一、第一个数据库学习报告
(1)python操作数据库读书笔记
- MongoDB
- MongoDB 是目前最流行的 NoSQL 数据库, 是一个面向文档存储的数据库,由C++语言编写,是一个基于分布式文件存储的开源数据库系统。
-
MySQLDb模块的主要方法:
commit() :提交事务。 rollback() :回滚事务。 callproc(self, procname, args):用来执行存储过程,接收的参数为存储过程名和参数列表,返回值为受影响的行数。 execute(self, query, args):执行单条sql语句,接收的参数为sql语句本身和使用的参数列表,返回值为受影响的行数。 executemany(self, query, args):执行单条sql语句,但是重复执行参数列表里的参数,返回值为受影响的行数。 nextset(self):移动到下一个结果集。 fetchall(self):接收全部的返回结果行。 fetchmany(self, size=None):接收size条返回结果行,如果size的值大于返回的结果行的数量,则会返回cursor.arraysize条数据。 fetchone(self):返回一条结果行。 scroll(self, value, mode='relative'):移动指针到某一行。如果mode='relative'则表示从当前所在行移动value条,如果 mode='absolute'则表示从结果集的第一行移动value条。
-
查询记录
import MySQLdb try: conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='test',port=3306) cur=conn.cursor() cur.execute('select * from user') cur.close() conn.close() except MySQLdb.Error,e: print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
-
插入数据
打开或创建数据库students > use students 在数据库中插入数据 > zhangsan = {'name':'Zhangsan', 'age':18, 'sex':'male'} > db.students.insert(zhangsan) > lisi = {'name':'Lisi', 'age':19, 'sex':'male'} > db.students.insert(lisi) 查询数据库中的记录 > db.students.find() 查看系统中所有数据库名称 > show dbs
import MySQLdb try: conn=MySQLdb.connect(host='localhost',user='root',passwd='root',port=3306) cur=conn.cursor() cur.execute('create database if not exists python') conn.select_db('python') cur.execute('create table test(id int,info varchar(20))') value=[1,'hi rollen'] cur.execute('insert into test values(%s,%s)',value) values=[] for i in range(20): values.append((i,'hi rollen'+str(i))) cur.executemany('insert into test values(%s,%s)',values) cur.execute('update test set info="I am rollen" where id=3') conn.commit() cur.close() conn.close() except MySQLdb.Error,e: print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
-
打开或创建数据库students > use students 在数据库中插入数据 > zhangsan = {'name':'Zhangsan', 'age':18, 'sex':'male'} > db.students.insert(zhangsan) > lisi = {'name':'Lisi', 'age':19, 'sex':'male'} > db.students.insert(lisi) 查询数据库中的记录 > db.students.find() 查看系统中所有数据库名称 > show dbs
-
Python扩展库pymongo完美支持MongoDB数据的操作
-
>>> import pymongo #导入模块 >>> client = pymongo.MongoClient('localhost', 27017) #连接数据库,27017是默认端口 >>> db = client.students #获取数据库 >>> db.collection_names() #查看数据集合名称列表 ['students', 'system.indexes'] >>> students = db.students #获取数据集合 >>> students.find() <pymongo.cursor.Cursor object at 0x00000000030934A8> >>> for item in students.find(): #遍历数据 print(item) {'age': 18.0, 'sex': 'male', '_id': ObjectId('5722cbcfeadfb295b4a52e23'), 'name': 'Zhangsan'} {'age': 19.0, 'sex': 'male', '_id': ObjectId('5722cc6eeadfb295b4a52e24'), 'name': 'Lisi'} >>> wangwu = {'name':'Wangwu', 'age':20, 'sex':'male'} >>> students.insert(wangwu) #插入一条记录 ObjectId('5723137346bf3d1804b5f4cc') >>> for item in students.find({'name':'Wangwu'}): #指定查询条件 print(item) {'age': 20, '_id': ObjectId('5723137346bf3d1804b5f4cc'), 'sex': 'male', 'name': 'Wangwu'} >>> students.find_one() #获取一条记录 {'age': 18.0, 'sex': 'male', '_id': ObjectId('5722cbcfeadfb295b4a52e23'), 'name': 'Zhangsan'} >>> students.find_one({'name':'Wangwu'}) {'age': 20, '_id': ObjectId('5723137346bf3d1804b5f4cc'), 