小爬最近随着对python中字符串、json等理解进一步加深,发现先前我随笔中提到的data构造和传参方法略复杂,原本有更简单的方法,Mark如下。
先前小爬我使用的requests.post请求中data构造的代码如下:
data_search={ 'page':1, 'rows':15, 'condition': """[ {"column":"BPM_DEF_NAME","exp":"like","value":""}, {"column":"DELETE_STATUS","exp":"=","value":0}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":">=","value":"YYYY-MM-DD"}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":"<=","value":"YYYY-MM-DD"}, {"column":"CHECK_TYPE","exp":"like","value":"2"}, {"column":"LOCKED_STATUS","exp":"=","value":0}, {"column":"DELETE_STATUS","orderType":"default","orderKey":"","direction":"ASC"} ]""", #考虑到该字段已经有单引号、双引号,所以只能用三引号来包住这部分代表字符串 'additionalParams':'{}' } data_search_condition=json.loads(data_search['condition']) #将字符串转为列表,方便更新列表(列表中每个元素都是一个单个字典)元素 #刷新字典 data_search_condition[0]['value']=businessName data_search_condition[2]['value']=str(startDate) data_search_condition[3]['value']=str(endDate) data_search['condition']=json.dumps(data_search_condition) #将列表重新转回字符串,作为data_search字典中键“condition”对应的“value”,然后更新字典
该方法主要通过json的dumps、loads方法来完成“字符串→字典列表→列表或字典值更新→字典、列表转回str字符串”,代码复杂且可读性差。
后细想下,上面的代码中红色部分(即data_search['condition']对应值)看上去,既有单引号、双引号、也有三引号,但其作为整体,本质上就是三引号包着的字符串,所以原则上它可以使用字符串的传参方法来载入变量,于是代码可以改为:
data_search={ 'page':1, 'rows':15, 'condition': """[ {"column":"BPM_DEF_NAME","exp":"like","value":"%s"}, {"column":"DELETE_STATUS","exp":"=","value":0}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":">=","value":"%s"}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":"<=","value":"%s"}, {"column":"CHECK_TYPE","exp":"like","value":"2"}, {"column":"LOCKED_STATUS","exp":"=","value":0}, {"column":"DELETE_STATUS","orderType":"default","orderKey":"","direction":"ASC"} ]"""%(businessName,str(startDate),str(endDate)), 'additionalParams':'{}' }
再次证明编程达到目的的方法远不止一次,但是各种方法之间在可读性、性能、复杂度上却存有差别。小爬也是告诫自己,永远要本着化繁为简的思想去编程。
另外,小爬我给部门同事制作了一个内网数据爬取到excel的小工具,其中需要用到python中网页附件的下载、excel存储、txt存储,excel超链接生成等功能,经过摸索,终于搞定!
主要思路是,post请求(参数:“编号”)得到json文件,将json中主要字段存储到列表中,取出“附件”字段值,再去表单主页面源码中看“附件”的url,进而构造出对应的附件url地址。略去不表,下面重点讲如何下载附件、判断服务器中附件的名称和文件后缀等。
判断文件名和后缀的代码如下:
#定义fileType方法,得到文件类型 def get_fileType(response): #fileType=response.headers['Content-Type'] # image/jpeg;charset=UTF-8 #Content-Type: application/pdf;charset=UTF-8 fileType=response.headers['Content-Disposition'] #Content-Disposition: attachment; filename=%E6%9C%96%B0%E8%90%A5%E4%B8%9A%E6%89%A7%E7%85%A7.pdf #fileType=re.search(".*?/(.*?);.*?",fileType) fileType=os.path.splitext(fileType)[-1][1:].lower() return fileType
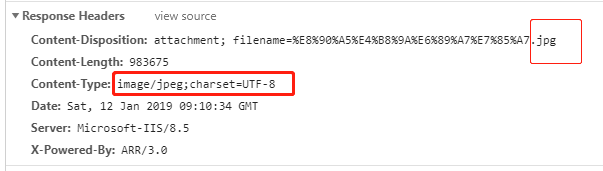
可以看到我们请求附件对应的url地址时,服务器返回的Response Headers头文件中,Content-Disposition和Content-Type字段能看到文件名和后缀,需要注意的是,实际使用时,小爬发现Content-Type字段并不总是存在,此时可能需要使用try……except方法对两个字段进行尝试,提升程序的容错能力。
下载附件、写入excel并生成超链接用到的示例代码如下:
小爬再说说制作简易进度条这件事儿:如果我们要制作很酷炫、多功能的GUI用户界面,当然首选pyqt5、wxPython、tkinter等著名GUI库。但是笔者如果只是想把脚本封装为exe,给一般用户使用,只是需要一个简单的进度提醒,如果对美观等没有特别的要求,则用Selenium+js的方法更容易实现。
小爬我的爬虫工具首先用selenium的driver方法打开了浏览器,之后的爬取过程,都是尽可能调用requests方法,此时网页并不会跟着刷新。原始的网页左上角如下图所示:

小爬通过selenium载入js的方法,可以更改“抽查记录信息”这个div标签在本地浏览器显示的文本为“我想要输出的进度信息”,且不会对服务器造成任何变化。巧妙达到制作进度的要求。
该div的html信息,可以通过查询网页源码得到:“<div class="haf-form-title">抽查记录信息</div>”,那么让这个页面元素对应的文本更改需要的代码很简单,先用querySelector方法定位,再更改attr属性,示例代码如下:
driver.execute_script('document.querySelector("div.haf-form-title").textContent="%s 已完成%d行数据."'%(name,Num))
是的,这行代码足够显示基本的进度了,你可以传入更多参数来显示总数、实时计数和百分比等,灵活运用该方法即可。实际效果如下:

方法很多,我们只要做到“活学活用”即可!
