工作需要写一个程序调用菜鸟物流云五级地址查询api,此处决定用python实现。

调用实例如图:
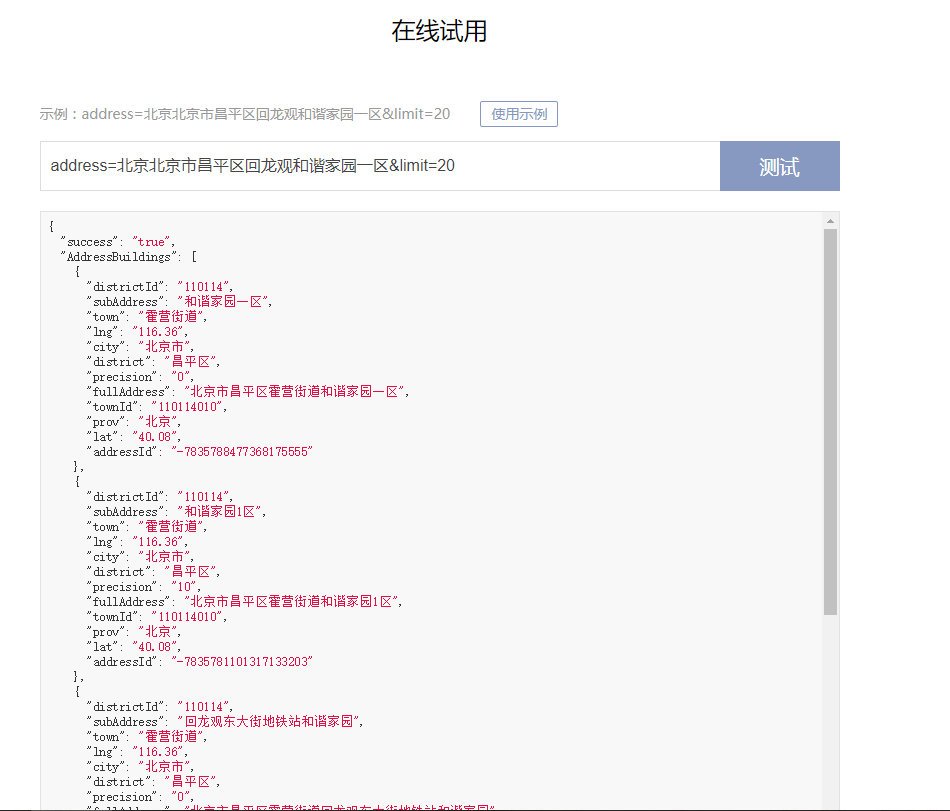
接口文档:
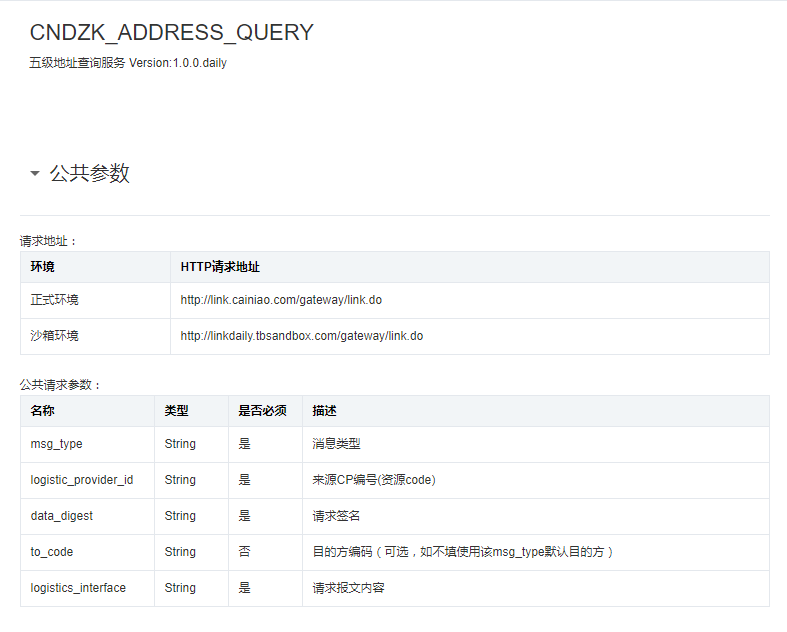
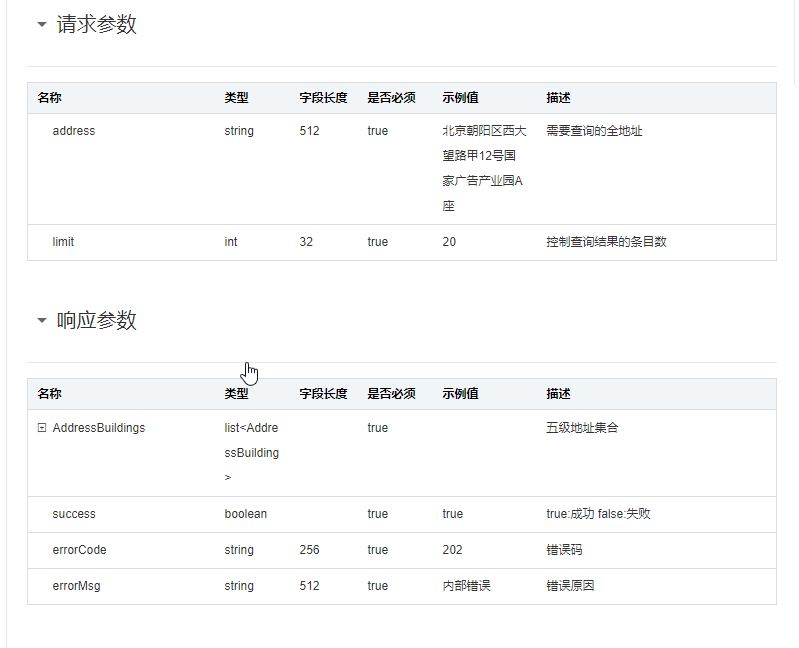
先申请获得appkey与resourceid:
需要查询的数据集:
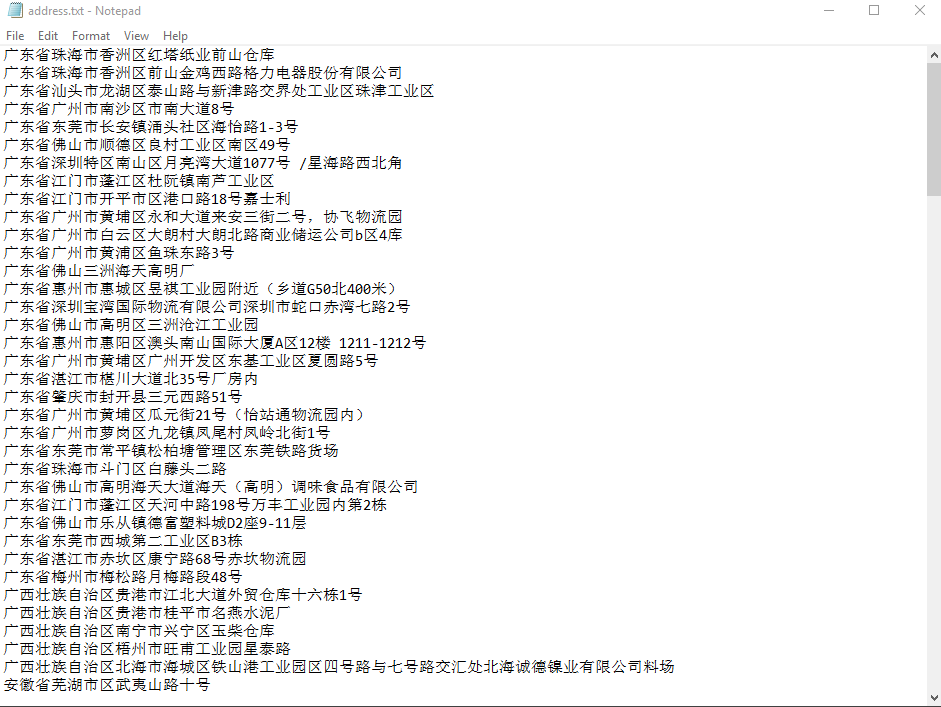
读取文件存入一个list:
1 def get_address(): 2 try: 3 with open(os.getcwd() + r'address.txt', 'r') as f: 4 address = f.readlines() 5 return address 6 except: 7 print('打开文件失败') 8 return ''
构造请求参数:
1 def get_raw_input(address): 2 raw_input = { 3 "address": address, 4 "limit": "20" 5 } 6 return raw_input
构造公共请求参数:
1 def get_param(sign, content): 2 param = { 3 'msg_type': 'CNDZK_ADDRESS_QUERY', 4 'data_digest': sign, 5 'logistic_provider_id': 'd0119848ab......e1df5d8d6dc149', 6 'logistics_interface': content 7 } 8 return param
计算请求签名(MD5值算法与base64编码):
1 def get_data_digest(inputs, keys): 2 m1 = hashlib.md5() 3 m1.update((inputs + keys).encode('utf-8')) 4 5 # base64.b64encode(m1.hexdigest()) 得到错误值!!! 6 return base64.b64encode(m1.digest())
此处踩到几个坑卡了很久,主要是m1.hexdigest()与m1.digest()的不同,导致计算出的结果与java,js算出的不同
一开始以为是str转bytes的问题,注意python的str.encode('utf-8')与java的getBytes()结果在显示上有所不同(前者返回bytes类型,后者返回byte[]类型)
请求调用api并写入文件:
1 address_list = get_address() 2 3 for x in address_list: 4 # unicode形态转中文,去掉空格(否则查不出) 5 inputs = json.dumps(get_raw_input(x)).encode('utf-8').decode('unicode_escape').replace(' ', '') 6 7 result = requests.post(url, data=get_param(get_data_digest(inputs, keys), inputs), headers=headers) 8 result = result.content.decode(encoding='utf-8') 9 # print(result) 10 results = results + result + ' ' 11 12 13 try: 14 with open(os.getcwd()+r' esult.txt', 'w') as f: 15 f.write(results) 16 print("写入成功") 17 except: 18 print("写文件失败")
此处又踩到一个小坑-。-,由于python3.x的str类型中文数据默认采用unicode编码显示,所以会得到中文变成u...的数据,导致查询失败
json.dumps()将dict转化为json字符串返回,先utf-8编码为bytes类型
再用decode('unicode_escape')解码让中文字符正常显示
同时请求参数中有空格也会导致查询失败(阿里api文档太简单什么都没说,参数只能自己慢慢调,差评)
所以此处用replace(' ','')除去空格
得到结果集:
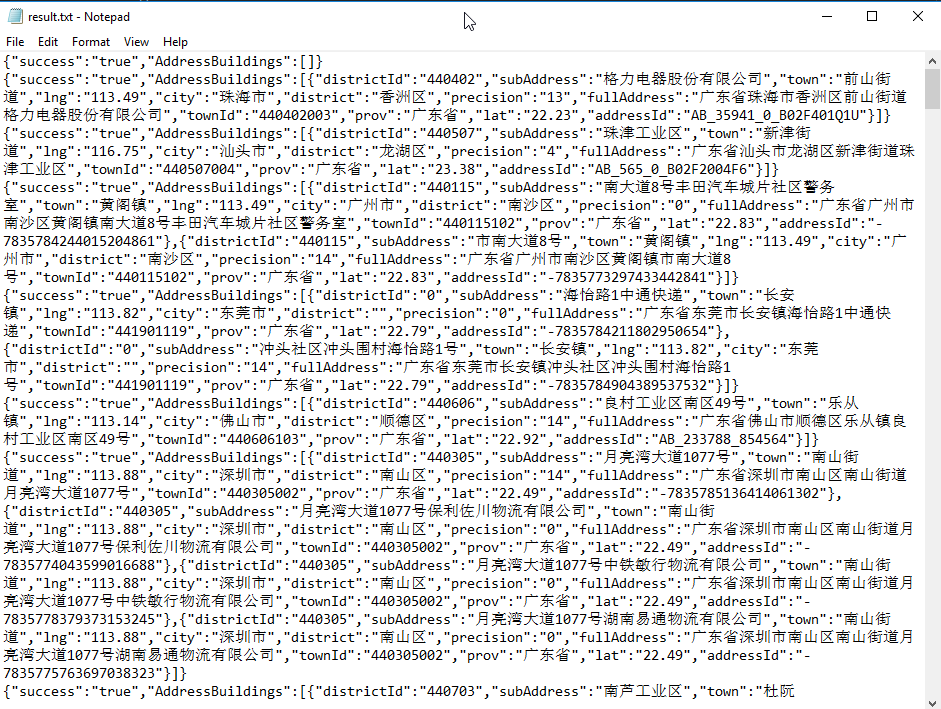
完整代码:
1 # coding:utf-8 2 # by NeilShi 11/29/2017 3 import requests 4 import hashlib 5 import base64 6 import json 7 import os 8 9 10 # 'appkey': '154430', 11 # 'AppSecret': 'S7ib51Kp5......Qd10Lt4490QTwpr', 12 # 资源:d0119848ab5......df5d8d6dc149 13 14 url = 'http://link.cainiao.com/gateway/link.do' 15 keys = 'S7ib51Kp5O......d10Lt4490QTwpr' 16 17 headers = { 18 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8' 19 } 20 21 results = '' # 存放结果集 22 23 24 def get_address(): 25 try: 26 