'sex': 'male', 'name': 'Wangwu'} >>> students.find().count() #记录总数 3 >>> students.remove({'name':'Wangwu'}) #删除一条记录 {'ok': 1, 'n': 1} >>> for item in students.find(): print(item) {'name': 'Zhangsan', '_id': ObjectId('5722cbcfeadfb295b4a52e23'), 'sex': 'male', 'age': 18.0} {'name': 'Lisi', '_id': ObjectId('5722cc6eeadfb295b4a52e24'), 'sex': 'male', 'age': 19.0} >>> students.find().count() 2 >>> students.create_index([('name', pymongo.ASCENDING)]) #创建索引 'name_1' >>> students.update({'name':'Zhangsan'},{'$set':{'age':25}}) #更新数据库 {'nModified': 1, 'ok': 1, 'updatedExisting': True, 'n': 1} >>> students.update({'age':25},{'$set':{'sex':'Female'}}) #更新数据库 {'nModified': 1, 'ok': 1, 'updatedExisting': True, 'n': 1} >>> students.remove() #清空数据库 {'ok': 1, 'n': 2} >>> Zhangsan = {'name':'Zhangsan', 'age':20, 'sex':'Male'} >>> Lisi = {'name':'Lisi', 'age':21, 'sex':'Male'} >>> Wangwu = {'name':'Wangwu', 'age':22, 'sex':'Female'} >>> students.insert_many([Zhangsan, Lisi, Wangwu]) #插入多条数据 <pymongo.results.InsertManyResult object at 0x0000000003762750> >>> for item in students.find().sort('name',pymongo.ASCENDING): #对查询结果排序 print(item) {'name': 'Lisi', '_id': ObjectId('57240d3f46bf3d118ce5bbe4'), 'sex': 'Male', 'age': 21} {'name': 'Wangwu', '_id': ObjectId('57240d3f46bf3d118ce5bbe5'), 'sex': 'Female', 'age': 22} {'name': 'Zhangsan', '_id': ObjectId('57240d3f46bf3d118ce5bbe3'), 'sex': 'Male', 'age': 20} >>> for item in students.find().sort([('sex',pymongo.DESCENDING), ('name',pymongo.ASCENDING)]): print(item) {'name': 'Lisi', '_id': ObjectId('57240d3f46bf3d118ce5bbe4'), 'sex': 'Male', 'age': 21} {'name': 'Zhangsan', '_id': ObjectId('57240d3f46bf3d118ce5bbe3'), 'sex': 'Male', 'age': 20} {'name': 'Wangwu', '_id': ObjectId('57240d3f46bf3d118ce5bbe5'), 'sex': 'Female', 'age': 22}
- 创建一个数据库
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。
#创建一个数据库runoobdb
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"]
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
- MongoDB 使用数据库对象来创建集合:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"]
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
-
集合中插入文档使用 insert_one() 方法,该方法的第一参数是字典 name => value 对。
以下实例向 sites 集合中插入文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mydict = { "name": "RUNOOB", "alexa": "10000", "url": "https://www.runoob.com" } x = mycol.insert_one(mydict) print(x) print(x)
执行输出结果为:
<pymongo.results.InsertOneResult object at 0x10a34b288>
- insert_one() 方法返回 InsertOneResult 对象,该对象包含 inserted_id 属性,它是插入文档的 id 值。
import pymongo myclient = pymongo.MongoClient('mongodb://localhost:27017/') mydb = myclient['runoobdb'] mycol = mydb["sites"] mydict = { "name": "Google", "alexa": "1", "url": "https://www.google.com" } x = mycol.insert_one(mydict) print(x.inserted_id)
执行输出结果为:
5b2369cac315325f3698a1cf
注意: 如果我们在插入文档时没有指定 _id,MongoDB 会为每个文档添加一个唯一的 id。
- 集合中插入多个文档使用 insert_many() 方法,该方法的第一参数是字典列表。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mylist = [ { "name": "Taobao", "alexa": "100", "url": "https://www.taobao.com" }, { "name": "QQ", "alexa": "101", "url": "https://www.qq.com" }, { "name": "Facebook", "alexa": "10", "url": "https://www.facebook.com" }, { "name": "知乎", "alexa": "103", "url": "https://www.zhihu.com" }, { "name": "Github", "alexa": "109", "url": "https://www.github.com" } ] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值 print(x.inserted_ids)
