 连接状态
管线化是指将多个
HTTP请求整批发送,在发送过程中不用等待对方响应
管线化是在持久连接的基础上实现的,管线化的实现,能够同时并行发送多个请求,而不需要一个接一个的等待响应
5. Http报文
HTTP报文是面向文本的,报文中的每一个字段都是一些ASCII码串,各个字段的长度是不确定的。HTTP有两类报文:请求报文和响应报文
HTTP的这两种报文都由三部分组成:开始行、首部行、实体主体
参考 这里
6. 从输入URL到页面加载全过程
参考 这里
7. 为什么利用多个域名来存储网站资源会更有效
CDN缓存更方便- 突破浏览器并发限制
- 节约
cookie带宽 - 节约主域名的连接数,优化页面响应速度
- 防止不必要的安全问题
浏览器相关
1. 浏览器是由什么组成的
从原理构成上分为七个模块,分别是
User Interface(用户界面)、Browser engine(浏览器引擎)、Rendering engine(渲染引擎)、Networking(网络)、JavaScript Interpreter(js解释器)、UI Backend(UI后端)、Date Persistence(数据持久化存储)
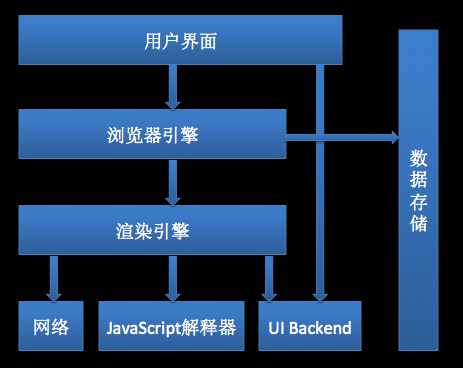
其中,最重要的是渲染引擎(内核)和
JavaScript解释器(JavaScript引擎)
浏览器内核主要负责
HTML、CSS的解析,页面布局、渲染与复合层合成;JavaScript引擎负责JavaScript代码的解释与执行
2. 浏览器缓存机制
浏览器的缓存机制也就是我们说的
HTTP缓存机制,其机制是根据HTTP报文的缓存标识进行的
参考 这里
3. 浏览器渲染机制
参考 这里
4. 几个很实用的BOM属性对象方法
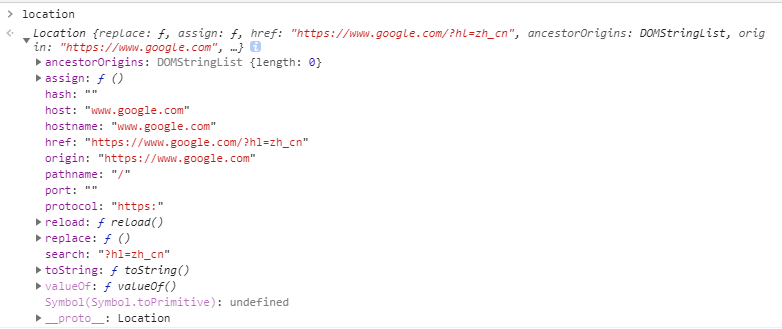
location 对象:主要存储 url 相关信息
history 对象:浏览历史信息相关
history.go() // 前进或后退指定的页面数 history.go(num);
history.back() // 后退一页
history.forward() // 前进一页
navigator 对象:浏览器信息相关
navigator.userAgent //返回用户代理头的字符串表示(就是包括浏览器版本信息等的字符串)
navigator.cookieEnabled // 返回浏览器是否支持(启用)cookie
其他
1. 谈谈你对SEO的理解
SEO:搜索引擎优化,其目的是为了使网站能够更好的被搜索引擎抓取,提高在搜索引擎内的自然排名,从而带来更多的免费流量,获取收益
SEO主要有两种方法,站内优化和站外优化
2. 前端怎么控制管理路由
路由就是浏览器地址栏中的 url 与所见网页的对应关系
前端路由的实现方式:
基于
hash(ocation.hash+hashchange事件)
展示层面也就是切换 # 后面的内容,呈现给用户不同的页面。现在越来越多的单页面应用,基本都是基于hash 实现
特性:
url中hash值的变化并不会重新加载页面hash值的改变,都会在浏览器的访问历史中增加一个记录,也就是能通过浏览器的回退、前进按钮控制hash的切换- 我们可以通过
hashchange事件,监听到hash值的变化,从而响应不同路径的逻辑处理
基于
istory新API(history.pushState()+popState事件)
window.history.pushState(null, null, "http://www.google.com");
这两个 API 的相同之处是都会操作浏览器的历史记录,而不会引起页面的刷新。不同之处在于,pushState会增加一条新的历史记录,而 replaceState 则会替换当前的历史记录
3. 防抖和节流的区别
防抖:任务频繁触发的情况下,只有任务触发的间隔超过指定间隔的时候,任务才会执行
节流:指定时间间隔内只会执行一次任务
推荐 这里
4. 页面重构怎么操作
页面重构就是根据原有页面内容和结构的基础上,通过
div+css写出符合web标准的页面结构。
具体实现要达到以下三点:
- 功能不全页面的重构:页面功能符合用户体验、用户交互结构完整,可通过标准验证,
- 代码重构:代码质量、
SEO优化、页面性能、更好的语义化、浏览器兼容、CSS优化 - 充分考虑到页面在站点中的“作用和重要性”,并对其进行有针对性的优化