一.新特性提纲
1.数据库管理部分
◆数据库重演(Database Replay)
这一特性可以捕捉整个数据的负载,并且传递到一个从备份或者standby数据库中创建的测试数据库上,然后重演负责以测试系统调优后的效果。
◆SQL重演(SQL Replay)
和前一特性类似。但是只是捕捉SQL负载部分,而不是全部负载。
◆计划管理(Plan Management)
这一特性允许你将某一特定语句的查询计划固定下来,无论统计数据变化还是数据库版本变化都不会改变她的查询计划。
◆自动诊断知识库(Automatic Diagnostic Repository ADR)
当Oracle探测到重要错误时,会自动创纪一个事件(incident),并且捕捉到和这一事件相关的信息,同时自动进行数据库健康检查并通知DBA。此外,这些信息还可以打包发送给Oracle支持团队。
◆事件打包服务(Incident Packaging Service)
如果你需要进一步测试或者保留相关信息,这一特性可以将与某一事件相关的信息打包。并且你还可以将打包信息发给oracle支持团队。
◆基于特性打补丁(Feature Based Patching)
在打补丁包时,这一特性可以使你很容易区分出补丁包中的那些特性是你正在使用而必须打的。企业管理器(EM)使你能订阅一个基于特性的补丁服务,因此企业管理器可以自动扫描那些你正在使用的特性有补丁可以打。
◆自动SQL优化(Auto SQL Tuning)
10g的自动优化建议器可以将优化建议写在SQL profile中。而在11g中,你可以让oracle自动将能3倍于原有性能的profile应用到SQL语句上。性能比较由维护窗口中一个新管理任务来完成。
◆访问建议器(Access Advisor)
11g的访问建议器可以给出分区建议,包括对新的间隔分区(interval partitioning)的建议。间隔分区相当于范围分区(range partitioning)的自动化版本,她可以在必要时自动创建一个相同大小的分区。范围分区和间隔分区可以同时存在于一张表中,并且范围分区可以转换为间隔分区。
◆自动内存优化(Auto Memory Tuning)
在9i中,引入了自动PGA优化;10g中,又引入了自动SGA优化。到了11g,所有内存可以通过只设定一个参数来实现全表自动优化。你只要告诉oracle有多少内存可用,她就可以自动指定多少内存分配给PGA、多少内存分配给SGA和多少内存分配给操作系统进程。当然也可以设定最大、最小阈值。
◆资源管理器(Resource Manager)
11g的资源管理器不仅可以管理CPU,还可以管理IO。你可以设置特定文件的优先级、文件类型和ASM磁盘组。
◆ADDM
ADDM在10g被引入。11g中,ADDM不仅可以给单个实例建议,还可以对整个RAC(即数据库级别)给出建议。另外,还可以将一些指示(directive)加入ADDM,使之忽略一些你不关心的信息。
◆AWR 基线(AWR Baselines)
AWR基线得到了扩展。可以为一些其他使用到的特性自动创建基线。默认会创建周基线。
2.PLSQL部分
◆结果集缓存(Result Set Caching)
这一特性能大大提高很多程序的性能。在一些MIS系统或者OLAP系统中,需要使用到很多"select count(*)"这样的查询。在之前,我们如果要提高这样的查询的性能,可能需要使用物化视图或者查询重写的技术。在11g,我们就只需要加一个/*+result_cache*/的提示就可以将结果集缓存住,这样就能大大提高查询性能。当然,在这种情况下,我们可能还要关心另外一个问题:完整性。因为在oracle中是通过一致性读来保证数据的完整性的。而显然,在这种新特性下,为提高性能,是从缓存中的结果集中读取数据,而不会从回滚段中读取数据的。关于这个问题,答案是完全能保证完整性。因为结果集是被独立缓存的,在查询期间,任何其他DML语句都不会影响结果集中的内容,因而可以保证数据的完整性。
◆对象依赖性改进
在11g之前,如果有函数或者视图依赖于某张表,一旦这张表发生结构变化,无论是否涉及到函数或视图所依赖的属性,都会使函数或视图变为invalid。在11g中,对这种情况进行了调整:如果表改变的属性与相关的函数或视图无关,则相关对象状态不会发生变化。
◆正则表达式的改进
在10g中,引入了正则表达式。这一特性大大方便了开发人员。11g,oracle再次对这一特性进行了改进。其中,增加了一个名为regexp_count的函数。另外,其他的正则表达式函数也得到了改进。
◆新SQL语法 =>
我们在调用某一函数时,可以通过=>来为特定的函数参数指定数据。而在11g中,这一语法也同样可以出现在sql语句中了。例如,你可以写这样的语句:
|
select f(x=>6) from dual; |
◆对TCP包(utl_tcp、utl_smtp…)支持FGAC(Fine Grained Access Control)安全控制
◆增加了只读表(read-only table)
在以前,我们是通过触发器或者约束来实现对表的只读控制。11g中不需要这么麻烦了,可以直接指定表为只读表。
◆触发器执行效率提高了
内部单元内联(Intra-Unit inlining)
在C语言中,你可以通过内联函数(inline)或者宏实现使某些小的、被频繁调用的函数内联,编译后,调用内联函数的部分会编译成内联函数的函数体,因而提高函数效率。在11g的plsql中,也同样可以实现这样的内联函数了。
◆设置触发器顺序
可能在一张表上存在多个触发器。在11g中,你可以指定它们的触发顺序,而不必担心顺序混乱导致数据混乱。
◆混合触发器(compound trigger)
这是11g中新出现的一种触发器。她可以让你在同一触发器中同时具有申明部分、before过程部分、after each row过程部分和after过程部分。
◆创建无效触发器(Disabled Trigger)
11g中,开发人员可以可以闲创建一个invalid触发器,需要时再编译她。
◆在非DML语句中使用序列(sequence)
在之前版本,如果要将sequence的值赋给变量,需要通过类似以下语句实现:
|
select seq_x.next_val into v_x from dual; |
在11g中,不需要这么麻烦了,下面语句就可以实现:
|
v_x := seq_x.next_val; |
◆PLSQL_Warning
11g中,可以通过设置PLSQL_Warning=enable all,如果在"when others"没有错误爆出就发警告信息。
◆PLSQL的可继承性
可以在oracle对象类型中通过super(和java中类似)关键字来实现继承性。
◆编译速度提高
因为不在使用外部C编译器了,因此编译速度提高了。
◆改进了DBMS_SQL包
其中的改进之一就是DBMS_SQL可以接收大于32k的CLOB了。另外还能支持用户自定义类型和bulk操作。
◆增加了continue关键字
在PLSQL的循环语句中可以使用continue关键字了(功能和其他高级语言中的continue关键字相同)。
◆新的PLSQL数据类型——simple_integer
这是一个比pls_integer效率更高的整数数据类型。
3.其他部分
◆增强的压缩技术
可以最多压缩2/3的空间。
◆高速推进技术
可以大大提高对文件系统的数据读取速度。
◆增强了DATA Guard
可以创建standby数据库的快照,用于测试。结合数据库重演技术,可以实现模拟生成系统负载的压力测试。
◆在线应用升级
也就是热补丁——安装升级或打补丁不需要重启数据库。
◆数据库修复建议器
可以在错误诊断和解决方案实施过程中指导DBA。
