MySQL主从复制介绍:使用场景、原理和实践
MySQL数据库的主从复制方案,和使用scp/rsync等命令进行的文件级别复制类似,都是数据的远程传输,只不过MySQL的主从复制是其自带的功能,无需借助第三方工具,而且,MySQL的主从复制并不是数据库磁盘上的文件直接拷贝,而是通过逻辑的binlog日志复制到要同步的服务器本地,然后由本地的线程读取日志里面的SQL语句重新应用到MySQL数据库中。
1.1.1 MySQL主从复制介绍
MySQL数据库支持单向、双向、链式级联、环状等不同业务场景的复制。在复制过程中,一台服务器充当主服务器(Master),接收来自用户的内容更新,而一个或多个其他的服务器充当从服务器(Slave),接收来自主服务器binlog文件的日志内容,解析出SQL重新更新到从服务器,使得主从服务器数据达到一致。
如果设置了链式级联复制,那么,从(slave)服务器本身除了充当从服务器外,也会同时充当其下面从服务器的主服务器。链式级复制类似A→B→C的复制形式。
1.1.2 MySQL主从复制的企业应用场景
MySQL主从复制集群功能使得MySQL数据库支持大规模高并发读写称为可能,同时有效地保护了物理服务器宕机场景的数据备份。
应用场景1:从服务器作为主服务器的实时数据备份
主从服务器架构的设置,可以大大加强MySQL数据库架构的健壮性。例如:当主服务器出现问题时,我们可以人工或设置自动切换到从服务器继续提供服务,此时从服务器的数据和宕机时的主数据库几乎是一致的。
这类似NFS存储数据通过inotify+rsync同步到备份的NFS服务器,只不过MySQL的复制方案是其自带的工具。
利用MySQL的复制功能做备份时,在硬件故障、软件故障的场景下,该数据备份是有效的,但对于人为地执行drop、delete等语句删除数据的情况,从库的备份功能就没有用了,因为从服务器也会执行删除的语句。
应用场景2:主从服务器实时读写分离,从服务器实现负载均衡
主从服务器架构可通过程序(PHP、Java等)或代理软件(mysql-proxy、Amoeba)实现对用户(客户端)的请求读写分离,即让从服务器仅仅处理用户的select查询请求,降低用户查询响应时间及读写同时在主服务器上带来的访问压力。对于更新的数据(例如update、insert、delete语句)仍然交给主服务器处理,确保主服务器和从服务器保持实时同步。
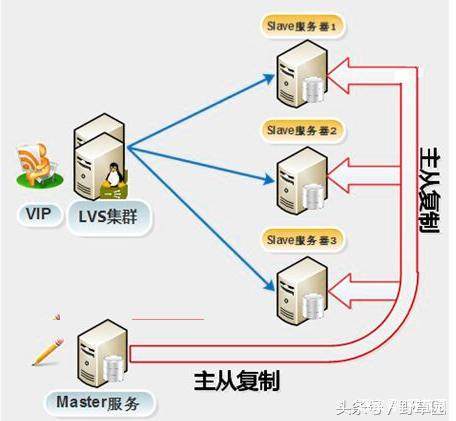
应用场景3:把多个从服务器根据业务重要性进行拆分访问
可以把几个不同的从服务器,根据公司的业务进行拆分。例如:有为外部用户提供查询服务的从服务器,有内部DBA用来数据备份的从服务器,还有为公司内部人员提供访问的后台、脚本、日志分析及供开发人员查询使用的从服务器。这样的拆分除了减轻主服务器的压力外,还可以使数据库对外部用户浏览、内部用户业务处理及DBA人员的备份等互不影响。具体可以用下图说明:
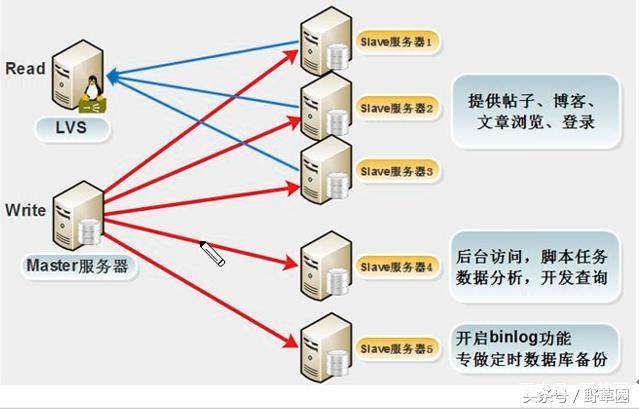
2.1 实现MySQL主从读写分离的方案
(1)通过程序实现读写分离(性能和效率最佳,推荐)
PHP和Java程序都可以通过设置多个连接文件轻松地实现对数据库的读写分离,即当语句关键字为select时,就去连接读库的连接文件,若为update、insert、delete时,则连接写库的连接文件。
通过程序实现读写分离的缺点就是需要开发人员对程序进行改造,使其对下层透明,但这种方式更容易开发和实现,适合互联网业务场景。
(2)通过开源软件实现读写分离
MySQL-proxy、Amoda、Mycat、Altas等代理软件也可以实现读写分离功能,这些软件的稳定性和功能一般,不建议生产使用。绝大多数公司常用的还是应用端开发程序实现读写分离。
(3)大型门户独立开发DAL层综合软件
百度、阿里等大型门户都有开发牛人,会花大力气开发适合自己业务的读写分离、负载均衡、监控报警、自动扩容,自动收缩等一系列功能的DAL层软件。
