本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践。

前言
在先前的 Query Engine 源码解析中,我们介绍了 2.0 中 Query Engine 和 1.0 的主要变化和大体的结构:
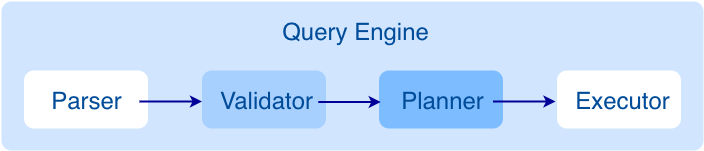
大家可以大概了解到用户通过客户端发送一条查询语句,Query Engine 是如何解析语句、把语句构建为抽象语法树,在抽象语法树进行校验、生成执行计划的过程。本文会通过 2.0 中新增的子图算法模块继续讲解 Query Engine 背后所做的内容,并着重介绍执行计划生成的过程,以便加强你对源码更好地理解。
子图的定义
子图是指节点集合和边集合分别是某一图的节点集的子集和边集的子集的图。直观地理解,就是从用户指定的起点开始出发沿着指定的边一步步拓展,直到达到用户所设定的步数为止,然后返回在拓展过程中遇到的所有点集和边集。
子图的语法
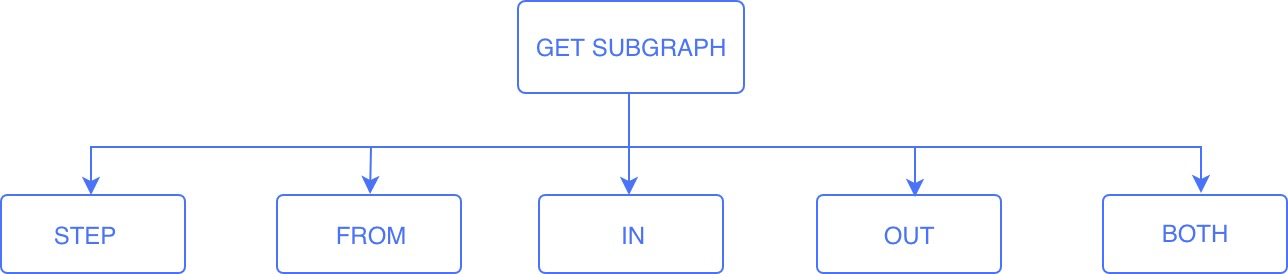
GET SUBGRAPH [<step_count> STEPS] FROM {<vid>, <vid>...} [IN <edge_type>, <edge_type>...]
[OUT <edge_type>, <edge_type>...] [BOTH <edge_type>, <edge_type>...]
- step_count:指定从起始点开始的跳数,返回从 0 到
step_count跳的子图。必须是非负整数。默认值为 1 - vid:指定起始点 ID
- edge_type:指定边类型。可以用
IN、OUT和BOTH来指定起始点上该边类型的方向。默认为BOTH
子图的实现