◆逻辑对象分区
可以对逻辑对象进行分区,并且可以自动创建分区以方便管理超大数据库(Very Large Databases VLDBs)。
◆新的高性能的LOB基础结构
◆新的PHP驱动
二. 详细介绍
1. 分区
Partition(分区)一直是Oracle数据库引以为傲的一项技术,正是分区的存在让Oracle高效的处理海量数据成为可能,在Oracle 11g中,分区技术在易用性和可扩展性上再次得到了增强。
1.1. Interval Partitioning
在我曾经的一个项目中,由于数据量的巨大,所以表设计为每一个小时一个分区,数据库管理员日常要做的一件重复而无聊的工作就是每隔一天要生成新的24个分区,用以存储第二天的数据。而在11g中这项工作可以交由Oracle自动完成了,基于Range和List的Interval Partitioning分区类型登场。
CREATE TABLE TB_INTERVAL
PARTITION BY RANGE (time_col)
INTERVAL(NUMTOYMINTERVAL(1, 'month'))
(PARTITION P0 VALUES LESS THAN (TO_DATE('1-1-2010', 'dd-mm-yyyy')));
指定需要Oracle自动创建分区的间隔时间,上面这个例子是1个月,然后至少创建一个基本分区,上面这个例子是在2010-1-1之前的所有数据都在P0分区中,以后每个月的数据都会存放在Oracle自动创建的一个新分区中。
1.2. System Partitioning
系统分区,在这个新的类型中,我们不需要指定任何分区键,数据会进入哪个分区完全由应用程序决定,实际上也就是由SQL来决定,终于,我们在Insert语句中可以指定插入哪个分区了。
假设我们创建了下面这张分区表,注意,没有指定任何分区键:
CREATE TABLE systab (c1 integer, c2 integer)
PARTITION BY SYSTEM
(
PARTITION p1 TABLESPACE tbs_1,
PARTITION p2 TABLESPACE tbs_2,
PARTITION p3 TABLESPACE tbs_3,
PARTITION p4 TABLESPACE tbs_4
);
现在由SQL语句来指定插入哪个分区:
-- 数据插入p1分区
INSERT INTO systab PARTITION (p1) VALUES (4,5);
-- 数据插入第2个分区,也就是p2分区
INSERT INTO systab PARTITION (2) VALUES (7,8);
-- 为了实现绑定变量,用pno变量来代替实际分区号,以避免过度解析
INSERT INTO systab PARTITION (:pno) VALUES (9,10);
由于System Partitioning的特殊性,所以很明显,这种类型的分区将不支持Partition Split操作,也不支持create table as select操作。
1.3. More Composite Partitioning
在10g中,我们知道复合分区只支持Range-List和Range-Hash,而在在11g中复合分区的类型大大增加,现在Range,List,Interval都可以作为Top level分区,而Second level则可以是Range,List,Hash,也就是在11g中可以有3*3=9种复合分区,满足更多的业务需求。
1.4. Virtual Column-Based Partitioning
Virtual Column是11g中的一个新功能,这种列中的数据并不实际存储于磁盘上(我们可以看成是一个类似Function的列),只有当读取的时候才实时计算。暂时不讨论性能问题,这个功能还是比较有意思的。
可以通过这样的语句来创建虚拟列。
CREATE TABLE tb_v
(col_1 number(6) not null,
col_2 number not null,
…
col_v as (col_1 *( 1+col_2));
虚拟列虽然没有实际的存储空间,但是却可以跟其他普通列一样,创建索引,作为分区键,甚至可以收集统计信息。
2. 数据压缩技术
随着数据量的不断海量,CPU的不断强劲,双核四核的叫个不停,一种叫做时间换空间的优化技术应该会越来越流行。所以,数据压缩对于今后的数据库来说,应该会从核武器变成常规武器。
Oracle11g是正儿八经的要推广数据压缩技术了,专门推出了一个叫做Advance Compression的组件,全面支持普通表压缩,非结构化数据压缩(SecureFile数据压缩),Data Pump数据压缩,以及RMAN备份压缩,数据压缩技术从此名正言顺的登上历史舞台。
在Oracle9i中虽然引入了表压缩,但是有很大的限制。只能对批量装载操作(比如直接路径装载,CTAS等)涉及的数据进行压缩,普通的DML操作的数据是无法压缩的。这应该是对于写操作的压缩难题没有解决,一直遗留到Oracle11g,总算是解决了关系数据压缩的写性能问题。Oracle的表压缩是针对Block级别的数据压缩,主要技术和Oracle9i差不多,还是在Block中引入symbol表,将block中的重复数据在symbol中用一个项表示。Oracle会对block进行批量压缩,而不是每次在block中写入数据时都进行压缩,通过这种方式,可以尽量降低数据压缩对于DML操作的性能影响。这样,在block级别应该会引入一个新的参数,用于控制block中未压缩的数据量达到某个标准以后进行压缩操作。
SecureFile也是Oracle11g新推出的一项特性,用于存储非结构化数据。SecureFile也将支持数据压缩操作。这样对于传统的LOB字段也可以进行压缩,将极大的减少大型数据库的存储空间需求。当然,有得比有失,压缩和解压时,对于CPU的要求也将更高。但是,目前CPU的发展速度明显比IO和存储空间快速的情况下,压缩是大有可为的技术。通过在压缩率和压缩效率方面的不断提升,以后应该为成为各个数据库的标准配置。
除了对数据库中的数据进行压缩,Advance Compression Option还将支持备份数据的压缩。做为逻辑备份的Data Pump和物理备份的RMAN工具,都将支持该技术。在Oracle10gR2中,Data Pump已经开始支持压缩源数据,Oracle11g中则可以直接压缩导出文件,这样导出的时候就可以极大的减少存储空间的需求。在以前版本中,利用WinRAR等,经常可以将几个G的导出文件压缩到几十M,Oracle11g的白皮书上说压缩率可以达到74.67%。同样的,Oracle也在10g中开始引入RMAN的压缩技术。但是Oracle11g号称采用了更先进的ZLIB要所算法,可以比Oracle10g的压缩算法快上40%,空间需求也将减少20%。
除了上述的数据压缩技术,Oracle 11g Advanced Compression Option还将引入另外一种压缩技术。我们知道在Data Guard中,需要将日志从主库传递到备库。如果主库的事务很多,则单位时间内需要传递的日志量将相当可观。如果能将这些日志压缩后在传递,然后在备库解压后应用,将极大的减少对于网络带宽的需求,从而已减少主备库的时间差。
另外,Oracle的bitmap一直就是压缩存储的,10g中的bitmap对于9i就有比较大的改动,通过一些细节的完善,提供更好的性能和更高的稳定性,也是oracle一贯的风格。对于bitmap在Oracle11g中将如何实现,也将是非常值得关注的一个特点。
从Oracle11g开始,将没有什么是不可压缩的。使用更强大的CPU,就可以降低或者延缓对存储空间无休止的渴求,或许很多大型OLTP和大多数的数据仓库,都将从数据压缩技术中收益。