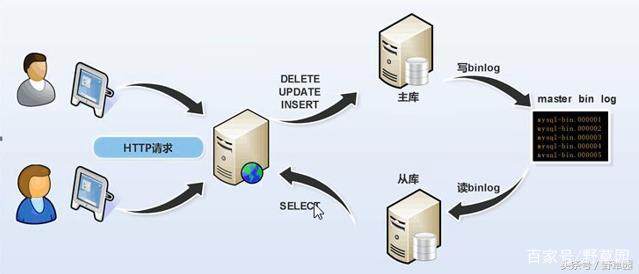
3.1 MySQL主从复制原理介绍
MySQL的主从复制是一个异步的复制过程(虽然一般情况下感觉是实时的),数据将将从一个MySQL数据库(我们称之为Master)复制到另一个MySQL数据库(我们称之为Slave),在Master于Slave之间实现整个主从复制的过程是由三个线程参与完成的。其中有两个线程(SQL和IO线程)在Slave端,另外一个线程(I/O线程)在Master端。
要实现MySQL的主从复制,首先必须打开Master端的Binlog记录功能,否则就无法实现。因为整个复制过程实际上就是Slave从Master端获取BInlog日志,然后再在Slave上以相同顺序执行获取的binlog日志中记录的各种SQL操作。
要打开MySQL的BInlog记录功能,可通过在MySQL的配置文件my.cnf中的mysqld模块增加“log-bin”参数选项来实现,具体信息如下:
[mysqld]log-bin
3.2 MySQL主从复制原理过程详细描述
下面简单描述下MySQL Replication的复制原理过程。
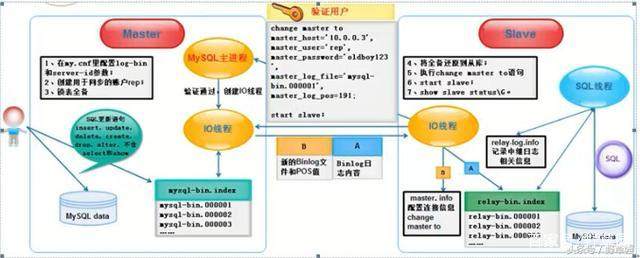
1)在Slave服务器上执行start slave命令开启主从复制开关,主从复制开始进行。
2)此时,Slave服务器的I/O线程会通过在Master上己经授权的复制用户权限请求连接Master服务器,并请求从指定Binlog日志文件的指定位罝(日志文件名和位置就是在配罝主从复制服务时执行change master命令指定的)之后开始发送Binlog日志内容。
3)Master服务器接收到来自Slave服务器的I/O线程的请求后,其上负责复制的I/O线程会根据Slave服务器的I/O线程请求的信息分批读取指定Binlog日志文件指定位置之后的Binlog日志信息,然后返回给Slave端的I/O线程。返回的信息中除了Binlog日志内容外,还有在Master服务器端记录的新的Binlog文件名称以及在新的Binlog中的下一个 指定更新位置。
4)当Slave服务器的I/O线程获取到Master服务器上I/O线程发送的日志内容及日志文件及位置点后,会将Binlog日志内容依次写入到Slave端自身的Relay Log(即中继日志) 文件(MySQL-relay-bin.xxxxxx)的最末端,并将新的Binlog文件名和位置记录到master-info文件中,以便下一次读取Master端新Binlog日志时能够告诉Master服务器需要从新Binlog 日志的指定文件及位置开始请求新的Binlog日志内容。
5)Slave服务器端的SQL线程会实时地检测本地Relay Log中I/O线程新增加的日志内容,然后及时地把Relay Log文件中的内容解析成SQL语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这些SQL语句,并记录当前应用中继日志的文件名及位置点在relay-log.info中。
经过了上面的过程,就可以确保在Master端和Slave端执行了同样的SQL语句。当复制状态正常的情况下,Master端和Slave端的数据是完全一样的。当然,MySQL的复制机制也有一些特殊情况,具体请参考官方的说明,大多数情况下,大家不用担心。
下面针对MySQL主从复制原理的重点小结
主从复制是异步的逻辑的SQL语句级的复制复制时,主库有一个I/O线程,从库有两个线程,I/O和SQL线程。作为复制的所有MySQL节点的server-id都不能相同。binlog文件只记录对数据库有更改的SQL语句(来自数据库内容的变更),不记录任何查询(select,slow)语句。
5.6 SQL多线程写入
GTID(不用找位置点了)