输出结果类似如下:
[ObjectId('5b236aa9c315325f5236bbb6'), ObjectId('5b236aa9c315325f5236bbb7'), ObjectId('5b236aa9c315325f5236bbb8'), ObjectId('5b236aa9c315325f5236bbb9'), ObjectId('5b236aa9c315325f5236bbba')]
- 也可以自己指定 id,插入,以下实例我们在 site2 集合中插入数据,_id 为我们指定的:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["site2"] mylist = [ { "_id": 1, "name": "RUNOOB", "cn_name": "菜鸟教程"}, { "_id": 2, "name": "Google", "address": "Google 搜索"}, { "_id": 3, "name": "Facebook", "address": "脸书"}, { "_id": 4, "name": "Taobao", "address": "淘宝"}, { "_id": 5, "name": "Zhihu", "address": "知乎"} ] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值 print(x.inserted_ids)
输出结果为:
[1, 2, 3, 4, 5]
-
使用 find_one() 方法来查询集合中的一条数据。
查询 sites 文档中的第一条数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] x = mycol.find_one() print(x)
输出结果为:
{'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '10000', 'url': 'https://www.runoob.com'}
-
find() 方法可以查询集合中的所有数据,类似 SQL 中的 SELECT * 操作。
查找 sites 集合中的所有数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] for x in mycol.find(): print(x)
输出结果为:
{'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '10000', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'alexa': '1', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'alexa': '100', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb7'), 'name': 'QQ', 'alexa': '101', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb8'), 'name': 'Facebook', 'alexa': '10', 'url': 'https://www.facebook.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb9'), 'name': '知乎', 'alexa': '103', 'url': 'https://www.zhihu.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbba'), 'name': 'Github', 'alexa': '109', 'url': 'https://www.github.com'}
- 用 find() 方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] for x in mycol.find({},{ "_id": 0, "name": 1, "alexa": 1 }): print(x)
输出结果为:
{'name': 'RUNOOB', 'alexa': '10000'}
{'name': 'Google', 'alexa': '1'}
{'name': 'Taobao', 'alexa': '100'}
{'name': 'QQ', 'alexa': '101'}
{'name': 'Facebook', 'alexa': '10'}
{'name': '知乎', 'alexa': '103'}
{'name': 'Github', 'alexa': '109'}
注意:除了 _id 不能在一个对象中同时指定 0 和 1,如果设置了一个字段为 0,则其他都为 1,反之亦然。
以下实例除了 alexa 字段外,其他都返回:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] for x in mycol.find({},{ "alexa": 0 }): print(x)
输出结果为:
{'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb7'), 'name': 'QQ', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb8'), 'name': 'Facebook', 'url': 'https://www.facebook.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb9'), 'name': '知乎', 'url': 'https://www.zhihu.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbba'), 'name': 'Github', 'url': 'https://www.github.com'}
以下代码同时指定了 0 和 1 则会报错:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] for x in mycol.find({},{ "name": 1, "alexa": 0 }): print(x)
错误内容如下:
... pymongo.errors.OperationFailure: Projection cannot have a mix of inclusion and exclusion. ...