3.统计信息收集
下面围绕统计信息收集,分别对收集统计信息时可以设置的选项、对合并列收集统计信息,对表达式和函数收集统计信息以及延迟发布统计信息这四个方面做了阐述。
3.1. 设置收集统计信息时的选项
我们知道,数据库里的对象的统计信息(statistics)对于优化器得到正确的执行计划来说起着至关重要的作用。因此从10g R1开始,只要使用DBCA安装的数据库,都会自动创建一个job,该job缺省周一到周五每天晚上10点到第二天早上6点(周末则为全天)负责收集数据库所有对象的统计信息。不过,可能存在某些情况,你需要用自己的脚本来收集某些特殊对象的统计信息。但是由于你采用了自动收集统计信息,oracle就会对所有对象使用相同的选项来收集统计信息,这样你就失去了对某个对象的控制权。当你发现缺省的统计信息收集方式对某个对象不是很合适时,你必须锁定该对象的统计信息,并使用一个特殊的选项值对该对象来收集统计信息。
比如,某个表的列的数据倾斜(列为某种值的记录行数非常多,而某种值的记录行数又非常少)的非常严重,这时如果采用标准的采样率:
ESTIMATE_PERCCENT=AUTO_SAMPLE_SIZE可能就不适合了。这时你就需要单独指定该对象的采样率。我们知道,在11g之前的收集统计信息方面,oracle提供的类似的其他选项还包括:CASCADE、DEGREE、METHOD_OPT、NO_INVALIDATE、GRANULARITY。
到了11g里,则提供了更大的灵活性,从而使得你可以很简单的处理上面所说的这种情况。在11g里,上面说的这些选项可以在不同的级别上分别设置,级别由高到低分别为:global级别、数据库级别、schema级别、表级别。其中,低级别的选项覆盖高级别的选项。
比如,对于上面所举的例子来说,如果要对你的一个特殊的、列上的值倾斜的很严重的表收集统计信息时,你只需要简单的调用如下的存储过程来设置该表级别上的的ESTIMATE_PERCCENT=100即可,如下所示:
SQL> exec dbms_stats.set_table_prefs('Schema_name','Table_name',
'ESTIMATE_PERCCENT','100');
这样设置以后,当数据库在自动收集统计信息时,对于其他没有单独设置采样率的表来说,采样率会采用AUTO_SAMPLE_SIZE,而对于你单独设置的Table_name表,则会使用100的采样率来收集统计信息。
类似的,如果需要设置global级别上的选项,则调用dbms_stats.set_global_prefs;如果要设置数据库级别上的选项,则调用dbms_stats.set_database_prefs;如果要设置schema级别上的选项,则调用dbms_stats.set_schema_prefs即可。
同时到了11g里,除了上面提到的这些选项以外,还添加了另外三种新的选项:PUBLISH、INCREMENTAL、STALE_PERCENT。其中:
1) PUBLISH:收集完统计信息以后是否立即将统计信息发布到数据字典里,还是将它们存放在私有区域里。TRUE表示立即发布,FALSE表示存放到私有区域里。
2) STALE_PERCENT:确定某个对象的统计信息过时的上限,如果过时就需要重新收集统计信息,缺省为10。计算某个表的统计信息是否过时,oracle会计算自从上一次收集该表的统计信息以来,该表中被修改的数据行数占该表的总行数的百分比。然后用得出的百分比值与该选项配置的值(如果缺省,就是10)进行比较,大于10,则说明该表的统计信息过时了,需要重新收集统计信息;否则就认为该表的统计信息不过时,不用再次收集。
3) INCREMENTAL:在分区表上收集global的统计信息时(将GRANULARITY设置为GLOBAL),采用增量方式完成。使用该选项是因为对于某些分区表来说,比如按照月份进行范围分区的分区表来说,除了代表当前月的分区里的数据会经常变化以外,其他分区里的数据不会变动。因此在收集该分区表上的global的统计信息时,就没有必要再次扫描那些非当前月的分区了。如果你将INCREMENTAL设置为TRUE时,则在收集统计信息时,就不会扫描那些非当前月的分区里的数据,而只会扫描当前月的分区里的数据。最后将非当前月的分区上已经存在的统计信息加上当前月新算出来的统计信息合并就得出了分区表的global的统计信息。
可以从视图:DBA_TAB_STAT_PREFS里看到所有的收集统计信息时的各个选项的值。
3.2. 对合并列收集统计信息
对于where条件里具有两个列以上的情况,比如where c1=’A’ and c2=’B’来说,11g以前优化器评估其selectivity时,总是将每个列的selectivity相乘,从而得到整个where条件的selectiviey。但是如果两个列具有很强的依赖关系,比如汽车制造商与汽车型号这两个列来说,我们知道每个汽车制造商所生产的汽车型号几乎都不会重复,也就是说当你发出where 汽车制造商列=’XXX’ and 汽车型号列=’XXX’时,与发出where汽车型号列=’XXX’时返回的记录行数可能几乎一样。这时如果在计算where条件的selectivity时仍然采用将汽车制造商列的selectivity乘以汽车型号列的selectivity时,就会导致总的selectivity过低,从而导致优化器估计返回的记录行数过少,从而可能导致不正确的执行计划。
为了弥补这样的问题,11g以后可以让你将多个依赖程度很高列合并成一个组,然后对该组收集统计信息。具体如何实现,则可以看下面的例子。
select dbms_stats.create_extended_stats('Schema_name','Table_name','(C1,C2)') from dual;
通过调用函数dbms_stats.create_extended_stats将两个或多个列合并,并返回一个虚拟的隐藏列的列名,其名字类似于:SYS_STUW_5RHLX443AN1ZCLPE_GLE4。
然后,我们可以开始对表收集统计信息,收集完以后,你可以使用ALL|DBA|USER_STAT_EXTIONSIONS视图来查看列组合的统计信息。
exec dbms_stats.gather_table_stats('Schema_name','Table_name');
如果你要对组合列收集直方图,则可以如下所示:
exec dbms_stats.gather_table_stats('Schema_name','Table_name',
method_opt=>'for columns (C1,C2) size AUTO');
3.3 对函数以及表达式收集统计信息
如果where条件类似于function_name(table_name.column_name)=’XXX’时,则优化器在估计这样的where条件的selectivity时,总是会假设其selectivity为1%,也就是该where条件将返回table_name里总记录行数的1%的记录行数。很明显的,这种假设肯定是错误的,从而可能导致优化器产生了不够优化的执行计划。
从11g开始,我们可以对函数或者表达式收集统计信息了。该特性依赖于虚拟列,也就是说你需要先用dbms_stats.create_extended_stats函数为
function_name(table_name.column_name)创建一个虚拟列,然后对该虚拟列收集统计信息。比如下面的例子。
select dbms_stats.create_extended_stats('Schema_name','Table_name','length(C1)') from dual;
