开篇题
这个系列的文章主要参考cs229课程的内容,按照自己的思路和其他课程与书籍方式梳理下来,可能顺序和内容都与cs229有点不一样,但是参考内容我都会附在最后。而且这个系列主要讲个人的理解不想太多堆公式,公式的话随便看看就好。
所以我会说很多啰嗦话来解释我们为什么找到这么个东西来描述这么个事情而不是罗列公式,所以会省略很多公式上的细节。有需要的话可以翻一翻后面列的参考资料。
最后,配合原版课程食用更佳。
符号说明
进入正题之前先说明一下符号体系,因为不同书籍和课程用的符号体系可能不同,本系列笔记会cs229和NG使用的符号体系保持一致。
机器学习简介
机器学习的基本组成
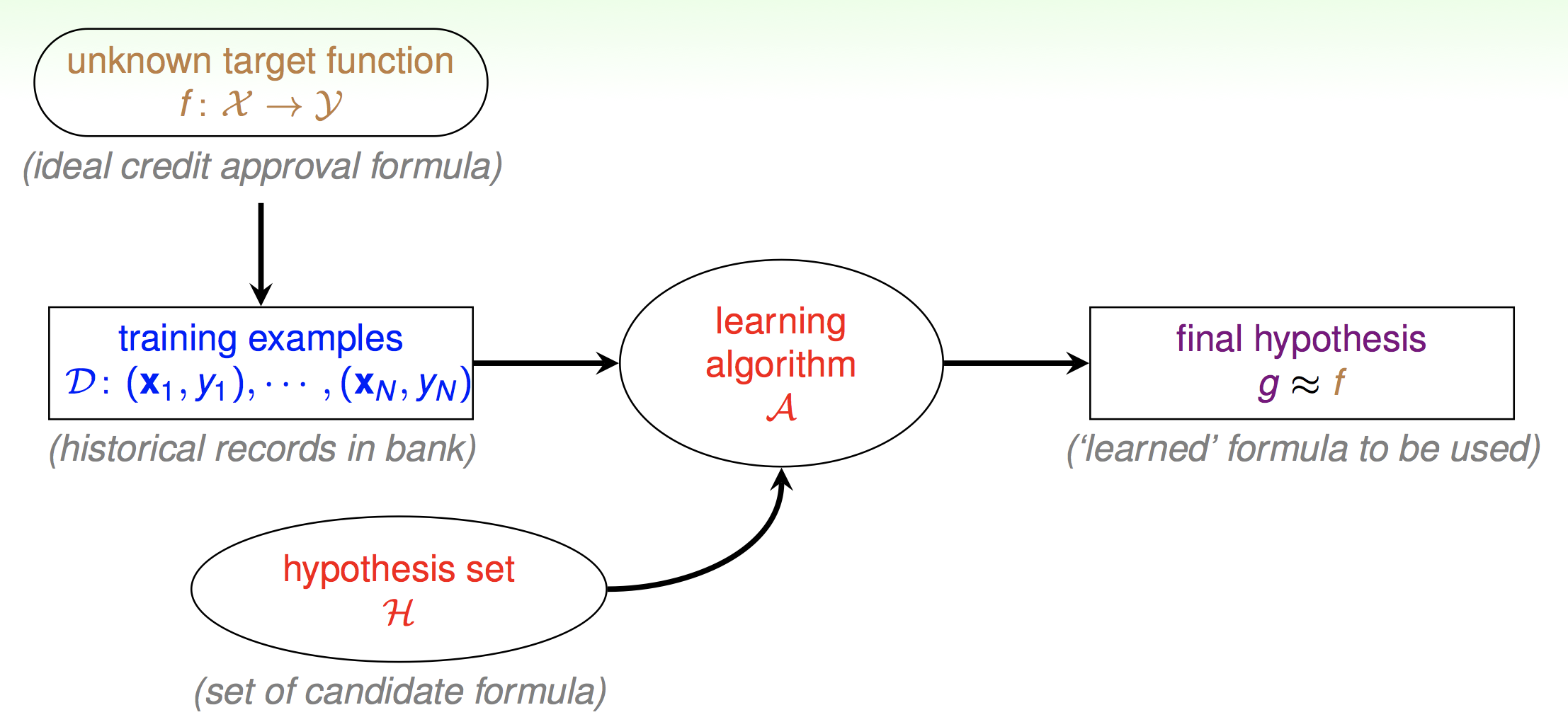
从统计机器学习的角度来说,这里存在了一个未知的分布f反应了从X空间到Y空间的正确的映射。我们无法直接得到这样的映射,但可以通过一些方法间接得到样本。那么学习算法A的作用就是从假设集合H里面得到一个比较好能反应X到Y的拟合映射g。
线性回归
问题背景
先来构造一个具体的问题:

房价预测:如果给你房间面积和价格得到一个条合适直线预测单位面积的房价。
术语化描述就是给定一些x,y的样本集,x为任意维样本,y为标签。那么在给定任意x的情况下如何预测y。即:
我们以后都会用这样的方式来描述样本集。
构造假设
由于我们并不知道真实的映射,所以需要用一个假设的映射来代替,再来印证这个假设的正确与否。
我们暂且认为这些点可以用一条直线来拟合,而且与房子面积相关,再加上一个截距项,这个截距项我们一般称之为偏置项。那么在二维的平面上假设函数就是:
如果有n个影响房价的变量,我们可以把假设函数推广到n维并表示成向量形式:
这里有一个容易弄错的点稍微提一下,有的资料会把( heta^Tx)形式写成(w^Tx+b)的形式。主要的区别就是我们把偏置项也写入了向量里面,一般以( heta_0)表示偏置项。所以x向量也要多一项(x_0)出来而且恒等于1,以便向量相乘的时候表示偏置项。
误差衡量
那么得到了假设之后我们需要衡量假设映射和真实映射之间差距。也就是让样本的标签与预测的结果比较,而且差距越小越好。
那么如何计算这样的差距呢,我们需要一个具体的量来衡量我们这条假设的线的好坏。最简单的想法就是让线穿过所有的点,但因为会有各种误差的存在,只要点的数量足够多,这条线明显是不可能穿过所有点的。点在直线上,我们认为直线拟合地好,所以容易想到那些偏离直线的点,我们就算作是和真实映射之间的差距了。我们把这些差距求和就得到了:
这个衡量误差的函数一般称之为损失函数或者成本函数。(underset{ heta}{operatorname{argmin}})表示求参数θ使得J(θ)最小。
于是找到一条直线拟合这些点的问题就变成了求解向量θ使得这个J(θ)函数最小的问题了。
求解问题
那么如何求解这个问题呢。最直接的方法是穷举所以可能的向量θ的值找到一个使得损失函数最小的向量θ。虽然这种方法不可行但也提供了一种重要的思路,那就是迭代法求解。
因为如果我们只有一个点,那么任意经过这个点的直线的都能拟合。如果有两个那么存在一条直线完全拟合。只要有三个点以上那么直线会越来越难拟合这些点。一般机器学习的数据量都会很大,我们并不会考虑直接求解答案而是通过某一种迭代的方法一点一点求出解来。但是这个问题确实可以得到一个解析解。后面的参考中会给出。但是还是那个道理,机器学习问题数据量一般都非常大,我们只考虑迭代解。
那么回到原来的问题上来,从形式上看这是个关于向量θ的函数。或者理解成关于( heta_j)的多变量函数。我们想让J(θ)最小,就可以让J(θ)对每个分量求导。那么就是对θ求梯度,梯度指向了改变θ使得J(θ)上升最快的方向。那么让θ沿着反梯度方向下降即可。
迭代算法如下:
这个算法叫梯度下降,α是下降的速率,一般称之为学习速率。
注意:这个α如果设置太大可能会导致迭代无法收敛,太小可能会导致下降过慢。
具体梯度的计算过程如下:
带入梯度算子可得:
得到这么个更新规则之后我们就可以让这个算法一直运行直到收敛,即更新出来的θ和原本的θ之差小于一定的值时。
这张等高线图显示了θ是如何下降的。
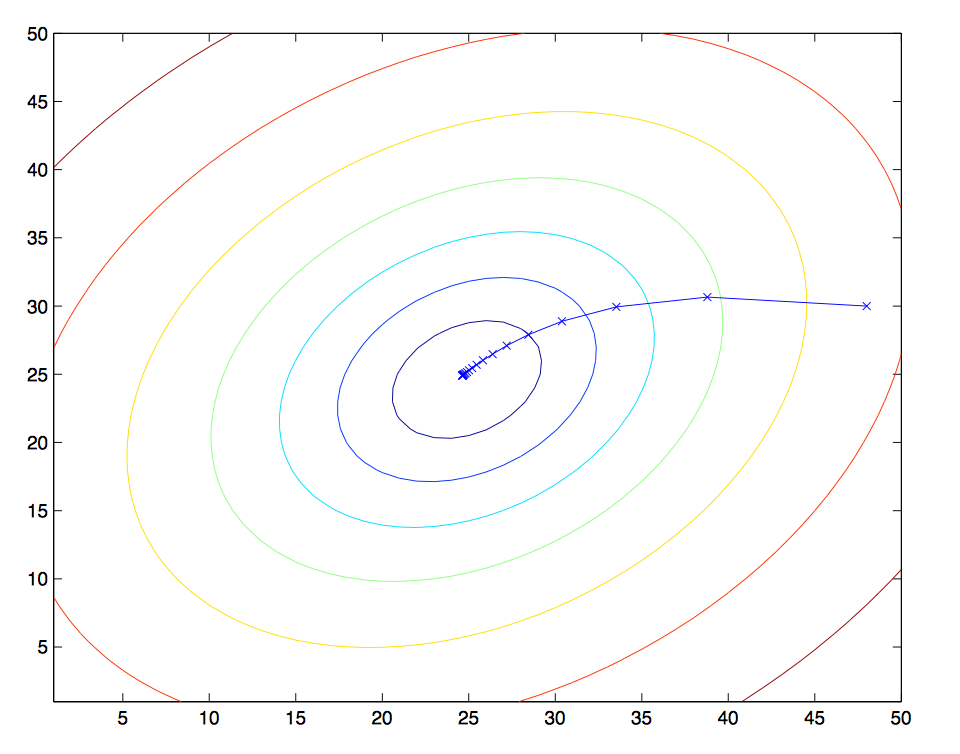
关于梯度下降还有一个类似的算法叫随机梯度下降,因为上面的梯度计算中每次更新θ我们都把所有的样本都算了一遍,如果样本数量特别大的时候这种计算开销是很大的。我们可以只选几个样本来计算梯度。
对于梯度下降我们其实可以换一种方式来理解,如果我们想求一个函数的极值,一般来说直接求导就行了。但是对于复杂函数而言,我们很难求导。那么高数中我们学过,可以用泰勒展开来拟合一个复杂的函数。其实梯度下降对应的就是一阶的泰勒展开。
感知机
问题背景
上面那种直线拟合问题我们一般称之为回归问题。但是如果我有这样一个问题:假定我给你关于房子的一些参数,那么你如何判断这间房子是一线的地区的房子还是二线地区的房子呢。也就是我想把样本进行分类。