当 Query Engine 接收到 GET SUBGRAPH 命令后,Parser 模块(由 flex 和 bison 实现)会根据已经写好的规则(parser.yy 中 get_subgraph_sentence 规则)把所需要的内容从查询语句中提取出来,生成一个抽象语法树,如下所示:
然后进入 Validate 阶段,此时对生成的抽象语法树进行校验,目的是为了验证用户的输入是否合法(参考 Query Engine 的文章),当校验通过后,会把语法树中的内容提取出来,生成一个执行计划。
那么这个执行计划是如何生成的呢?对同一功能不同的数据库厂商可能会生成不同的执行计划,但是原理都是相同的。那就是要看自身的算子有哪些和查询层和存储层是如何进行交互的。因为我们的每一条查询语句到最后都是要从存储层取数据的。在 Nebula Graph 中 Query Engine 和存储层是通过 RPC 方式(fbthrift)进行交互的(接口定义在 common 仓中的 interface 目录下)。这里有两个非常关键的接口 getNeighbors 和 getProps 需要了解一下。
getNeighbors 其中 fbthrift 的定义格式如下:
struct GetNeighborsRequest {
1: common.GraphSpaceID space_id,
2: list<binary> column_names,
3: map<common.PartitionID, list<common.Row>>
(cpp.template = "std::unordered_map") parts,
4: TraverseSpec traverse_spec
}
该结构中每个变量的详细定义可以参考 https://github.com/vesoft-inc/nebula-common/blob/master/src/common/interface/storage.thrift,里面有详细的注释。