下面则显示的是对表达式来收集统计信息。
select dbms_stats.create_extended_stats('Schema_name','Table_name','C1*C2') from dual;
然后你可以对表收集统计信息时,就会为函数length(C1)对应的虚拟列收集统计信息了。如果你要对该虚拟列收集直方图,则可以如下所示:
exec dbms_stats.gather_table_stats('Schema_name','Table_name',
method_opt=>'for columns (length(C1)) size AUTO');
3.4 _PRIVATE_STATS里看到这些私有的统计信息。
为了测试这些私有统计信息,你可以有两种方法:
1) 第一种方式使用DBMS_STAT.EXPORT_PRIVATE_STATS存储过程将私有统计信息转移到你自己的统计信息表(可以使用存储过程DBMS_STATS.CREATE_STAT_TABLE来创建你自己的统计信息表)里。然后可以使用expdp导出你的统计信息表,然后再使用impdp将导出文件导入到测试环境中,再使用DBMS_STAT.IMPORT_TABLE_STATS将其导入到测试环境中进行测试。
2) 第二种方式不导出私有的统计信息,而是直接在产品库的session级别,将11g引入的新的初始化参数: OPTIMIZER_PRIVATE_STATISTICS设置为TRUE(缺省情况下该参数为FALSE)。这时你执行SQL时,优化器就会参考私有统计信息来解析SQL语句并生成执行计划了。
最后,测试完毕,发现最新的统计信息没有问题的话,你就可以使用DBMS_STAT.PUBLISH_PRIVATE_STATS在产品库上将私用统计信息发布出去,从而让优化器能够看到它们。
下面列举一个例子来简单说明这个过程。
首先设置表级别的publish选项为false:
exec dbms_stats.set_table_prefs('Schema_name','Table_name','PUBLISH','false');
然后,收集表的统计信息:
exec dbms_stats.gather_table_stats('Schema_name','Table_name');
第三,设置相关初始化参数:
alter session set optimizer_use_private_statistics = true;
第四,进行测试,运行相关的SQL语句,并检查产生的执行计划。
最后,把该表的统计信息发布出去:
exec dbms_stats.publish_private_stats('Schema_name','Table_name');
4.执行计划管理
4.1. 执行计划管理的工作原理
我们知道,SQL语句的性能很大程度上依赖于SQL语句的执行计划。如果SQL语句的执行计划发生改变,则SQL的性能很有可能发生大的变化。而SQL执行计划发生变化的原因有很多种,包括优化器版本的变化、统计信息的变化、优化器相关的各种参数的变化、添加或删除了索引、添加或删除了物化视图、修改了系统设置、以及是否应用了10g引入的SQL profile等。
在11g之前,我们可以使用存储大纲(stored outline)和SQL Profile来帮助我们固定某条SQL语句的执行计划,防止由于执行计划发生变化而导致的性能下降。不过这些技术需要DBA人为的处理,比如存储大纲,需要DBA手工创建,而SQL Profile来说,则要DBA手工应用才能生效。
从11g开始,oracle引入了SQL执行计划管理(SQL Plan Management)这个新特性,从而可以让系统自动的来控制SQL语句执行计划的稳定性,进而防止由于执行计划发生变化而导致的性能下降。
通过启用该特性,某条语句如果产生了一个新的执行计划,只有在它的性能比原来的执行计划好的情况下,才会被使用。为了实现执行计划管理,优化器会为所有执行次数超过一次的SQL语句维护该SQL语句的每个执行计划的历史列表(plan history)。优化器通过维护一个语句执行的日志条目(statement log)来识别该SQL语句是否为第二次执行。一旦优化器认出某条SQL语句为第二次执行,则优化器将该语句所生成的所有不同的执行计划插入到plan history的相关表里,而plan history里包含了优化器能够用于重新生成执行计划的所有信息,这些信息包括SQL文本、存储大纲、绑定变量以及解析环境(比如optimizer_mode之类影响优化器解析SQL语句的参数)等。
当然,11g也支持手工维护SQL语句的plan history,作为对自动维护plan history的功能补充。但是并不是说plan history里任何的执行计划都可以拿来使用。这里需要先介绍一下所谓的执行计划基准线(plan baseline)这个概念。plan baseline是plan history的一个子集,plan baseline里面的执行计划是用来比较性能好坏的一个依据。也就是说,凭什么来判断是否可以使用一个新产生的执行计划呢?就是把该新的执行计划与plan baseline里的计划进行比较来判断。某个SQL语句的执行计划可以属于plan history,但是不一定属于plan baseline。
注意:每个SQL语句都会有它自己的执行计划历史以及执行计划基准线。
那么某个SQL语句的执行计划是如何进入执行计划历史,乃至执行计划基准线的呢?
有两种方法可以将SQL语句的执行计划纳入到执行计划管理体系中去:
1) 将初始化参数:OPTIMIZER_CAPTURE_PLAN_BASELINES设置为true,则会自动的捕获SQL的执行计划。该参数缺省为false。设置为true以后,当某条SQL语句第一次执行时,该SQL语句的plan history是空的,显然该SQL语句的plan baseline也是空的。那么当该SQL第二次再次执行时,优化器会自动将该SQL语句以及相关的执行计划放入plan history,同时也会放入到plan baseline里。这就构成了最初的plan baseline,也就是说最初进入plan history的执行计划会直接自动进入plan baseline里。那么当你做了某些修改,比如添加了一个索引等,然后第三次执行该同样的SQL语句,则会产生另外一个不同的执行计划,这时新的执行计划会自动进入plan history,但是不会自动进入plan baseline。是否使用该新的执行计划,则要把该新的执行计划与plan baseline里现存的第二次执行SQL时的执行计划进行比较,如果新的执行计划成本更低,则会使用新的执行计划,否则使用plan baseline里的执行计划。
2) 使用dbms_spm包手工处理,这可以让你手工管理SQL plan baseline。使用该包,你可以直接将SQL的执行计划从shared pool里加载到plan baseline里,也可以使用dbms_spm包将已经存在的SQL Tuning Set加载到plan baseline里。同时,dbms_spm可以让你把plan history里的执行计划加入到plan baseline里。反之,你也可以使用该包将plan baseline里的执行计划移出去。
注意,某条SQL语句的plan baseline里的第一个执行计划可以像上面说的通过设置初始化参数来自动加入,但是如果你希望在plan baseline里添加该SQL语句的其他新的执行计划时,则必须使用dbms_spm包手动完成。
那么plan baseline里的执行计划是如何被使用的呢?
