Transformer 的编码器和解码器
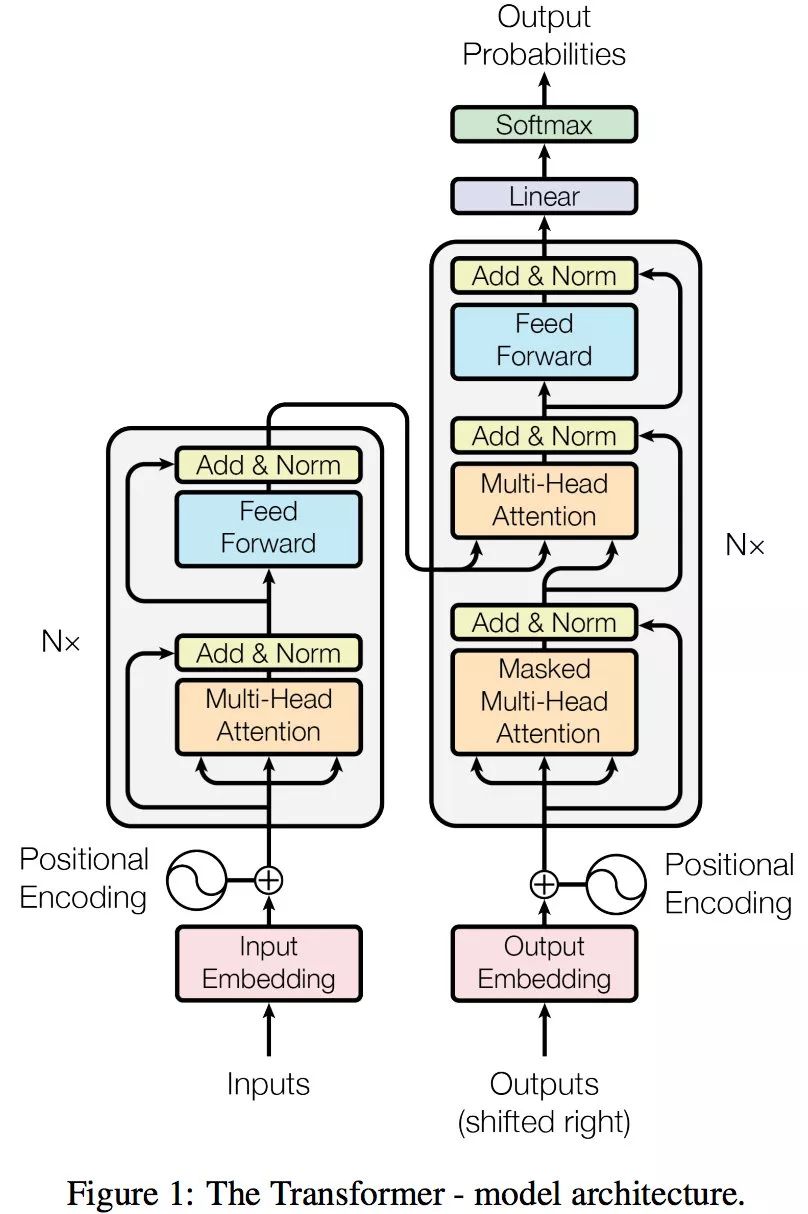
问题一:为什么 Decoder 需要做 Mask
机器翻译:源语句(我爱中国),目标语句(I love China)
为了解决训练阶段和测试阶段的 gap(不匹配)
训练阶段:解码器会有输入,这个输入是目标语句,就是 I love China,通过已经生成的词,去让解码器更好的生成(每一次都会把所有信息告诉解码器)
测试阶段:解码器也会有输入,但是此时,测试的时候是不知道目标语句是什么的,这个时候,你每生成一个词,就会有多一个词放入目标语句中,每次生成的时候,都是已经生成的词(测试阶段只会把已经生成的词告诉解码器)
为了匹配,为了解决这个 gap,masked Self-Attention 就登场了,我在训练阶段,我就做一个 masked,当你生成第一个词,我啥也不告诉你,当你生成第二个词,我告诉第一个词

问题二:为什么 Encoder 给予 Decoders 的是 K、V 矩阵
Q来源解码器,K=V来源于编码器
Q是查询变量,Q 是已经生成的词
K=V 是源语句
当我们生成这个词的时候,通过已经生成的词和源语句做自注意力,就是确定源语句中哪些词对接下来的词的生成更有作用,首先他就能找到当前生成词
我爱中国
通过部分(生成的词)去全部(源语句)的里面挑重点
Q 是源语句,K,V 是已经生成的词,源语句去已经生成的词里找重点 ,找信息,已经生成的词里面压根就没有下一个词
解决了以前的 seq2seq 框架的问题
lstm 做编码器(得到词向量 C),再用 lstm 做解码器做生成
用这种方法去生成词,每一次生成词,都是通过 C 的全部信息去生成
很多信息对于当前生成词而言都是没有意义的
用 Pytorch 去构建 Transformer 的源码()