其主要功能就是 Query Engine 根据定义好的结构传入起始点和要拓展的边类型信息,然后存储层会找到起始点,然后把该点的属性和以该点的出边的边属性找出来组装成一个表格返回给 Query Engine,其中返回的表格的格式参考 https://github.com/vesoft-inc/nebula-common/blob/master/src/common/interface/storage.thrift 中 GetNeighborsResponse 的定义,然后在 Query Engine 中我们就可以通过这个表格提取到我们想要的内容。
例如在 basketba l l 数据集中,当起始点为 Tim Duncan、Manu Ginobili 沿着 like 边双向拓展。想要获得 $^.[player.name](http://player.name/)、like._dst、$$.[player.name](http://player.name/) 和 like.likeness 这四个属性。其返回的数据大致如下所示:
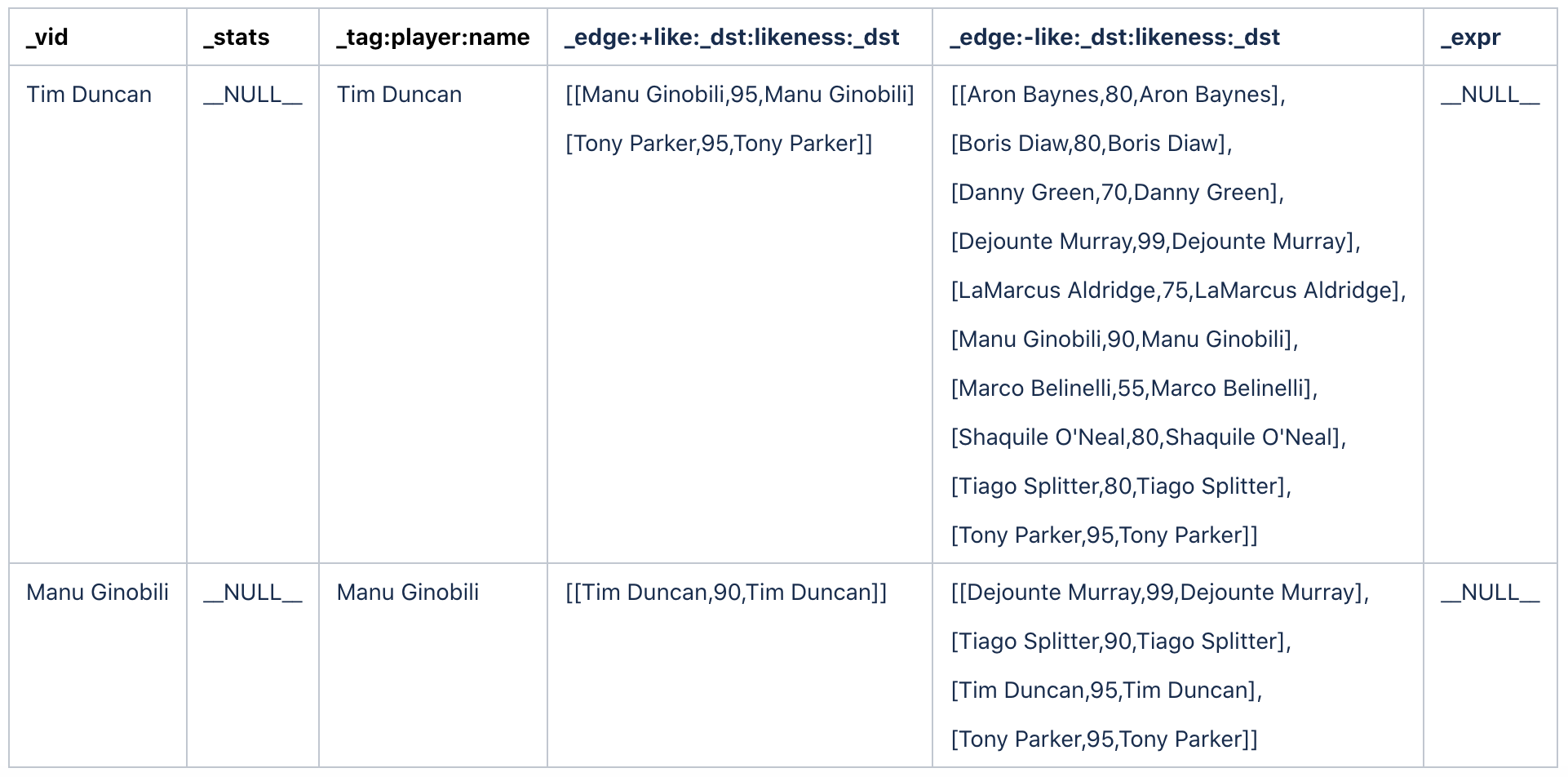
表格1
因为是双向拓展第四列的 + like 代表出边,第五列的 - like 代表入边。
在 Nebula Graph 的存储层中边是和起始点在一起存放的,所以通过 getNeighbor 接口就可以获得起点和出边的所有属性信息,但是如果想要在拓展过程中拿到目的点的属性信息则需要使用 getProps 接口,当然如果我只想通过 fetch 语句拿到某个点或者边的属性也需要调用这个接口。你可以自行了解 https://github.com/vesoft-inc/nebula-common/blob/master/src/common/interface/storage.thrift 下 getPropRequest 的定义,加深理解。
执行计划
有了上面的接口定义我们就可以开始执行计划了,首先需要的算子有 start、getNeighbor、subgraph、loop、datacollect。