Oracle提供了一个初始化参数:OPTIMIZER_USE_PLAN_BASELINES,该参数缺省为true,表示要求优化器考虑使用plan baseline里的执行计划,如果设置为false,则不使用执行计划管理的特性,而又回到了11g之前的状况。
以下描述基于的前提是plan baseline里已经存在了一个SQL的执行计划。
每次优化器解析SQL语句的时候,首先仍然使用11g之前的传统方式产生一个成本最低的执行计划,然后看初始化参数:OPTIMIZER_USE_PLAN_BASELINES是否设置为true,如果为false,则直接返回所生成的执行计划。否则如果为ture,则去plan history里找是否存在相同的执行计划,如果找到了,则再去plan baseline里找是否存在相同的执行计划,如果也找到了,则直接返回该执行计划。如果在plan history里没找到相同的执行计划,则将产生的执行计划加入到plan history里,然后将执行计划与plan baseline里已经存在的执行计划进行比较,看哪个执行计划的成本低就取哪个执行计划。
如果你为某个SQL语句保存了存储大纲,则为了向下兼容,该语句会使用存储大纲。另外,即使你通过设置初始化参数:OPTIMIZER_CAPTURE_PLAN_BASELINES为true来启动自动捕获执行计划到plan baseline里,对于使用存储大纲所生成的执行计划也不会放入plan baseline里。
SQL语句的plan history以及plan baseline所涉及到的表是存放在SQL Management Base (SMB)里的,SMB里同样也存放了SQL Profiles。而SMB是数据字典的一部分,存放在SYSAUX表空间里。SMB所占用的空间会自动定期的删除。
4.2. 执行计划管理的测试
Oracle 11g提供了一个视图:dba_sql_plan_baselines,可以在该视图里查询某条SQL语句相关的plan history以及plan baseline。我们来看下面的例子。
首先创建一个测试表。
SQL> create table t1(skew number, padding varchar2(100));
SQL> insert into t1 select rownum,object_name from dba_objects;
SQL> commit;
SQL> set autotrace traceonly exp stat;
SQL> select * from t1 where skew=200;
SQL> select * from t1 where skew=200;
尽管执行两次,但是这时去查询dba_sql_plan_baselines,试图找到SQL文本为select * from t1 where skew=200的记录时,会发现没有记录,因为optimizer_capture_sql_plan_baselines缺省为false。我们将该参数设置为true以后继续测试。
SQL> alter session set optimizer_capture_sql_plan_baselines=true;
SQL> select * from t1 where skew=200; --全表扫描
SQL> select * from t1 where skew=200; --全表扫描
SQL> select signature,sql_handle,plan_name,origin,enabled,accepted, autopurge
from dba_sql_plan_baselines where sql_text like 'select * from t1 where skew=200';
SIGNATURE SQL_HANDLE PLAN_NAME ORIGIN ENA ACC AUT
---------- ------------------------ ----------------------------- ----------- --- --- ---
1.2376E+19 SYS_SQL_abc0a2c042fa089c SYS_SQL_PLAN_42fa089c844cb98a AUTO-CAPTURE YES YES YES
我们可以看到,文本为“select * from t1 where skew=200”的SQL语句在plan history里产生了一个执行计划。其中,
sql_handle表示SQL语句的句柄;
plan_name则表示该SQL的执行计划的名字;
origin表示该执行计划是如何进入plan history的,该列值为AUTO-CAPTURE则说明是由优化器自动加入的,如果为MANUAL则说明是由DBA手工加入的;
enabled表示是否被启用了,YES表示启用,NO表示禁用。如果某个执行计划为禁用,则优化器根本就不会考虑使用该执行计划;
accepted表示是否接受,也就是是否进入了plan baseline。我们看到这里的accepted为YES,说明该SQL的执行计划进入了plan baseline里;
autopurge表示该执行计划是否为定期自动删除,YES表示是,NO表示否。
我们继续测试,在skew上添加一个索引,从而让原来的SQL不走全表扫描,而改走索引扫描。
SQL> create index idx_t1 on t1(skew);
SQL> exec dbms_stats.gather_table_stats(user,'t1',cascade=>true);
SQL> select * from t1 where skew=200; --索引扫描
SQL> select signature,sql_handle,plan_name,origin,enabled,accepted,fixed,autopurge
from dba_sql_plan_baselines where sql_text like 'select * from t1 where skew=200';
SIGNATURE SQL_HANDLE PLAN_NAME ORIGIN ENA ACC AUT
---------- ------------------------ ----------------------------- ----------- --- --- ---
1.2376E+19 SYS_SQL_abc0a2c042fa089c SYS_SQL_PLAN_42fa089c844cb98a AUTO-CAPTURE YES YES YES
1.2376E+19 SYS_SQL_abc0a2c042fa089c SYS_SQL_PLAN_42fa089cdbd90e8e AUTO-CAPTURE YES NO YES
这时我们可以看到,dba_sql_plan_baselines视图里多了一个执行计划,也就是我们后面那个使用了索引扫描的执行计划。而该执行计划的accepted为NO,说明该计划并没有进入plan baseline里,但是进入了plan history里。
这时,我们可以通过调用dbms_spm包来手工将走索引的执行计划加入到plan baseline里。如下所示,将accepted改为YES。
SQL> dbms_spm.alter_sql_plan_baseline(
sql_handle => 'SYS_SQL_abc0a2c042fa089c',
plan_name => 'SYS_SQL_PLAN_42fa089c844cb98a',
attribute_name => 'ACCEPTED',
attribute_value => 'YES');
然后再次查询dba_sql_plan_baselines视图,可以发现后面的执行计划的accepted变为了YES。
SQL> select signature,sql_handle,plan_name,origin,enabled,accepted,fixed,autopurge
from dba_sql_plan_baselines where sql_text like 'select * from t1 where skew=200';
SIGNATURE SQL_HANDLE PLAN_NAME ORIGIN ENA ACC AUT
---------- ------------------------ ----------------------------- ----------- --- --- ---
1.2376E+19 SYS_SQL_abc0a2c042fa089c SYS_SQL_PLAN_42fa089c844cb98a AUTO-CAPTURE YES YES YES
1.2376E+19 SYS_SQL_abc0a2c042fa089c SYS_SQL_PLAN_42fa089cdbd90e8e AUTO-CAPTURE YES YES YES
如果我们要手工删除plan baseline里的执行计划,则可以调用dbms_spm里的存储过程来实现。
SQL> var cnt number;
SQL> exec :cnt :=
dbms_spm.purge_sql_plan_baseline('SYS_SQL_abc0a2c042fa089c');
删除指定SQL语句的执行计划以后,再去查询dba_sql_plan_baselines就会发现上面测试SQL语句的执行计划不存在了。
从上面的描述可以看出,SQL Plan Management特性的主要作用就是通过引入一个SQL plan baseline,从而保证SQL语句执行计划的稳定,进而保证系统性能的稳定。本质上,它属于11g之前的存储大纲的升级版,而且是自动实现的,不需要人工干预。
5.自动内存管理
Auto Memory Management是Oracle10g提出来的一个新特性,在最新的Oracle11g数据库中又得到了进一步的发展。
通过使用自动内存管理,Oracle数据库中的PGA和SGA内存之间可以互相转换,根据当前的工作负载来自动设定Oracle内存区域中的PGA和SGA的大小。这种间接的内存转换依赖于操作系统的共享内存的释放机制来获得内部实例的调优。目前这种技术可以应用于Linux, Solaris, HPUX, AIX 和Windows等操作系统上。