-
在 find() 中设置参数来过滤数据,根据指定条件查询。
以下实例查找 name 字段为 "RUNOOB" 的数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myquery = { "name": "RUNOOB" } mydoc = mycol.find(myquery) for x in mydoc: print(x)
输出结果为:
{'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '10000', 'url': 'https://www.runoob.com'}
-
对查询结果设置指定条数的记录可以使用 limit() 方法,该方法只接受一个数字参数。
以下实例返回 3 条文档记录:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myresult = mycol.find().limit(3) # 输出结果 for x in myresult: print(x)
输出结果为:
{'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '10000', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'alexa': '1', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'alexa': '100', 'url': 'https://www.taobao.com'}
- 使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。如果查找到的匹配数据多于一条,则只会修改第一条。
测试数据

将 alexa 字段的值 10000 改为 12345:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myquery = { "alexa": "10000" } newvalues = { "$set": { "alexa": "12345" } } mycol.update_one(myquery, newvalues) # 输出修改后的 "sites" 集合 for x in mycol.find(): print(x)
执行输出结果为:

update_one() 方法只能修匹配到的第一条记录,如果要修改所有匹配到的记录,可以使用 update_many()。
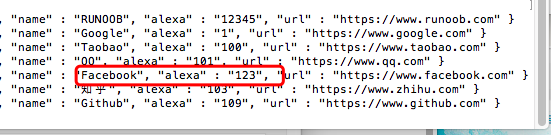
将查找所有以 F 开头的 name 字段,并将匹配到所有记录的 alexa 字段修改为 123:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myquery = { "name": { "$regex": "^F" } } newvalues = { "$set": { "alexa": "123" } } x = mycol.update_many(myquery, newvalues) print(x.modified_count, "文档已修改")
输出结果为:
文档已修改
-
sort() 方法可以指定升序或降序排序。
sort() 方法第一个参数为要排序的字段,第二个字段指定排序规则,1 为升序,-1 为降序,默认为升序。
测试数据同上
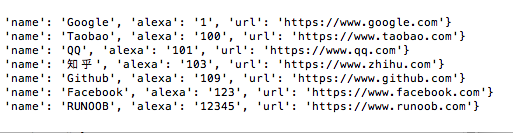
对字段 alexa 按升序排序:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mydoc = mycol.find().sort("alexa") for x in mydoc: print(x)
输出结果为:
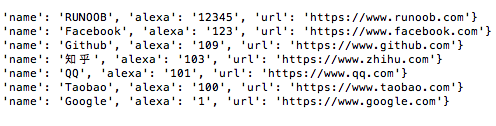
对字段 alexa 按降序排序:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mydoc = mycol.find().sort("alexa", -1) for x in mydoc: print(x)
输出结果为:
- 用 delete_one() 方法来删除一个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
测试数据同上
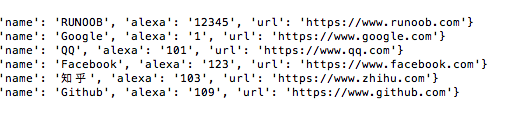
删除 name 字段值为 "Taobao" 的文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myquery = { "name": "Taobao" } mycol.delete_one(myquery) # 删除后输出 for x in mycol.find(): print(x)
输出结果为:
- 用 delete_many() 方法来删除多个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
删除所有 name 字段中以 F 开头的文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] myquery = { "name": {"$regex": "^F"} } x = mycol.delete_many(myquery) print(x.deleted_count, "个文档已删除")
输出结果为:
1 个文档已删除
- delete_many() 方法如果传入的是一个空的查询对象,则会删除集合中的所有文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] x = mycol.delete_many({}) print(x.deleted_count, "个文档已删除")
输出结果为:
5 个文档已删除
-
用 drop() 方法来删除一个集合。
删除 customers 集合:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["runoobdb"] mycol = mydb["sites"] mycol.drop()
如果删除成功 drop() 返回 true,如果删除失败(集合不存在)则返回 false。
用以下命令在终端查看集合是否已删除:
> use runoobdb
switched to db runoobdb
> show tables;
2.SQLite3
-
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,iOS和Android的App中都可以集成。 Python就内置了SQLite3。
-