- start 算子:相当于执行计划中叶子节点,不做任何事情。目的是告诉调度器,之后没有可以依赖的算子,或者可以理解为递归算法中的终止条件。
- loop 算子:相当于 C 语言中的 while 语法,该算子有三个成员 depend、condition 和 loopBody,depend 在多语句和
PIPE中会使用当前暂且不表,condition 相当于终止条件。loopBody 相当于 while 中的循环体。 - subgraph 算子:负责把 getNeighbor 算子结果中的
_dst(目的点)属性提出来然后过滤掉已经访问过的目的点(避免重复从存储层拿数据),然后把它们当作 getNeighbor 算子下一次拓展时的输入。 - datacollect 算子:负责在最后把拓展过程中获得的点和边属性收集起来组装为 vertex 和 edge 类型。
其中各个算子的详细信息,可参考源码 https://github.com/vesoft-inc/nebula-graph/tree/master/src/executor 。
下面通过图1 举例,我们是如何构建子图的
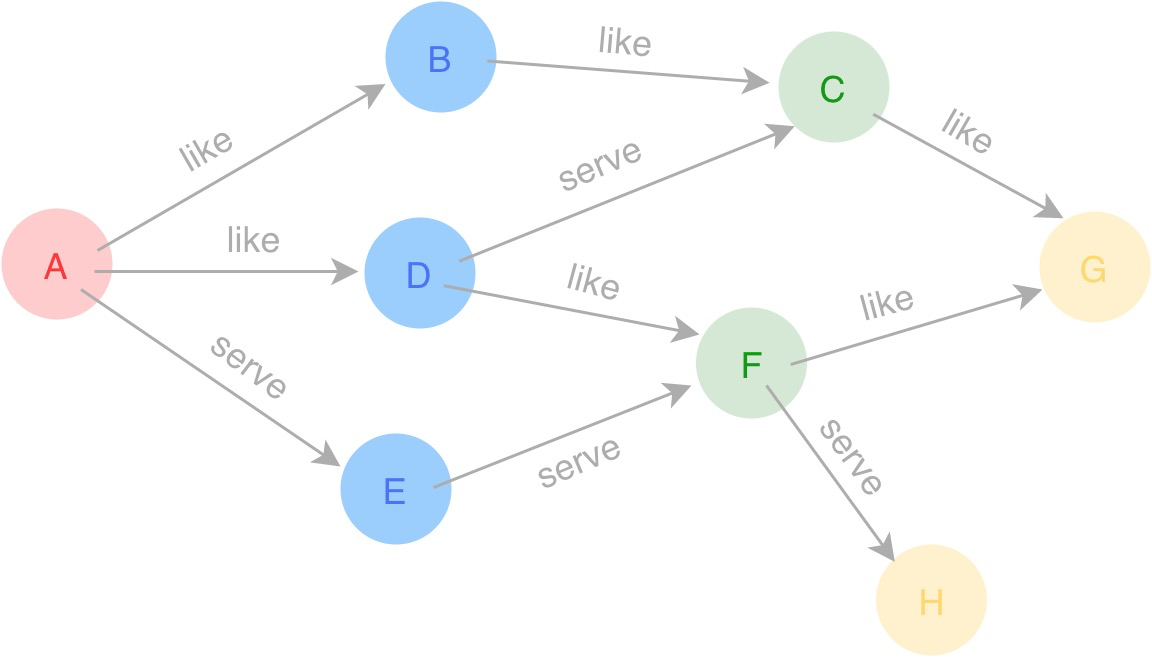
图1
拓展一步的情况
当从 A 点开始沿着 like 边只获取一步的所有点和边的信息,则很容易。只需要 getNeighbor 和 dataCollect 这两个算子就可以了。执行计划如下图所示 :
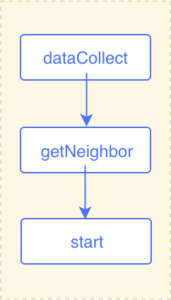
拓展多步的情况
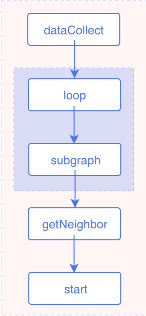
一步场景其实是多步的场景的特殊情况。所以可以将一步的场景合入到多步场景中。当从 A 点开始,沿着 like 边拓展三步的话,根据现有的算子,可以在 getNeighbor 拓展后把目的点提取出来,然后将这些目的点当作起点重新调用 getNeighbor 接口,这个循环两次就可以了(loop 算子的终止条件设置为当前步数),因此执行计划如下图所示 :