首先我们来回顾下Oracle10g的自动内存管理特性。在Oracle10g的数据库中,只有SHARED_POOL_SIZE、DB_CACHE_SIZE、LARGE_POOL_SIZE、JAVA_POOL_SIZE、STREAMS_POOL_SIZE五个SGA组件可以被自动调整,其中PGA的最大值由初始化参数PGA_AGGREGATE_TARGET决定,SGA的最大值由初始化参数SGA_TARGET决定。
在Oracle11g数据库中,使用自动内存管理特性不再需要设定参数PGA_AGGREGATE_TARGET和SGA_TARGET,因为这两个参数都已经被修改成自动调优的,除非想指定PGA和SGA的最小值才需要设定这两个参数。
在Oracle11g数据库中,则需要设置一个叫做MEMORY_TARGET的初始化参数,这个参数是指整个Oracle实例所能使用的内存大小,包括PGA和SGA的整体大小,在MEMORY_TARGET的内存大小之内,PGA和SGA所用的内存可以根据当前负载情况自动相互转换。
如果当初始设定的MEMORY_TARGET的内存不够当前数据库使用的时候,Oracle11g还提供了另外一个初始化参数MEMORY_MAX_TARGET,当原始设定的内存不够使用的时候,可以手工来动态 调节MEMORY_TARGET的大小,但是不允许超过MEMORY_MAX_TARGET的值。
下面这张图简单明了的描述出了Oracle11g数据库内存大小的设定参数。
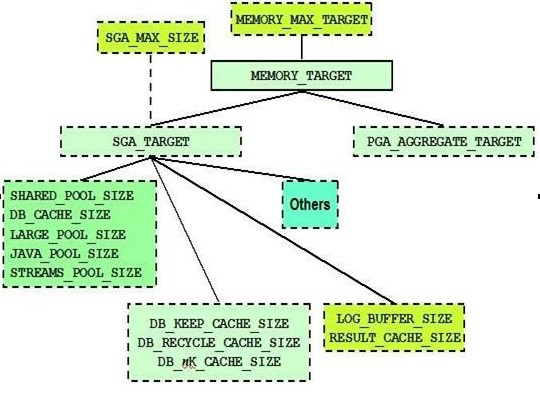
此外,Oracle11g数据库还提供了几个用于监控自动内存管理的视图:
V$MEMORY_DYNAMIC_COMPONENTS:描述当前所有内存组件的状态
V$MEMORY_RESIZE_OPS:循环记录最后800次的SGA大小调整请求
X$KMGSTFR:循环记录最后800次的SGA的转换地址
_MEMORY_MANAGEMENT_TRACING=23:对于所有的内存转换调整行为均记录保存为跟踪文件
6. ASM(自动存储管理)
6.1. ASM Fast Mirror Resync
在10g的ASM中如果因为某些硬件故障(比如接口线,比如光纤卡,比如电源)导致Diskgroup中的某些磁盘无法正常读取,这些磁盘将处于offline状态,在offline之后不久ASM就会把这些磁盘从Diskgroup中删除,并且尝试利用冗余的extent来重新在其它磁盘中构建数据,这是一个比较耗时且耗资源的操作。当我们修复了磁盘,再将它们重新加回磁盘组中,又将是另外一次的数据重整操作。如果我们仅仅是例行的维护硬件,因为磁盘中的数据并没有真正的损坏,我们只是将磁盘取出来过一会儿再加回去,那么这样的两次数据重整操作无疑是没有必要的,在11g中ASM的Fast Mirror Resync功能允许我们设置磁盘的repair时间,在repair时间内ASM将不会尝试在磁盘间重新分配extent。
ALTER DISKGROUP dgroup SET ATTRIBUTE 'DISK_REPAIR_TIME'='3H';
上述命令可以设置当磁盘组dgroup中的磁盘失效和重新有效之间的时间在3小时内的话,ASM就不会重新构建extent,当磁盘重新有效之后,ASM需要做的只是将这3小时内更改的extent重新同步到刚才失效的这些磁盘中就可以了。
6.2. ASM Preferred Mirror Read
我们知道在10g中ASM总是会去读取Primary extent,这样做的目的是为了更好的分散IO,但是在某些环境中,一个ASM磁盘组中的磁盘对于某一个特定的节点来说,有些是Local Disk而有些则是Remote Disk,从Remote Disk中读取数据效率会低于Local Disk,但是在10g中我们无法要求从哪组磁盘中读取数据,在11g中新增的ASM_PREFERRED_READ_FAILURE_GROUPS参数帮助我们完成了这个功能。给每个实例设置优先读取的Failure Group就可以了。
6.3. ASM扩展性的增强
对于外部冗余(External redundancy),ASM可以最大支持到140PB了,而在10g中这个数字仅仅是35TB。
7.Server Result Cache
Cache始终是提升性能的重要技术, 在Oracle 11g中增加了一种Server Result Cache, MySQL的Query Cache是根据SQL的文本来匹配的, 只有Query的文本一模一样时才可以共享,而Oracle的Server Result Cache则只要执行计划一样或部份一样, 并且生命周期一样, 则就可以共享了. 当下面的表数据改变了, Oracle会自动清除这个Cache, 以确保查询结果的正确性. 在以读为主要的系统中, 宣称性能可以提升一倍.
这块内存从SGA中分配, 由RESULT_CACHE_MAX_SIZE控制. Oracle允许你在系统, 会话, 表和语句级(Hint:result_cache)控制是否使用Server Result Cache技术. Oracle提供一个PL/SQL包及相应视图来管理这个Cache区域.
对于同样的操作,如果能在多个process或者session间共享结果,对于性能优化自然是非常有帮助的。从oracle7开始提供的share pool,可以让同样的SQL可以解析一次,执行多次,有效的减少了多个session执行相同SQL语句时的硬解析,如果应用很好的使用了绑定变量,那么共享SQL对于系统整体性能的提升是不言而喻的。
那么,除了能共享SQL和执行计划,还能共享什么?直接共享SQL执行后的结果,使得相同或者部分相同的SQL语句甚至只需要执行一次,以后再次执行时就直接得到结果?没错,Oracle11g的新特性Server Result Cache就能提供这样功能。Oracle在白皮书上宣布,对于读频繁的系统,通过该特性,甚至有可能提升系统性能200%,对于大量报表的数据仓库项目来说,这个特性应该是一个不错的消息。
Server Result Cache通过在SGA中分配一个缓冲区来保存查询结果,Oracle引入了一个新的初始化参数来控制这个cache的大小:result_cache_max_size。可以在system、session、table或者语句级别来设置cache的使用。在语句级可以使用一个新的hint来控制是否缓存查询结果。另外,Oracle还提供了一个新的PL/SQL用来监控和管理Server Result Cache,比如可以清空整个cache的内容或者清空某个查询的结果,也可以生成cache的使用报告等。
既然使用了cache,自然会有cache查找和cache数据清除算法的问题。估计查找还会是通过hash算法,这样还需要引入几个相关的latch。Cache中的数据,也应该是通过LRU或者类似LRU的算法来管理其生命期。
Server Result Cache不仅仅能缓存整个查询的结果,也能缓存查询中某部分操作的结果,比如缓存一次排序的结果,就可以避免再次执行时的排序操作。对于一些比较耗资源的查询操作,缓存结果应该能很好的提升性能。
通过在服务端和客户端引入对于查询结果的缓存机制,Oracle11g或许能极大的提高查询性能。对于一些读比较频繁的系统,比如数据仓库应用,Oracle11g或者更值得期待。
8.提升性能 Consistent Client Cache
Cache始终是提升性能的重要技术. 除了在前面讲的Server Result Cache, Oracle 11g还增加了一种Client Cache. 这是一种在Oracle Client端的缓冲技术, 通过将中间结果或整个表缓冲在客户端, 当客户端发出查询请求时, Oracle可以直接在这个缓冲区中返回记录, 而不需要去和数据库打交道, 可以大大地着少和服务器端的网络来回, 降底服务器上的SQL调用, 根据Benchmarks测试, 对于只读或极少更新的表, 总的消耗时间可以降低500%, 而服务器上的CPU时间可以降低200%.
通过OCI接口,在Client端也可以缓存查询结果。典型的场景就是我们在应用服务器端缓存查询结果,这样在前端执行该查询时,甚至不需要到数据库中去执行该查询。客户端结果缓存在OCI进程中,可以被该进程中的多个session或者线程共享。
要使用这个Cache功能, 也很简单, 首先要使用Oracle 11g的OCI客户端, 如: JDBC-OCI, ODBC, ODB.NET, PHP, Perl等, 无须要去更改现有的程序代码; 其次需要在数据库端指定CLIENT_RESULT_CACHE_SIZE参数来指定这一块Cache的大小, 如果为0则表示禁用. 当该参数大于0时,该特性被启用,同样的,该特性也可以在system、session、table或者语句级来设置。通过在服务端设置参数而不是客户端设置,可以集中的管理该特性,但是也可以在各个客户端单独进行设置,客户端的设置将覆盖服务端的设置。
9.如何使用ADRCI
9.1.关于 ADR Command Interpreter (ADRCI)
一个存放数据库诊断日志、跟踪文件的目录,称作ADR base,对应初始化参数DIAGNOSTIC_DEST,如果设置了ORACLE_BASE环境变量,DIAGNOSTIC_DEST等于ORACLE_BASE,如果没有设置ORACLE_BASE,则等与ORACLE_HOME/log。
关于ADRCI:ADRCI Command-Line Utility 命令行工具,使用该工具查看ADR中的日志和跟踪信息,查看健康报告;还可以将相关错误日志和信息打包成zip文件,以便提供给oracle support分析。在ADRCI工具中可以执行很多命令,另外可以象sqlplus一样执行脚本。
9.2.开始使用ADRCI
9.2.1运行ADRCI,$ORACLE_HOME/bin/adrci
代码:
[root@ractest ~]# su - oracle
[oracle@ractest ~]$ which adrci
~/11g/bin/adrci
[oracle@ractest ~]$ adrci
ADRCI: Release 11.1.0.4.0 - Beta on Thu Jul 12 05:39:29 2007
Copyright (c) 1982, 2006, Oracle. All rights reserved.