表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,比如学生的表,班级的表,学校的表,等等。表和表之间通过外键关联。 要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection; 连接到数据库后,需要打开游标,称之为Cursor,通过Cursor执行SQL语句,然后,获得执行结果。 Python定义了一套操作数据库的API接口,任何数据库要连接到Python,只需要提供符合Python标准的数据库驱动即可。
- 重要的 sqlite3 模块程序
-
序号 API & 描述 1 sqlite3.connect(database [,timeout ,other optional arguments])
该 API 打开一个到 SQLite 数据库文件 database 的链接。您可以使用 ":memory:" 来在 RAM 中打开一个到 database 的数据库连接,而不是在磁盘上打开。如果数据库成功打开,则返回一个连接对象。
当一个数据库被多个连接访问,且其中一个修改了数据库,此时 SQLite 数据库被锁定,直到事务提交。timeout 参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。
如果给定的数据库名称 filename 不存在,则该调用将创建一个数据库。如果您不想在当前目录中创建数据库,那么您可以指定带有路径的文件名,这样您就能在任意地方创建数据库。
2 connection.cursor([cursorClass])
该例程创建一个 cursor,将在 Python 数据库编程中用到。该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自 sqlite3.Cursor 的自定义的 cursor 类。
3 cursor.execute(sql [, optional parameters])
该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。
例如:cursor.execute("insert into people values (?, ?)", (who, age))
4 connection.execute(sql [, optional parameters])
该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。
5 cursor.executemany(sql, seq_of_parameters)
该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。
6 connection.executemany(sql[, parameters])
该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。
7 cursor.executescript(sql_script)
该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号 ; 分隔。
8 connection.executescript(sql_script)
该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executescript 方法。
9 connection.total_changes()
该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。
10 connection.commit()
该方法提交当前的事务。如果您未调用该方法,那么自您上一次调用 commit() 以来所做的任何动作对其他数据库连接来说是不可见的。
11 connection.rollback()
该方法回滚自上一次调用 commit() 以来对数据库所做的更改。
12 connection.close()
该方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您之前未调用 commit() 方法,就直接关闭数据库连接,您所做的所有更改将全部丢失!
13 cursor.fetchone()
该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。
14 cursor.fetchmany([size=cursor.arraysize])
该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。
15 cursor.fetchall()
该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。
-
访问和操作SQLite数据时,需要首先导入sqlite3模块,然后创建一个与数据库关联的Connection对象:
import sqlite3 #导入模块 conn = sqlite3.connect('example.db') #连接数据库 # 连接到SQLite数据库 # 数据库文件是example.db # 如果文件不存在,会自动在当前目录创建:
-
成功创建Connection对象以后,再创建一个Cursor对象,并且调用Cursor对象的execute()方法来执行SQL语句创建数据表以及查询、插入、修改或删除数据库中的数据:
c = conn.cursor() # 创建表, c.execute('''CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)''') # 插入一条记录 c.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY', 'RHAT', 100, 35.14)") # 提交当前事务,保存数据 conn.commit() # 关闭数据库连接 conn.close()
-
如果需要查询表中内容,那么重新创建Connection对象和Cursor对象之后,可以使用下面的代码来查询。
for row in c.execute('SELECT * FROM stocks ORDER BY price'): print(row)
-
connect(database[, timeout, isolation_level, detect_types, factory]) :连接数据库文件,也可以连接":memory:"在内存中创建数据库。
sqlite3.Connection.execute():执行SQL语句
sqlite3.Connection.cursor():返回游标对象
sqlite3.Connection.commit():提交事务
sqlite3.Connection.rollback():回滚事务
sqlite3.Connection.close():关闭连接
-
在sqlite3连接中创建并调用自定义函数:
import sqlite3 import hashlib # 自定义Python函数 def md5sum(t): return hashlib.md5(t).hexdigest() # 在内存中创建临时数据库 conn = sqlite3.connect(":memory:") # 创建可在SQL调用的函数,其中第二个参数表示函数的参数个数 conn.create_function("md5", 1, md5sum) cur = conn.cursor() # 在SQL语句中调用自定义函数 cur.execute("select md5(?)", ["中国山东烟台".encode()]) print(cur.fetchone()[0])