with open(os.getcwd() + r'address.txt', 'r') as f: 27 address = f.readlines() 28 return address 29 except: 30 print('打开文件失败') 31 return '' 32 33 34 def get_raw_input(address): 35 raw_input = { 36 "address": address, 37 "limit": "20" 38 } 39 return raw_input 40 41 42 def get_param(sign, content): 43 param = { 44 'msg_type': 'CNDZK_ADDRESS_QUERY', 45 'data_digest': sign, 46 'logistic_provider_id': 'd011984......d7ae1df5d8d6dc149', 47 'logistics_interface': content 48 } 49 return param 50 51 52 def get_data_digest(inputs, keys): 53 m1 = hashlib.md5() 54 m1.update((inputs + keys).encode('utf-8')) 55 56 # base64.b64encode(m1.hexdigest()) 得到错误值!!!原因未知 57 return base64.b64encode(m1.digest()) 58 59 60 address_list = get_address() 61 62 for x in address_list: 63 # unicode形态转中文,去掉空格(否则查不出) 64 inputs = json.dumps(get_raw_input(x)).encode('utf-8').decode('unicode_escape').replace(' ', '') 65 66 result = requests.post(url, data=get_param(get_data_digest(inputs, keys), inputs), headers=headers) 67 result = result.content.decode(encoding='utf-8') 68 # print(result) 69 results = results + result + ' ' 70 71 72 try: 73 with open(os.getcwd()+r' esult.txt', 'w') as f: 74 f.write(results) 75 print("写入成功") 76 except: 77 print("写文件失败")