ADR base = "/home/oracle"
adrci>>
退出ADRCI,在adrci>>提示符下敲入exit或者quit , 回车大小写敏感:在adrci中命令大小写不敏感
代码:
adrci>>SHOW tracefile
diag/rdbms/orcl/orcl/trace/orcl_ora_20187.trc
diag/rdbms/orcl/orcl/trace/orcl_fbar_11388.
但使用搜索串的时候是敏感的,比如:
SHOW TRACEFILE %mmon%
9.2.2.如何得到帮助信息:
(1)得到adrci中的命令列
代码:
adrci>>help
HELP [topic]
Available Topics:
CREATE REPORT
......
(2)也可以使用adrci –help来得到adrci的命令使用和选项。如:
代码:
[oracle@ractest ~]$ adrci -help
Syntax:
adrci [-help] [script=script_filename]
[exec = "one_command [;one_command;...]"]
Options Description (Default)
-----------------------------------------------------------------
script script file name (None)
help help on the command options (None)
exec exec a set of commands (None)
-----------------------------------------------------------------
(3)如何得到特定命令的帮助信息:
adrci>>HELP SHOW TRACEFILE
Usage: SHOW TRACEFILE [file1 file2 ...] [-rt | -t]
[-i inc1 inc2 ...] [-path path1 path2 ...]
…………….
9.2.3.使用ADRCI进行批处理命令或者脚本
(1) 使用exec选项,用分号将命令隔开
这里文档中有个小问题,文档中写ADRCI EXEC="COMMAND[; COMMAND]...",
只能在windows平台这样写,在unix/linux平台下必须用小写来执行。
代码:
adrci>>show homes;show base; echo '20070712'
ADR Homes:
diag/rdbms/orcl/orcl
ADR base is "/home/oracle"
20070712
adrci>>
adrci>>
adrci>>exit
[oracle@ractest ~]$ adrci exec="show homes;echo '20070712';echo '';show base; "
ADR Homes:
diag/rdbms/orcl/orcl
20070712
ADR base is "/home/oracle"
(2) 使用script选项。adrci SCRIPT=adrci_script.txt
代码:
[oracle@ractest ~]$ cat /tmp/a
show homes;
[oracle@ractest ~]$ adrci script=/tmp/a
[oracle@ractest ~]$ cat /tmp/a
fadsfdsa
[oracle@ractest ~]$ adrci script=/tmp/a
[oracle@ractest ~]$ cat /tmp/a
show trace;
[oracle@ractest ~]$ adrci script=/tmp/a
[oracle@ractest ~]$ cat /tmp/a
SET HOMEPATH /home/oracle/diag/rdbms/orcl/orcl;show trace;
[oracle@ractest ~]$ adrci script=/tmp/a
[oracle@ractest ~]$
9.3.使用ADRCI查看Oracle数据库后台报警日志(alert_sid.log)和跟踪文件
注意:以下大部分命令都需要用Ctrl+C 来结束,并返回到adrci命令行
1.查看完整alert信息:
adrci>>SHOW ALERT
2. 查看最新alert信息:
adrci>> SHOW ALERT –TAIL
查看最新20条alert信息:
adrci>> SHOW ALERT -TAIL 20
只查看600的错误
adrci>>SHOW ALERT -P "MESSAGE_TEXT LIKE '%ORA-600%'"
查看ORA-错误信息,注意这里的参数很好,比较人性化,可以帮助提供错误时间
以下该命令的帮助:
代码:
adrci>>help show alert
Usage: SHOW ALERT [-p <predicate_string>] [-tail [num]] [-v]
[-file <alert_file_name>]
Purpose: Show alert messages.
Options:
[-p <predicate_string>]: The predicate string must be double quoted.
The fields in the predicate are the fields in the alert message's
XML schema. To get the field definitions, use command:
"describe&
3.查看跟踪文件
常用的有:
(1)列出所有跟踪文件: SHOW TRACEFILE
(2)模糊查询跟踪文件,比如某个进程的,注意这里区分大小写 SHOW TRACEFILE
%mmon%
(3)可以指定某个路径 SHOW TRACEFILE %mmon% -PATH /home/steve/temp
(4)象ls那样按时间排序 SHOW TRACEFILE -RT
9.4.其他体验和说明
9.4.1关于在adrci中执行os命令,可以直接在adrci中执行os命令。
所以当发出一个不存在的命令的时候,错误信息也就是系统返回的了。
代码:
adrci>>id
uid=10000(oracle) gid=1001(dba) groups=1001(dba),1002(oinstall)
context=user_u:system_r:unconfined_t
adrci>>host date
DIA-48415: Syntax error found in string [host date] at column [9]
adrci>>host
[oracle@ractest ~]$ exit
exit
adrci>>! -------------这样不行
/bin/bash: -c: line 0: syntax error near unexpected token `newline'
/bin/bash: -c: line 0: `!'
Additional information: 512
adrci>>! date -------------这就可以
Thu Jul 12 06:20:40 CST 2007
--------------------------------------------------------------------
[oracle@ractest ~]$ ksh
$ adrci
ADRCI: Release 11.1.0.4.0 - Beta on Thu Jul 12 06:28:14 2007
Copyright (c) 1982, 2006, Oracle. All rights reserved.
ADR base = "/home/oracle"
adrci>>abc
/bin/bash: abc: command not found
--------明明在ksh下,却返回bash的错误….
