* 若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。
* 对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称冲突。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数H(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。这个现象也叫散列桶,在散列桶,只能通过顺序的方式来查找,一般只需要查找三次就可以找到。科学家计算过,当重载因子不超过75%,查找效率最高。
* 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。
实际工作中需视不同的情况采用不同的哈希函数,通常考虑的因素有:
· 计算哈希函数所需时间
· 关键字的长度
· 哈希表的大小
· 关键字的分布情况
· 记录的查找频率
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做自身函数)。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。
2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3. 平方取中法:取关键字平方后的中间几位作为散列地址。
4. 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
5. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
哈希表类的实现
#include "stdafx.h"
#include <iostream>
#include <iomanip>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include<time.h>
using namespace std;
//user data stored in hash table
typedef struct
{int stuff; //optional related data
}recType;
typedef int hashIndexType; //index into hash table
#define compEQ(a,b) (a == b)
//implementation independent declarations
typedef enum {
STATUS_OK,
STATUS_MEM_EXHAUSTED,
STATUS_KEY_NOT_FOUND
}statusEnum;
typedef struct nodeTag {
struct nodeTag *next; // next node
int key; // key
recType rec; // user data
}nodeType;
nodeType **hashTable;
int hashTableSize;
//哈希表的插入
statusEnum insert(int key, recType *rec) {
nodeType *p,*p0;
hashIndexType bucket;
//insert node at beginning of list
bucket=key%hashTableSize;
if((p=new nodeType )==0)
return STATUS_MEM_EXHAUSTED;
p0 = hashTable[bucket];
hashTable[bucket] = p;
p->next = p0;
p->key = key;
p->rec = *rec;
return STATUS_OK;
}
//哈希表的删除
statusEnum Delete(int key) {
nodeType *p0, *p;
hashIndexType bucket;
p0 = 0;//find node
bucket=key%hashTableSize;
p = hashTable[bucket];
while (p&&!compEQ(p->key,key))
{p0 = p;
p = p->next;}
if (!p) return STATUS_KEY_NOT_FOUND;
//p designates node to delete,remove it from list
if(p0)
//not first node,p0 points to previous node
p0->next=p->next;
else
//first node on chain
hashTable[bucket] = p->next;
free (p);
return STATUS_OK;
}
//哈希表的查找
statusEnum find(int key, recType *rec)
{ nodeType *p;
p = hashTable[key%hashTableSize];
while (p && !compEQ(p->key, key))
p = p->next;
*rec = p->rec;
return STATUS_OK;
}哈希表的调用
//哈希表的相关操作的测试
void main()
{cout<<"运行结果:\n";
int i, maxnum,k=0;
recType *rec;
int *key;
statusEnum err;
maxnum = 10;
hashTableSize =10;
srand(time(0));
if((rec =new recType [maxnum*sizeof(recType)])==0) {
fprintf (stderr, "out of memory (rec)\n");exit(1);}
if((key =new int [maxnum*sizeof(int)])==0)
{fprintf (stderr, "out of memory (key)\n");exit(1);}
if((hashTable=new nodeType *[hashTableSize*sizeof(nodeType)])==0)
{fprintf(stderr,"out of memory (hashTable)\n");exit(1);}
if(rand()) {//fill "key" with unique rand numbers
for(i=0;i<maxnum;i++) key[i]=rand()%100;
cout<<" ran ht,"<<maxnum<<" items,"<<hashTableSize<<" hashTable\n";
}else{
for(i=0;i<maxnum;i++) key[i]=i;
cout<<" seq ht,"<<maxnum<<" items,"<<hashTableSize<<" hashTable\n";
}
cout<<"插入结果\n";
for(i = 0,k=1; i < maxnum; i++,k++) {
err=insert(key[i],&rec[i]);
if(!err)//插入成功
cout<<" key["<<setw(2)<<i<<"]="<<setw(3)<<key[i];
if(k%5==0) cout<<endl;
}
cout<<endl<<"查找结果\n";
for(k=1,i = maxnum-1;i>=0;i--,k++) {
err=find(key[i],&rec[i]);
if(!err)//查找成功
cout<<" key["<<setw(2)<<i<<"]="<<setw(3)<<key[i];
if(k%5==0) cout<<endl;
}
cout<<endl<<"删除结果\n";
for(k=1,i=maxnum-1;i>=0;i--,k++) {
err=Delete(key[i]);
if(!err)//删除成功
cout<<" key["<<setw(2)<<i<<"]="<<setw(3)<<key[i];
if(k%5==0) cout<<endl;
}
cin.get();}
效果
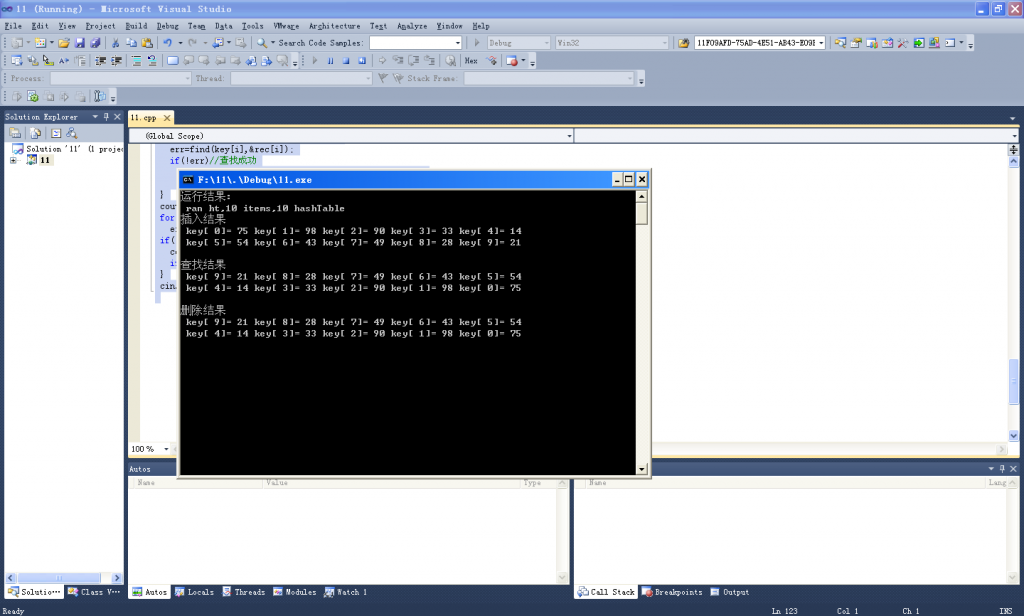
代码下载地址