输入和输出
一般情况下,每个算子的输入就是所依赖算子的输出,这时候根据执行计划的依赖关系就可以直观地确定每个算子的输入和输出。但是在某些情况下,比如:子图,在多步场景中每一次 getNeighbor 算子的输入都应该是上一次拓展边的目的点,也就是 subgraph 算子的输出,因此 subgraph 算子的输出应该就是 getNeighbor 算子的输入。这时就和上图的执行计划依赖不一致,这时就需要自行设置每个算子的输入和输出。在 Query Engine 2.0 中我们已经介绍了每个算子的输入和输出是存放在哈希表中的,其中 value 是 vector 类型。如下表 ResultMap 所示:

- 起始点存放在 ResultMap["StartVid"] 中
- getNeighbor 算子的输入是 ResultMap["StartVid"], 输出存放在 ResultMap["GN_1"]
- subgraph 算子的输入是 ResultMap["GN_1"], 输出存放在 ResultMap["StartVid"]
- loop 算子不产生数据,当作逻辑循环使用,因此不需要设置输入输出
- dataCollect 算子的输入是 ResultMap["GN_1"], 输出存放在 ResultMap["DATACOLLECT_2"]
这时 getNeighbor 算子会把每一次的结果放在 ResultMap["GN_1"] 中的 vector 中的末尾,然后 subgraph 算子从 ResultMap["GN_1"] 中的 vector 中的末尾取值,经过计算再把下一次要拓展的起始点存放在 ResultMap["StartVid"] 中。
当拓展第一步后,ResultMap 的结果如下:
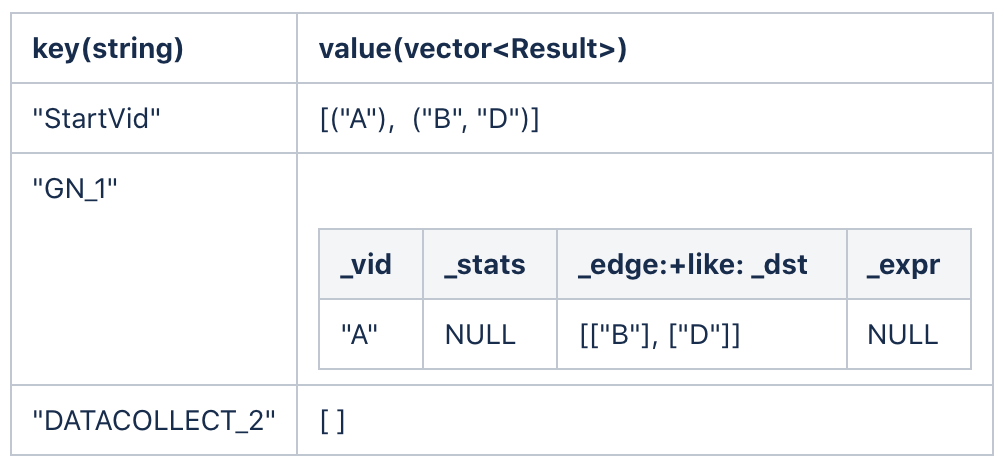
为了方便显示,GetNeighbor 的结果只写了 _dst 的属性,实际上会带上边上所有的属性和起始点的所有属性,类似于表格 1。
subgraph 算子接收"GN_1"的输入,提取 _dst 属性,然后将结果放入"StartVid"中。当拓展第二步后,ResultMap 的结果如下:
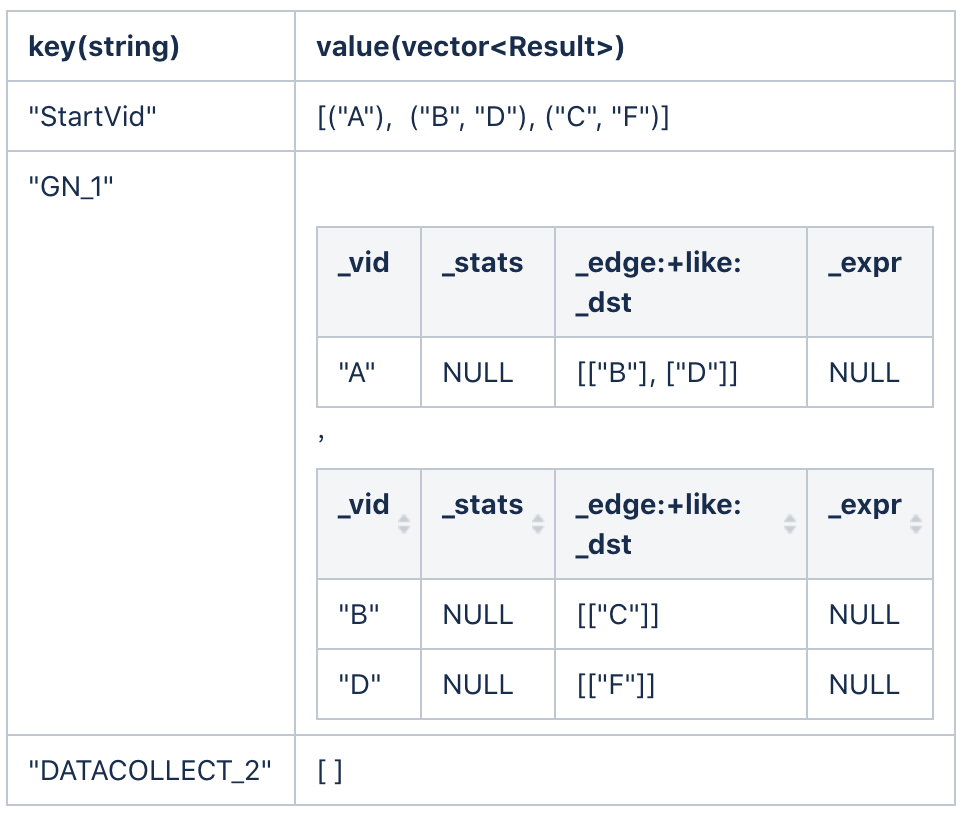
当拓展第三步后,ResultMap 的结果如下:
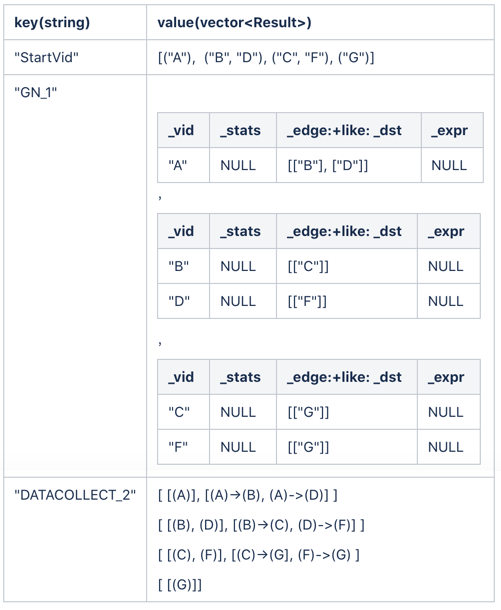
最后 dataCollect 算子从 ResultMap["GN_1"] 中取出拓展过程中遇到的所有点集和边集,组装成最终的结果返回给用户。
实例
下面执行一个子图的实例看看在 Nebula Graph 中执行计划的具体结构,打开 nebula-console, 切换 space 到 basketball, 输入 EXPLAIN format="dot" GET SUBGRAPH 2 STEPS FROM 'Tim Duncan' IN like, serve,这时候 nebula-console 会生成 dot 格式的数据,然后打开 Graphviz Online 这个网站,将生成的 dot 数据粘贴上去,就可以看到如下结构:
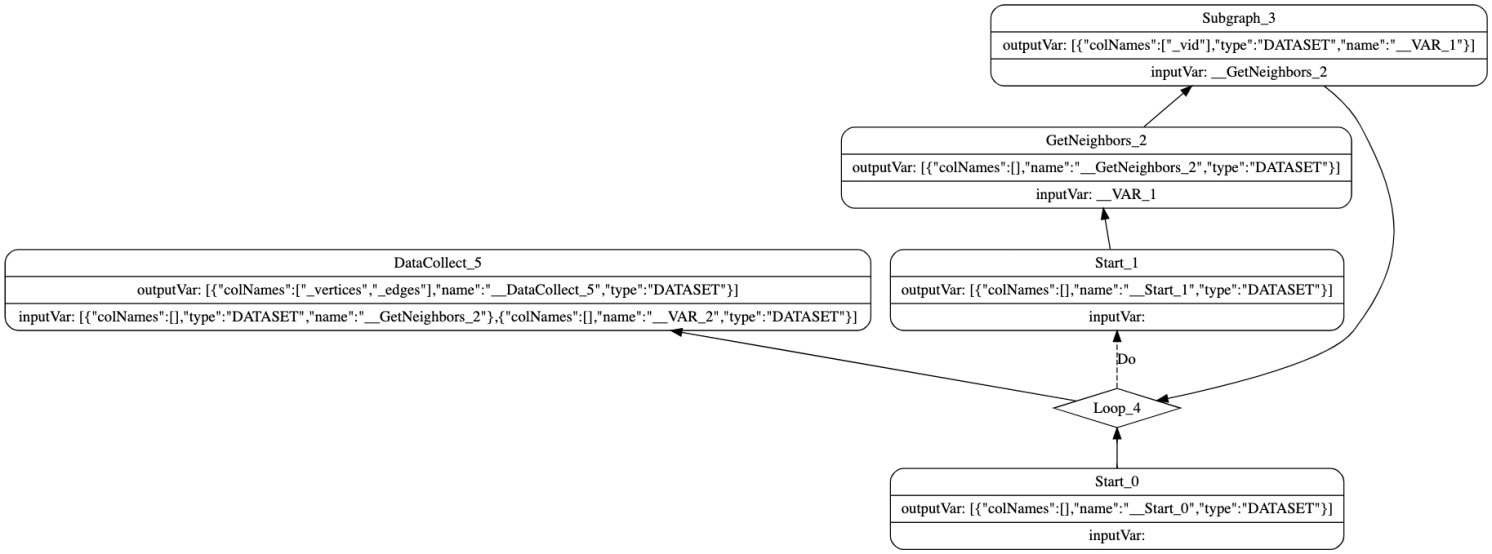
其中 Start_0 算子是 loop 算子中 depend 的依赖,由于没有多语句或 PIPE 语句,因此不做任何处理。
以上为本次子图的讲解,如果你在使用子图或者其他 Nebula 过程中遇到问题,欢迎来论坛和我们交流:https://discuss.nebula-graph.com.cn/
想要和其他大厂交流图数据库技术吗?NUC 2021 大会等你来交流:NUC 2021 报名传送门