Additional information: 32512
adrci>>ksh
$ abc
ksh: abc: not found
9.4.2.确认了在adrci中使用的alert是log.xml,而非alert_orcl.log
对alert进行置空(> file),adrci不受影响;
对log.log进行置空,adrci返回的错误挺吓人的:internal error code,
跟00600一个风格啊。。。应该是某些tag找不到,就报这么狠的错误
代码:
adrci>>show alert
ADR Home = /home/oracle/diag/rdbms/orcl/orcl:
**********************************************************
DIA-48001: internal error code, arguments: [17183],
[0x84B178C], [], [], [], [], [], []
DIA-48154: reached end of file for alert log
DIA-48102: encountered the end-of-file when reading&nb
9.4.3.在adrci中不能使用退格(backspace)怎么办
跟sqlplus一样,有下面几种选择:
用del键;
使用Ctrl+backspace;
使用Ctrl+u删除整行(bash下);
在os命令行下stty erase ^h (可以直接写到oracle的.profile/.bash_profile下面)
9.4.4.另外adrci一个重要的功能是查看Incident和对Incident打包的功能。
10. RMAN
RMAN除了单纯的备份恢复功能,已经被赋予了越来越多的责任,比如创建Standby数据库,比如跨平台传输表空间中的表空间转换。Oracle11g的RMAN倒是没有太多飞跃性的更新。
10.1. 自定义archivelog删除策略
我们知道在11g之前,只有backupset的删除策略可以定义,比如保留多长时间的备份或者保留多少份有效备份,而删除归档日志只有在delete命令中定义删除全部备份完毕的或者删除从哪一个时间点到哪一个时间点的。而在11g中我们已经可以通过configure命令来定义归档日志的删除策略的,比如增加了下面的语法,只有在磁带上备份了2次的归档日志才会被delete命令删除。
CONFIGURE ARCHIVELOG DELETION POLICY TO BACKED UP 2 TIMES TO DEVICE TYPE sbt;
当然,仅仅是增加语法那就只能称为比较无聊的新功能了,除了configure语法之外,现在在11g中通过APPLIED ON STANDBY关键字可以定义只有对于所有的standby站点都已经applied的归档日志才会被删除,或者定义所有被成功传送到standby站点的归档日志就可以被删除。而以前这些都需要DBA自己撰写脚本从数据字典中查询到相关信息然后再通过脚本删除。
10.2. 直接通过网络复制数据库
在11g之前如果要使用duplicate命令来复制一份数据库,那么则需要源数据库,需要在目标机器上的一份有效备份,需要目标数据库,在11g中这一切被大大简化。通过FROM ACTIVE DATABASE关键字,我们只需要有一个源数据库,就可以简单地通过网络在另外一台机器上复制一个相同的数据库了。Oracle会通过一系列Memory Script在内存中recover并且open目标数据库。
另外,在11g之前,duplicate数据库是不会自动复制spfile的,而现在,我们通过下面的语句,就可以让Oracle在复制过程中自动生成一份spfile,并且其中的初始化参数允许额外定义。
DUPLICATE TARGET DATABASE
TO aux_db
FROM ACTIVE DATABASE
SPFILE PARAMETER_VALUE_CONVERT '/u01', '/u02'
SET SGA_MAX_SIZE = '200M'
SET SGA_TARGET = '125M'
SET LOG_FILE_NAME_CONVERT = '/u01','/u02'
DB_FILE_NAME_CONVERT '/u01','/u02';
在11g中使用duplicate复制一个数据库的准备步骤只需要目标数据库(AUXILIARY实例):
a. 通过一个最简单的pfile把实例启动到nomount状态,这个pfile中只需要包含DB_NAME和REMOTE_LOGIN_PASSWORFILE参数即可
b. password文件必须事先建好,而且SYS密码需要跟source数据库中相同,这个通过orapwd可以轻松完成
c. 目录结构需要事先创建好并且具有正确的权限
10.3. 并行备份大文件
现在Oracle数据库中单个数据文件可以最大到128T,而在以前的版本中RMAN的最小备份单位就是datafile,那么对于以后可能出现的这种超大数据文件,RMAN备份就几乎无法操作了。在11g中,通过backup命令中的SECTION SIZE关键字,我们可以对数据文件指定section了,每个section都作为一个独立单位来处理,每个数据文件可以最多指定256个section。
Section的好处在于,
一可以并行备份多个section,提高备份速度;
二可以分多个时间分别备份一个大文件的多个section,时间上化整为零,更具有操作性。
10.4. RMAN Catalog管理性增强
IMPORT CATALOG命令允许我们将一个catalog库中的信息转储到另外一个catalog库,这在以前完全需要手工操作。
推出Virtual Recovery Catalogs概念,这是VPD的实例应用,对于一个集中管理的catalog设置多个用户的虚拟catalog,每个用户只能管理自己的数据,安全性的进一步提高。
11. 两个特性
11.1 归档日志压缩
其中一个是归档日志压缩的功能。通过设置初始化参数 log_archive_dest_n 中 compression 选项,可以对归档文件进行压缩生成。对于网络传输比较吃紧的环境,这个功能会很有价值。
11.2 物理 Standby 可以联机查询
11g 据说也可以对物理的 Standby 进行联机查询,前提条件是激活 Redo Apply 。10g 之前,物理 Standby 都是要么恢复状态,要么 Read Only 状态。如果能够边恢复边查询的话,那么简直是一个比较完美的 IO 分布的技术方案了。SharePlex 之类的产品市场会又小不少。
12 Database和SQL重演
Database Replay是指在产品环境的数据库上捕获所有负载,并可以将之传送至Standby数据库或由备份恢复的测试库上,在测试环境中重演主库的环境,这使得升级或者软件更新可以进行预先的"真实"测试,或者可以通过测试环境完全再现真实环境的负载及运行情况。
在我看来,这是Oracle向后追溯能力的又一增强,在Oracle10g中,我们知道Oracle通过v$session_wait_history视图,ASH特性等,实现将数据库的等待事件向后追溯,现在通过Database Replay特性,Oracle可以将整个数据库的负载捕获、记录并实现Replay,也就是整个数据库的向后追溯能力。
这一特性提供的再现现场能力,极大的丰富了我们发现并解决数据库问题的手段,将为数据库管理带来更多的方便之处。
当然使用这一特性会带来一定的性能负担,Oracle说这一负担在5%左右。
这一特性的简化版本就是SQL Replay,即只捕获SQL负载,通过SQL负载应用再现SQL影响:
Oracle已经有了一系列的Flashback,现在又有了Replay;Flashback可以向后闪回,Replay可以向前推演,Oracle给用户提供的手段越来越多,期待这一特性在正式版中能够有完美的展现。
13. Server Connection Pool
在应用服务器这一层, 我们已经使用Connection Pool了, 可以有效地降低服务器上的连接的数量, 不过还是有不足之处的. 当你的访问量达到一定的规模时, 你会发现一台或几台应用服务器根本就解决不了问题, 在有些世界级的网站中, 应用服务器的数量可能是上千台的, 当每个应用服务器产生4-5个连接时, 你会发现Oracle服务器端便有了4-5千个物理连接. 象PHP程序, 要求每一个Web Server进程都至少有一个连接. 因此Oracle在11g中引入了Database Resident Connection Pool的功能, 这样客户端就可以不管连接池了,由Oracle在服务器端进行连接共享控制.
通过增加一个后台进程CMON(Connection Monitor)来管理连接, 应用发出连接请求时, 实际上是连接到CMON进程, 然后由CMON进程分配一个已经连接好的后台进程, 当客户端连接关闭后, 这个后台进程又交由CMON进程管理. 估计PHP这类的Web程序要有福气了, 不需要去实现连接池的代码了.
14 其他地方
14.1, RAC节点通信协议的改进.
11g中的协议比较智能, 可以根据节点的负荷作出动态的调整, 大大减少节点之间的消息传递量.
14.2, 边恢复边Open的Physical Standby -- Highly Available Reader Farms
这个功能肯定很受大公司的欢迎, 因为以前的Data Guard不能做到这样, 当Open时同主库的延迟会越来越大, 而在11g中则不存在这样的延迟, 因此可以建几个这样的Standby来分担读操作, 估计Shareplex或Realsync这样的软件市场要受到一定的影响了, 我对Log的研究也变得越来越没有价值了.
14.3, 面向OLTP的压缩表
在新的压缩技术中, Oracle可以去掉了压缩表的诸多限制, 使之可以适合OLTP的环境. 这样Oracle可以充分利用闲的CPU的资源(CPU越来越历害了), 以降低IO的消耗(IO的提高还是很慢).