或者从图形上来理解,回归任务是找到一条线尽量拟合点,而分类任务是找到一条线尽量把点分开。
这个算法就是最简单的分类算法。
样本集描述:
构造假设
我们先回忆一下线性回归的假设函数:
我们可以认为x是房子的参数,θ是这些参数在房价中占的比重,那么h(x)就是房价了。那么再假设房价大于等于100w就是一线城市,小于100w就是二线城市。这样就构造了一个二分类问题。
于是我们的假设函数就是:
误差衡量
还是回到之前的线性回归的例子中来,线性回归中我们的损失函数是由点到直线的距离,这样的误差累加得到的。那么在分类问题中我们损失就是那些本应该被分到1类的点被分到了0类和本应该被分到0类的问题被分到了1类。那么损失函数就为:
这个问题很难求解,如果你对复杂度有清晰的认知的话,这是个NP难问题。如果你不能理解计算复杂度的话,那么你可以理解为这是一个除了穷举以外基本不能求解的问题。所以我们需要稍微改变一下形式:
最后那个减100w的操作其实是对分段函数的一个平移操作,为了使得被误分类的点的(y^{(i)}( heta^Tx^{(i)})都为负值。
求解问题
与之前的线性回归同理,我们对损失函数求导可以得到,然后对误分类的点进行下降。
至于这个函数的收敛性,我会在后面参考中给出。
逻辑回归
问题背景
前面那个判断房价的例子里面我们只是做了一个简单的假设,大于100w一定等于是一线城市了,小于100w一定是二线城市的。但是实际上并不是这样的,感知机那种分类方式只能说是硬分类,或者从概率论角度比较准确的理解的话,大于等于100w我们只能说是一线城市房子的概率比较高而不是一定是,这就是一种软分类的思想。于是接下来我们会从概率论角度重新构造之前那个分类问题。
样本集描述:
构造假设
既然是求概率,我们需要把之前感知机得到的那个量即( heta^Tx)映射到一个[0,1]的区间上。而且这个函数最好单调连续以便我们后面求导求解问题。
于是有:
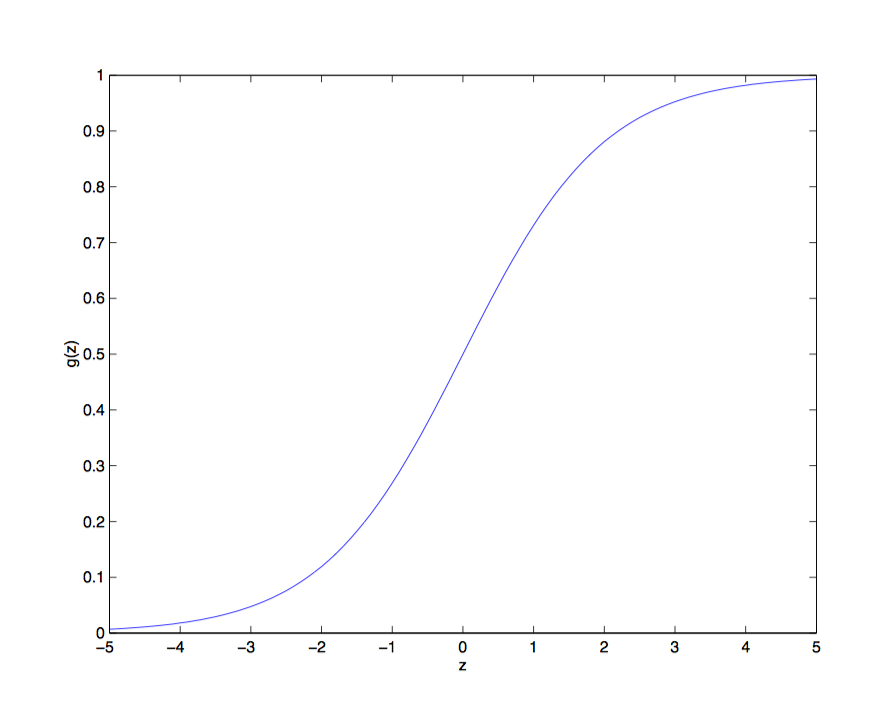
这个函数我们一般称之为Logistic函数或者sigmoid函数,至于为什么要用到这个函数,后面推广义线性模型的时候会说到。
它的性质很好,趋向于无穷大的值被映射到了1,趋向性负无穷大则被映射到了0,然后我们可以以0.5作为阈值,大与等于0.5为一类,小于则为另一类。
于是新的假设函数就为:
因为一类的概率等于一减另一类的概率那么就有:
其实这就是伯努利分布,合并一下就有:
误差衡量
我们之前是用预测值与样本值做差并平方来描述误差一个样本的误差,最后把各个样本的误差相加,并求解那个使得总误差最小的θ。假设函数已经给出了一个样本标签在样本值下出现的概率。那么我们把所有样本值在其标签下出现的概率相乘求一个联合概率,并使这个联合概率最大的θ即可。
这里我们为了形式上的一致,加个负号求值最小。
这个函数统计学上叫似然函数,那么问题就转化为求解这个函数最大,即最大似然法。
求解问题
还是和之前一样对这个函数求导。但是这里要用点小技巧,因为这里是一个累积的形式并不好求导,所以我们可以对似然函数求对数变成一个累加的函数就好求导了。于是有对数似然函数:(l( heta)=logL( heta))
具体求导过程如下:
带入梯度算子最终得到迭代解:
多元回归
问题背景
房子可能是一线或者二线的,那么为什么不可能是三线或者四线甚至一百线的呢。所以讲完了二元的回归问题,我们再来说说多元的分类的问题。
样本集描述:
构造假设
这里的我们要把y当做向量来考虑了,那我们假设函数也应该输出一个向量,每个分量是x是这个标签的概率。
那么和之前的二元分类一样,我们首先要找到一个函数把( heta^Tx)映射到[0,1]区间,并且使得各个分量的和为1。
于是我们先直接给出softmax函数。后面的参考会给出为什么要用这个函数。
于是有:
我们的假设函数就变成了:
这里每个不同的分类都有不同的权重向量θ。
误差衡量
这里引入一个符号:
对假设函数求对数似然:
求解问题
同理,梯度下降求解θ,得到的梯度算子为:
之前提到了每个分类都有一个向量θ,所以这里求的( heta_j)还是向量跟前面的逻辑回归不一样。求第(l)个元素还要求一次梯度即(frac{delta l( heta)}{delta heta_{jl}})。这里就不写了。
把梯度算子带入之前的迭代算法就就可以了。
小结
这里其实很容易看出有监督学习的基本套路,那就是构造假设,衡量误差,优化求解这么个过程。
为了直线拟合我们有线性回归,硬分类感知机,软分类逻辑回归,多元分类softmax回归。
参考
- 线性回归的解析解
cs229-note1 p7
- 对于感知机迭代求解算法的收敛性
《统计学习方法》-李航 p31
- 为什么要使用sigmoid和softmax函数作为[0,1]区间上的映射函数
- 以及什么样的问题可以映射到线性模型上解决
cs229-note1 p22-p26 有一个从广义线性模型上的说明