-
Cursor对象常用方法:
close(...): 关闭游标
execute(...):执行SQL语句
executemany(...):重复执行多次SQL语句
executescript(...):一次执行多条SQL语句
fetchall(...):从结果集中返回所有行记录
fetchmany(...): 从结果集中返回多行记录
fetchone(...):从结果集中返回一行记录
-
execute(sql[, parameters]):该方法用于执行一条SQL语句,下面的代码演示了用法,以及为SQL语句传递参数的两种方法,分别使用问号和命名变量作为占位符。
import sqlite3 conn = sqlite3.connect(":memory:") cur = conn.cursor() cur.execute("CREATE TABLE people (name_last, age)") who = "Dong" age = 38 # 使用问号作为占位符 cur.execute("INSERT INTO people VALUES (?, ?)", (who, age)) # 使用命名变量作为占位符 cur.execute("SELECT * FROM people WHERE name_last=:who AND age=:age", {"who": who, "age": age}) print(cur.fetchone())
executemany(sql, seq_of_parameters):该方法用来对于所有给定参数执行同一个SQL语句,参数序列可以使用不同的方式产生。
-
使用迭代来产生参数序列:
import sqlite3 # 自定义迭代器,按顺序生成小写字母 class IterChars: def __init__(self): self.count = ord('a') def __iter__(self): return self def __next__(self): if self.count > ord('z'): raise StopIteration self.count += 1 return (chr(self.count - 1),) conn = sqlite3.connect(":memory:") cur = conn.cursor() cur.execute("CREATE TABLE characters(c)") # 创建迭代器对象 theIter = IterChars() # 插入记录,每次插入一个英文小写字母 cur.executemany("INSERT INTO characters(c) VALUES (?)", theIter) # 读取并显示所有记录 cur.execute("SELECT c FROM characters") print(cur.fetchall())
-
使用生成器对象来产生参数:
import sqlite3 import string # 包含yield语句的函数可以用来创建生成器对象 def char_generator(): for c in string.ascii_lowercase: yield (c,) conn = sqlite3.connect(":memory:") cur = conn.cursor() cur.execute("CREATE TABLE characters(c)") # 使用生成器对象得到参数序列 cur.executemany("INSERT INTO characters(c) VALUES (?)", char_generator()) cur.execute("SELECT c FROM characters") print(cur.fetchall())
-
使用直接创建的序列作为SQL语句的参数:
import sqlite3 persons = [("Hugo", "Boss"), ("Calvin", "Klein") ] conn = sqlite3.connect(":memory:") # 创建表 conn.execute("CREATE TABLE person(firstname, lastname)") # 插入数据 conn.executemany("INSERT INTO person(firstname, lastname) VALUES (?, ?)", persons) # 显示数据 for row in conn.execute("SELECT firstname, lastname FROM person"): print(row) print("I just deleted", conn.execute("DELETE FROM person").rowcount, "rows")
-
fetchone()、fetchmany(size=cursor.arraysize)、fetchall():用来读取数据。假设数据库通过下面代码插入数据:
import sqlite3 conn = sqlite3.connect("D:/addressBook.db") cur = conn.cursor() #创建游标 cur.execute('''INSERT INTO addressList(name , sex , phon , QQ , address) VALUES('王小丫' , '女' , '13888997011' , '66735' , '北京市' )''') cur.execute('''INSERT INTO addressList(name, sex, phon, QQ, address) VALUES('李莉', '女', '15808066055', '675797', '天津市')''') cur.execute('''INSERT INTO addressList(name, sex, phon, QQ, address) VALUES('李星草', '男', '15912108090', '3232099', '昆明市')''') conn.commit() #提交事务,把数据写入数据库 conn.close()
-
使用fetchall()读取数据:
import sqlite3 conn = sqlite3.connect('D:/addressBook.db') cur = conn.cursor() cur.execute('SELECT * FROM addressList') li = cur.fetchall() #返回所有查询结果 for line in li: for item in line: print(item, end=' ') print() conn.close()
-
使用fetchone()方法读取其中数据:
conn.row_factory = sqlite3.Row c = conn.cursor() c.execute('SELECT * FROM stocks') r = c.fetchone() print(type(r)) print(tuple(r)) print(r[2]) print(r.keys()) print(r['qty']) for field in r: print(field)
- 连接到一个现有的数据库。如果数据库不存在,那么它就会被创建,最后将返回一个数据库对象。
import sqlite3 conn = sqlite3.connect('test.db') print "Opened database successfully"
可以把数据库名称复制为特定的名称 :memory:,这样就会在 RAM 中创建一个数据库。
运行上面的程序,在当前目录中创建我们的数据库 test.db。
可以根据需要改变路径。保存上面代码到 sqlite.py 文件中,并按如下所示执行。如果数据库成功创建,那么会显示下面所示的消息:
$chmod +x sqlite.py $./sqlite.py Open database successfully
- 在先前创建的数据库中创建一个表:
import sqlite3 conn = sqlite3.connect('test.db') print "Opened database successfully" c = conn.cursor() c.execute('''CREATE TABLE COMPANY (ID INT PRIMARY KEY NOT NULL, NAME TEXT NOT NULL, AGE INT NOT NULL, ADDRESS CHAR(50), SALARY REAL);''') print "Table created successfully" conn.commit() conn.close()
上述程序执行时,它会在 test.db 中创建 COMPANY 表,并显示下面所示的消息:
Opened database successfully
Table created successfully
- 在上面创建的 COMPANY 表中创建记录:
import sqlite3 conn = sqlite3.connect('test.db') c = conn.cursor() print "Opened database successfully" c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Paul', 32, 'California', 20000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Allen', 25, 'Texas', 15000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )") c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )") conn.commit() print "Records created successfully" conn.close()
上述程序执行时,它会在 COMPANY 表中创建给定记录,并会显示以下两行:
Opened database successfully
Records created successfully
- 从前面创建的 COMPANY 表中获取并显示记录:
import sqlite3 conn = sqlite3.connect('test.db') c = conn.cursor() print "Opened database successfully" cursor = c.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], " " print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
- 用 UPDATE 语句来更新任何记录,然后从 COMPANY 表中获取并显示更新的记录:
import sqlite3 conn = sqlite3.connect('test.db') c = conn.cursor() print "Opened database successfully" c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1") conn.commit() print "Total number of rows updated :", conn.total_changes cursor = conn.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], " " print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully Total number of rows updated : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 25000.0 ID = 2 NAME = Allen ADDRESS = Texas SALARY = 15000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
- 使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余的记录:
import sqlite3 conn = sqlite3.connect('test.db') c = conn.cursor() print "Opened database successfully" c.execute("DELETE from COMPANY where ID=2;") conn.commit() print "Total number of rows deleted :", conn.total_changes cursor = conn.execute("SELECT id, name, address, salary from COMPANY") for row in cursor: print "ID = ", row[0] print "NAME = ", row[1] print "ADDRESS = ", row[2] print "SALARY = ", row[3], " " print "Operation done successfully" conn.close()
上述程序执行时,它会产生以下结果:
Opened database successfully Total number of rows deleted : 1 ID = 1 NAME = Paul ADDRESS = California SALARY = 20000.0 ID = 3 NAME = Teddy ADDRESS = Norway SALARY = 20000.0 ID = 4 NAME = Mark ADDRESS = Rich-Mond SALARY = 65000.0 Operation done successfully
(2)